ACID Transactions
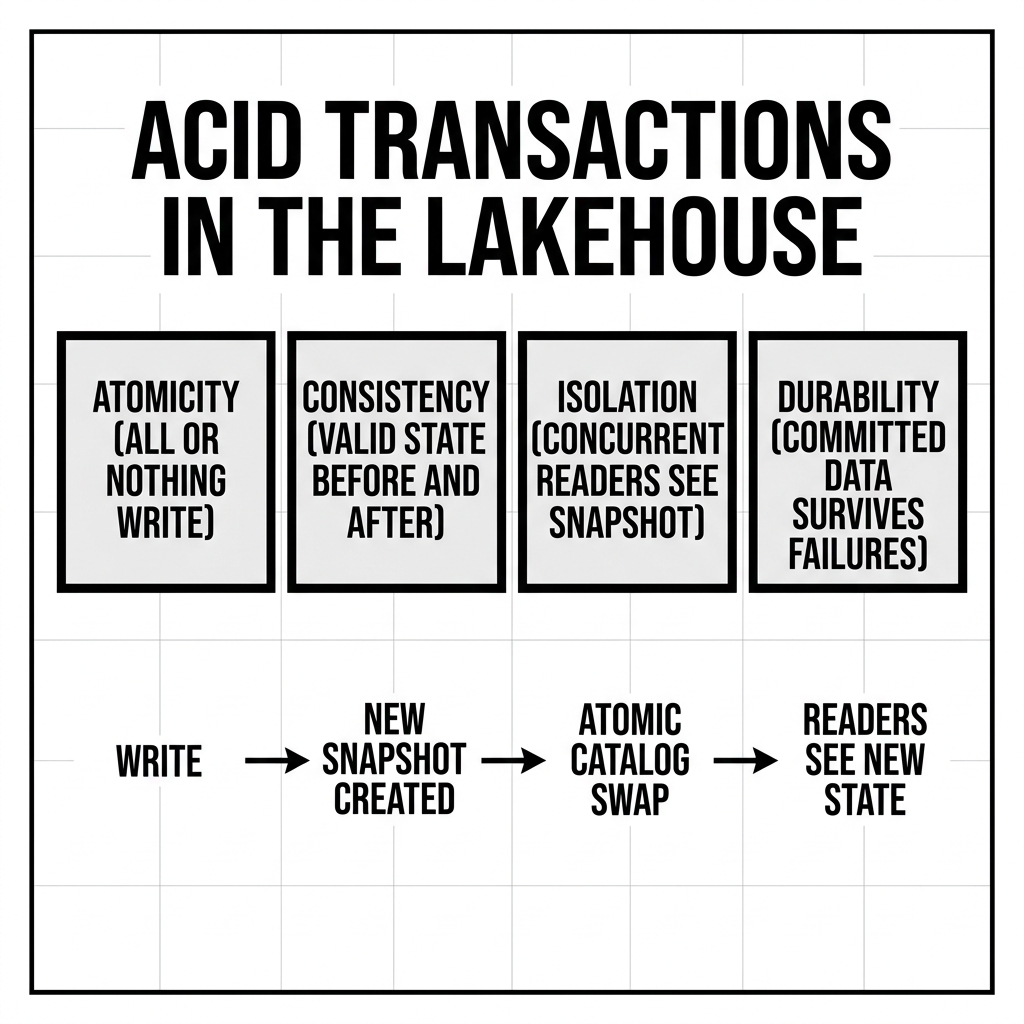
ACID is the foundational set of properties that define the correctness guarantees a data storage system must provide for transactions to be considered reliable. The acronym stands for Atomicity, Consistency, Isolation, and Durability. First formally described by Andreas Reuter and Theo Härder in 1983, these four properties emerged from decades of hard experience with the failure modes that occur when database systems handle concurrent reads and writes without sufficient safety guarantees.
For the first generation of cloud data lakes, ACID was largely absent. Data was written to cloud object storage as collections of Parquet or CSV files, with no transaction management, no concurrency control, and no consistent state guarantees. The consequences were predictable and severe: partial writes left tables in corrupted states, concurrent ETL jobs produced silently incorrect results, and there was no reliable mechanism to undo a catastrophic mistake. The emergence of Open Table Formats — Apache Iceberg, Delta Lake, Apache Hudi — was driven primarily by the need to restore ACID guarantees to the data lake. Understanding exactly how each of the four ACID properties is implemented in a distributed object storage environment is essential for any data engineer or architect working in the modern lakehouse.
Atomicity: All or Nothing, with Zero Partial States
Atomicity is the property that guarantees a transaction is treated as a single, indivisible unit of work. Either the transaction completes in its entirety and its effects are permanently visible, or it fails completely and no trace of its partial effects is visible. There is no intermediate state.
The Challenge of Atomicity on Object Storage
In a traditional relational database running on local disk, atomicity is implemented by writing changes to the Write-Ahead Log (WAL) before applying them to data pages, and marking the transaction as committed only after all WAL entries are safely on disk. If the system crashes before the commit marker is written, the WAL entries are discarded during recovery. If it crashes after, the WAL entries are applied.
Cloud object storage presents a more challenging environment. Writing 1,000 Parquet files to Amazon S3 is not atomic at the storage layer. S3 makes each individual object PUT request atomic, but there is no native mechanism to make 1,000 separate PUT requests atomically all-or-nothing. If a Spark cluster crashes after writing 600 of 1,000 files, 600 files exist in the bucket. The bucket has no concept of “this is an incomplete transaction” — the files are simply present.
How Open Table Formats Achieve Atomicity
Open Table Formats solve the atomicity problem by separating the write operation into two phases: the physical write phase and the logical commit phase.
Phase 1 — Physical Write: The compute engine writes all output Parquet files to the object storage bucket. These files are complete and readable, but they are not yet registered with the table’s metadata. From the perspective of any reader consulting the table’s catalog or metadata, these files do not exist.
Phase 2 — Atomic Commit: When all physical files have been successfully written, the engine performs a single atomic commit operation by updating the table’s metadata. In Delta Lake, this is the conditional creation of a new JSON commit file. In Iceberg, this is a compare-and-swap on the catalog’s metadata pointer. In Hudi, this is the transition of a Timeline Instant from INFLIGHT to COMPLETED.
This single metadata update is the transaction’s commit. Because it is a single operation, it is inherently all-or-nothing. Either the metadata update succeeds — at which point all the physical files become atomically visible as a unit — or it fails — at which point the physical files remain unregistered and invisible. A reader that checks the metadata at any point during Phase 1 sees no change. A reader that checks after Phase 2 sees the complete set of new files instantaneously. The partial state (600 of 1,000 files written) is never visible to readers. If the job crashes during Phase 1, the written Parquet files become orphans and will be cleaned up by the removeOrphanFiles maintenance job.
Atomic Commit Primitives on Object Storage
The specific mechanism for achieving the atomic metadata update varies by format and by object storage provider.
Delta Lake relies on the “put-if-absent” semantics of object storage. Creating a new sequential commit file (e.g., 00000000000000000042.json) succeeds only if that filename does not yet exist. This is a race-free operation supported by S3, GCS, and Azure Blob Storage. The first writer to create 42.json wins; any concurrent writer’s attempt to create the same filename is rejected.
Apache Iceberg relies on the catalog service’s compare-and-swap operation. The catalog holds a pointer to the current metadata file path. A writer presents its new metadata file path along with the expected current metadata file path as a precondition. The catalog atomically checks: if the current pointer matches the expectation, swap to the new path; otherwise, reject. This is how Iceberg REST Catalog implementations, Hive Metastore lock-based commits, and DynamoDB-backed catalogs all enforce atomic commits.
Consistency: Schema and Integrity at Every State
Consistency guarantees that a transaction can only take the database from one valid state to another valid state. Intermediate states that violate defined integrity constraints are never permitted to persist.
What Consistency Means in the Lakehouse
In a traditional RDBMS, consistency is enforced through foreign key constraints, unique indexes, check constraints, and triggers. If an INSERT would violate a foreign key constraint, the entire transaction is aborted before any changes are committed.
In the data lakehouse context, consistency takes a different but equally important form. It means:
Schema enforcement: A table’s schema defines the expected data types and nullability for every column. If a write job attempts to insert a DataFrame that contains a column of type DOUBLE into a table that expects STRING, the write must be rejected before any data is written. Delta Lake enforces schema validation before committing any data. Iceberg enforces schema validation at the write API level. This prevents silent schema drift where a pipeline change accidentally corrupts a table’s type system.
Partition specification consistency: Data files must be written with partition values that match the table’s current partition specification. Writing files to the wrong partition path — a common failure mode in legacy Hive-based pipelines — is rejected by the format’s metadata layer.
Referential metadata consistency: The metadata hierarchy (Metadata JSON → Manifest List → Manifest Files → Data Files in Iceberg; Commit Log entries → Data Files in Delta) must always be internally consistent. Every data file referenced by the metadata must actually exist in object storage. Every metadata pointer must resolve to a valid target. Open Table Formats maintain this referential consistency by constructing metadata in a bottom-up order: data files are written first, manifests referencing those files are written second, and the commit that registers the manifests is performed last.
Cross-Table Consistency
A more advanced consistency challenge in lakehouse architectures is cross-table consistency: ensuring that a single logical business operation that updates multiple tables leaves all tables in a mutually consistent state. For example, a payment processing pipeline might need to atomically increment a payments table and decrement an account_balances table as part of a single transaction.
Standard Open Table Format single-table transactions cannot guarantee cross-table consistency natively. This requires either a catalog-level multi-table transaction mechanism (supported in some REST Catalog implementations and in Apache Spark’s Multi-Table Transaction API with Iceberg) or an application-level saga pattern with compensating transactions for failure recovery. Cross-table atomicity is an active area of development in the lakehouse ecosystem and remains a meaningful gap relative to traditional RDBMS capabilities.
Isolation: Concurrent Access without Interference
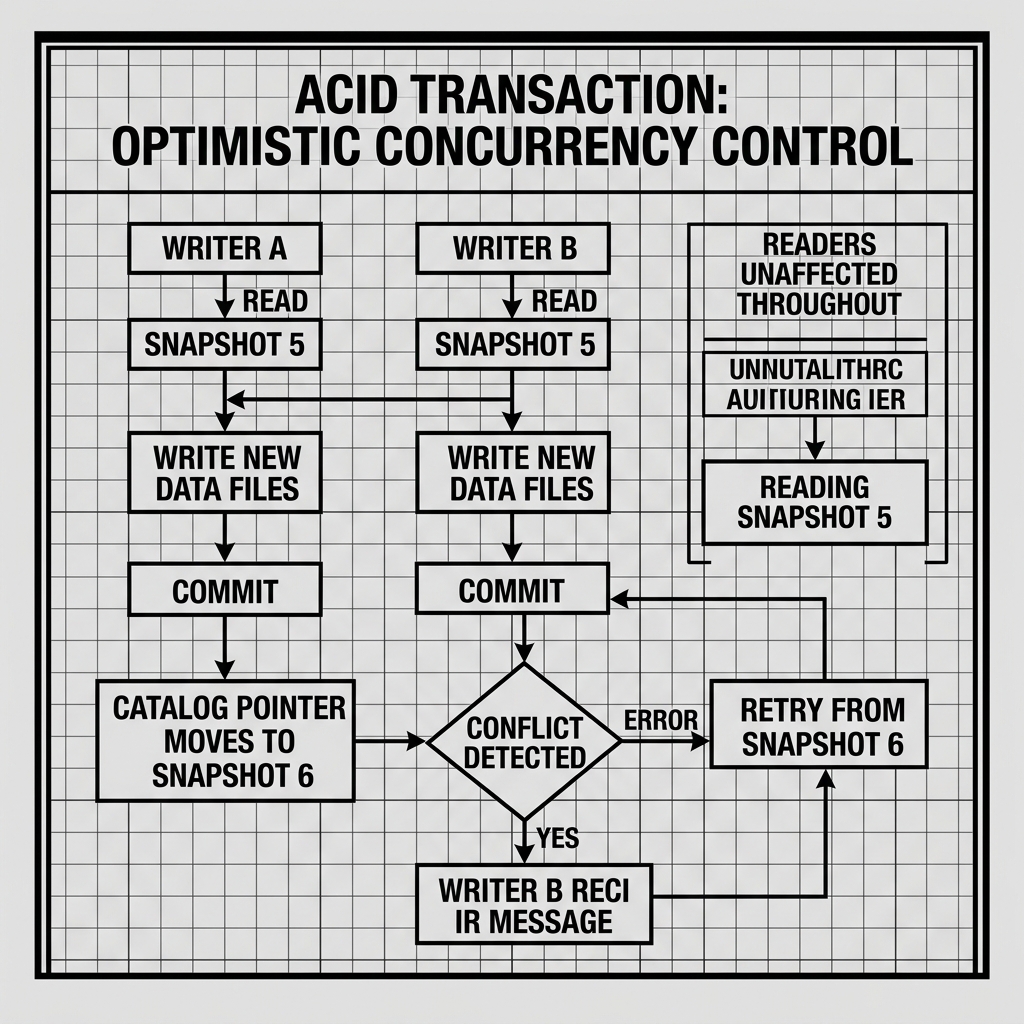
Isolation guarantees that concurrent transactions do not interfere with each other. Specifically, a transaction executing in isolation should produce the same result as if it were the only transaction running in the entire system. In practice, full isolation (Serializable Isolation) is computationally expensive. Modern lakehouses typically implement Snapshot Isolation, a weaker but highly practical isolation level.
Snapshot Isolation and MVCC
Snapshot Isolation is implemented through Multi-Version Concurrency Control (MVCC). In an MVCC system, when a transaction begins, it acquires a “snapshot” of the database state — specifically, a pointer to the most recent committed version of the table’s metadata at the moment the transaction started. All reads performed by that transaction are served from this snapshot, regardless of any concurrent writes that happen during the transaction’s execution.
In the lakehouse context:
When a Trino query begins at timestamp T1 and reads from an Iceberg table, Iceberg notes the most recent committed Snapshot ID at T1. Every file the query reads is served from that snapshot’s file set. If a concurrent Spark job commits a new Iceberg Snapshot at T2 (while the Trino query is still running), the Trino query is completely unaffected — it continues to read from the T1 snapshot. It does not see the Spark job’s new files, and the Spark job’s commit does not block or interrupt the Trino query in any way.
This is the lakehouse’s implementation of readers-never-block-writers and writers-never-block-readers. There are no read locks, no write locks, and no blocking. Concurrent reads and writes proceed in complete isolation from each other, each working against their own snapshot of the table’s state.
Anomalies Permitted by Snapshot Isolation
Snapshot Isolation is not perfectly equivalent to Serializable Isolation. It permits certain anomalies that full serialization would prevent. The most relevant for lakehouse workloads is the Write Skew Anomaly.
Write Skew occurs when two concurrent transactions each read overlapping data, make decisions based on that read, and then write to different parts of the table in ways that are individually valid but collectively produce an inconsistent result. For example: two Spark jobs each check if a patient’s total medication dose today exceeds 100mg. Both read 80mg. Both conclude that adding 30mg is safe. Both commit their 30mg additions. The table now shows 110mg for the day, violating the constraint that total daily dose must not exceed 100mg — but Snapshot Isolation didn’t prevent it because neither write directly conflicted with the other.
For most analytical workloads (insert-only streaming pipelines, batch ETL, report generation), Write Skew is not a meaningful concern. For operational data patterns where multiple concurrent writers are making constraint-checked mutations to the same records, Snapshot Isolation’s anomaly window must be accounted for in the application design.
Serializable Isolation in the Lakehouse
Some Open Table Format implementations provide an upgrade path to Serializable Isolation for critical write paths. Apache Iceberg’s conflict detection model can be configured to detect whether the files a transaction read are also the files modified by a concurrent transaction. If a conflict is detected (a form of read/write conflict detection), the conflicting transaction is rejected and must retry. This provides a practical approximation of Serializable Isolation for common write patterns, preventing the most dangerous classes of write skew without full 2-phase locking overhead.
Durability: Committed Means Permanently Committed
Durability guarantees that once a transaction is committed, its effects are permanent and will survive any subsequent system failure, including hardware failures, network failures, and process crashes.
How Object Storage Delivers Durability
Cloud object storage provides exceptional intrinsic durability that far exceeds what most on-premises database systems achieve. Amazon S3, for example, is designed for 99.999999999% (eleven nines) object durability — achieved through synchronous, automatic replication of every object across multiple physical storage devices and multiple Availability Zones within a region. Once an S3 PUT request returns a success response, the object is durably stored across multiple independent physical locations.
This means that once an Open Table Format’s metadata commit succeeds (the Delta JSON commit file is created, or the Iceberg catalog pointer is swapped), the transaction’s durability is guaranteed by the underlying object storage infrastructure without any additional application-layer durability mechanism. The committed metadata, and the data files it references, are instantly durably replicated.
Durability and Write-After-Commit Consistency
A nuance of cloud object storage durability is the distinction between write durability and read-after-write consistency. Amazon S3 (since 2020) provides strong read-after-write consistency: immediately after a successful PUT operation, any subsequent GET for the same key will return the newly written object. This means there is no window after a transaction commit where a reader might see a stale version of the metadata.
Prior to S3’s strong consistency guarantee (before December 2020), Open Table Format implementations had to implement additional workarounds (such as using DynamoDB-based metadata pointers with strong consistency guarantees) to ensure that commits were immediately visible to all readers without a propagation delay. Modern lakehouse deployments on S3 no longer require these workarounds.
Durability Limitations: Retention Windows
The one meaningful limitation of durability in a lakehouse context is the interaction between durability and retention windows. While committed data is permanently durable on object storage, the VACUUM (Delta) or ExpireSnapshots (Iceberg) maintenance operations physically delete old data files to control storage costs. Once these files are deleted, they are gone permanently — they cannot be recovered through Time Travel.
This means durability in the lakehouse has a practical time bound defined by the retention window. Data committed more than 7 days ago (if VACUUM runs with a 7-day retention) is durably committed but may have been garbage collected. The transaction is still recorded in the metadata log (which is not subject to VACUUM), but the underlying physical files are gone. This is a subtle but important distinction: the transaction log’s record of what happened is durable forever; the physical data files needed to actually read the historical state are only durable within the retention window.
The ACID Contract in Production Lakehouse Deployments
In practice, achieving full ACID guarantees in a production lakehouse deployment requires careful attention to several operational factors:
Single-writer discipline: While all formats support multi-writer concurrency through OCC, the conflict retry logic adds latency. High-contention tables where many writers frequently target the same data benefit from architectural patterns that reduce write concurrency (e.g., funnel writes through a single stream writer and use read-only query engines for all reads).
Catalog reliability: The atomicity of Iceberg’s commit depends on the catalog’s compare-and-swap being reliable. If the catalog service (e.g., Hive Metastore) experiences an outage or data corruption, Iceberg’s atomicity guarantee degrades. Using a highly available, strongly consistent catalog service (like an Iceberg REST Catalog backed by a distributed database) is essential for production durability.
Maintenance job scheduling: The interaction between durability (data is committed) and retention (data is garbage collected) must be explicitly managed. Retention windows must be set to accommodate all Time Travel use cases, and VACUUM/ExpireSnapshots jobs must be scheduled during maintenance windows rather than running continuously in production.
Conclusion
ACID transactions in the data lakehouse represent the culmination of decades of database research, applied creatively to the unique constraints of distributed cloud object storage. Atomicity is achieved through two-phase physical write plus single-step metadata commit. Consistency is enforced through schema validation and referential metadata integrity. Isolation is provided by Snapshot Isolation via MVCC, with optional upgrade paths toward Serializable Isolation for critical write paths. Durability is inherited from cloud object storage’s intrinsic replication guarantees, bounded by the retention window policies that govern garbage collection. Together, these four properties transform a collection of raw Parquet files on S3 into a production-grade, enterprise-reliable data asset that data engineers and analysts can trust with their most critical business data.
Visual Architecture