Amazon Athena
Amazon Athena is a serverless, interactive query service provided by Amazon Web Services (AWS) that allows users to analyze data directly in Amazon Simple Storage Service (S3) using standard SQL. Athena eliminates the need for complex ETL (Extract, Transform, Load) pipelines and infrastructure management, enabling data analysts and engineers to run immediate, ad-hoc queries against vast amounts of raw or structured data. Within the context of the open data lakehouse, Athena serves as a critical compute layer for exploring open table formats like Apache Iceberg.
Core Definition
Before the advent of serverless query engines, analyzing data stored in a data lake required provisioning and managing clusters. Tools like Apache Hadoop or Apache Spark required dedicated EC2 instances, configuration tuning, and continuous monitoring. This presented a high barrier to entry for analysts who simply wanted to run a quick SQL query against a log file.
Amazon Athena was launched in 2016 to solve this problem. It is built on top of the Presto distributed SQL engine (and more recently, Trino), but it is offered as a completely serverless, managed service. There are no clusters to provision, no software to install, and no infrastructure to manage. Users simply point Athena at their data in S3, define the schema, and start querying.
The pricing model of Athena fundamentally changed data lake analytics. Users are charged strictly based on the amount of data scanned per query (e.g., $5 per terabyte of data scanned). This “pay-per-query” model incentivizes data engineers to optimize their storage layouts using columnar formats like Parquet and partitioning strategies to minimize data scanned, thereby reducing costs.
Architecture and Components
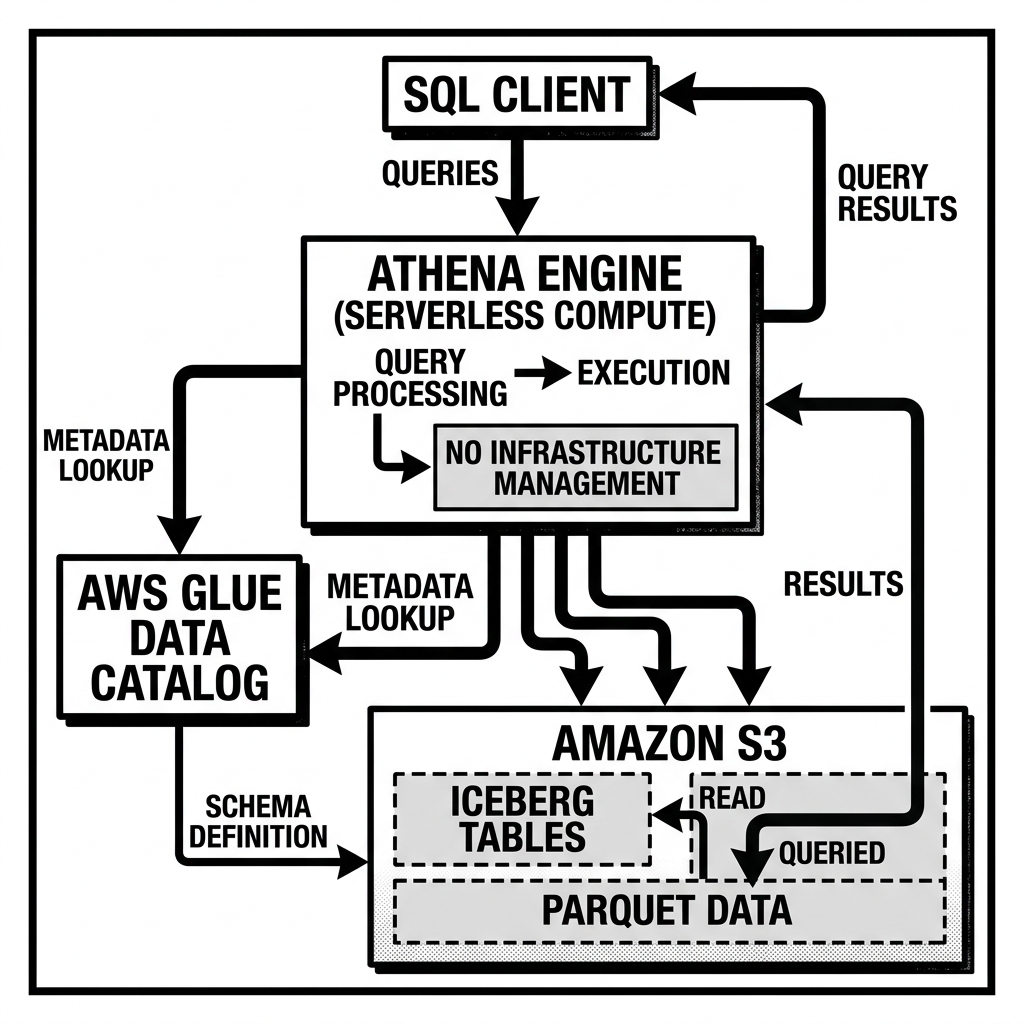
Because Athena is fully managed by AWS, its internal architecture is abstracted away from the user. However, conceptually, it operates as a massively parallel processing (MPP) engine tightly integrated with the AWS ecosystem.
When a user submits a query via the AWS Management Console, the Athena JDBC/ODBC driver, or the Athena API, the service transparently provisions the necessary compute resources from a massive, multi-tenant pool maintained by AWS. The query is parsed, optimized, and distributed across thousands of compute nodes. These nodes read the target data directly from S3, perform the necessary aggregations or joins in memory, and return the results. Once the query completes, the compute resources are immediately released back to the pool.
Athena relies heavily on the AWS Glue Data Catalog. While Athena can create its own internal tables, best practices dictate using the Glue Data Catalog as the central repository for structural and operational metadata. The Glue catalog acts as a unified metastore, allowing services like Athena, Amazon EMR, and Amazon Redshift Spectrum to share a consistent view of the data lake.
Integration with Open Table Formats
Early versions of Athena primarily queried raw CSV, JSON, and Parquet files stored in S3 directories (often mimicking Apache Hive partitioning schemes). However, querying raw files at petabyte scale often led to slow performance due to S3 directory listing bottlenecks and the lack of ACID transaction support.
To address this, Athena introduced native support for Apache Iceberg. When querying an Iceberg table, Athena bypasses traditional directory listing. Instead, it reads the Iceberg metadata tree (the metadata.json, manifest lists, and manifest files). This allows Athena to perform highly efficient file skipping based on column-level statistics before executing the query.
Furthermore, Athena supports writing to Iceberg tables. Users can execute INSERT, UPDATE, DELETE, and MERGE statements directly from the Athena console. Athena handles the atomic commits to the Iceberg metadata, ensuring strong consistency. This capability transforms S3 from a static data lake into a dynamic, transactional lakehouse without requiring the user to deploy a single server.
Federated Query Capabilities
While Athena is best known for querying S3, it has expanded its capabilities through Amazon Athena Federated Query. This feature allows users to run SQL queries across data stored in relational, non-relational, object, and custom data sources.
By utilizing AWS Lambda functions known as Data Source Connectors, Athena can query data sitting in Amazon DynamoDB, Amazon RDS (PostgreSQL/MySQL), Amazon Redshift, and even external clouds. For example, an analyst can write a single SQL query in Athena that joins customer demographic data in S3 (Iceberg) with live operational order data in an Amazon Aurora database. The Athena engine pushes down predicates to the Lambda connectors, minimizing data transfer, and executes the final join in its serverless compute pool.
Summary and Tradeoffs
Amazon Athena is a foundational service for any AWS-based data lakehouse. Its serverless nature, pay-per-query pricing, and deep integration with Apache Iceberg and the AWS Glue Data Catalog make it an exceptionally powerful tool for data exploration, ad-hoc analysis, and building serverless data pipelines.
The primary tradeoff with Athena is the lack of predictable performance and resource isolation. Because Athena utilizes a shared, multi-tenant compute pool, query performance can occasionally fluctuate based on overall AWS region load. Furthermore, Athena has strict service quotas (e.g., maximum query timeout limits, concurrent query limits) that prevent it from being used for massive, multi-hour batch ETL transformations that require complex shuffle operations and fault tolerance. For those heavy-lifting workloads, organizations typically turn to Amazon EMR (running Apache Spark).
Despite these limitations, Athena remains the quickest and easiest way to democratize access to the data lakehouse, providing a standard SQL interface to petabytes of data without any operational overhead.
Visual Architecture