Amazon S3
Amazon Simple Storage Service (Amazon S3) is an object storage service provided by Amazon Web Services (AWS) that offers industry-leading scalability, data availability, security, and performance. Launched in 2006 as one of the first AWS services, S3 fundamentally changed how organizations manage data. In the context of big data analytics, S3 is the foundational storage layer for the vast majority of modern cloud-native data lakes and open data lakehouses.
Core Characteristics
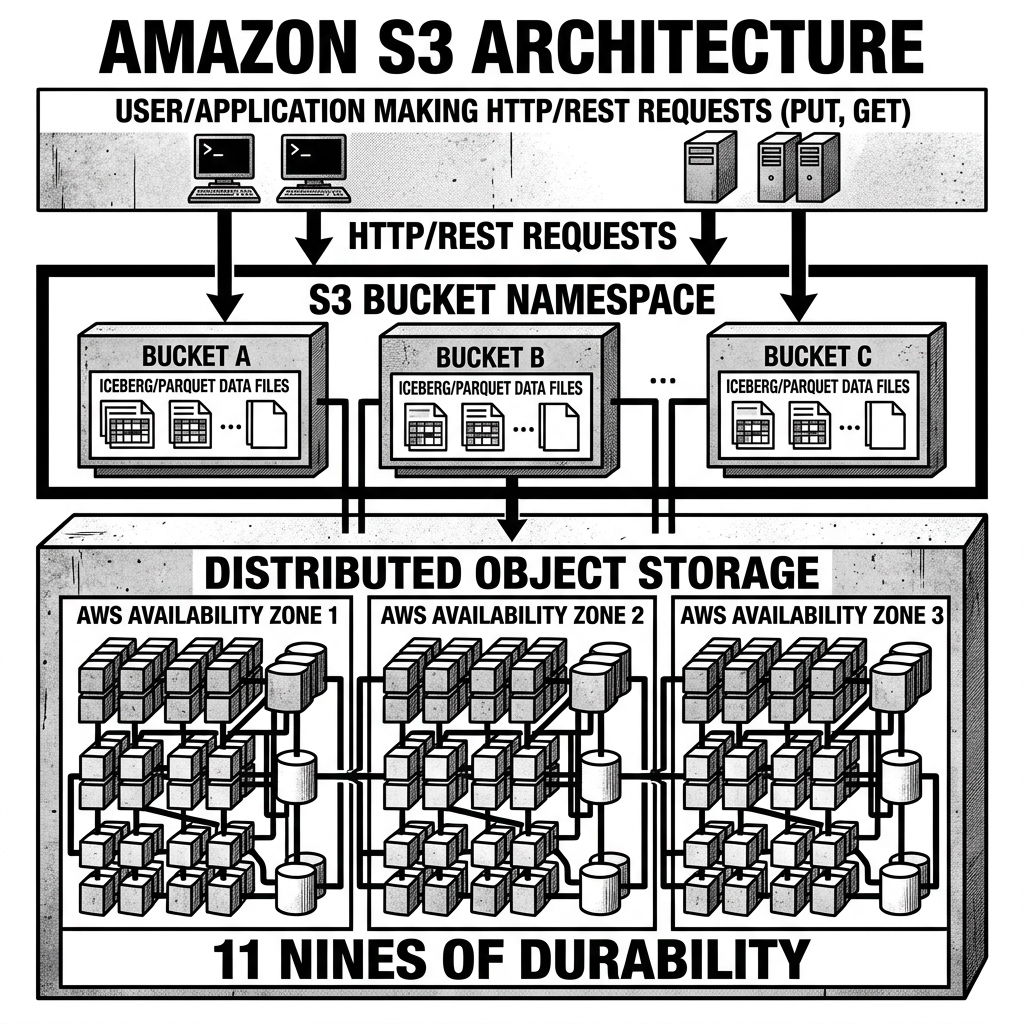
Unlike traditional file systems that organize data into a hierarchical tree of directories and files, or block storage that manages data as raw sectors on a disk, S3 is an object store. Data in S3 is stored as discrete “objects” within containers called “buckets.”
Each object consists of:
- Data: The actual file contents (e.g., a massive Parquet file).
- Metadata: A set of name-value pairs that describe the object (e.g., content type, custom tags).
- Key: The unique identifier (name) of the object within the bucket.
Because S3 uses a flat namespace rather than a directory tree, it scales infinitely. You can store millions or billions of objects in a single bucket without the severe performance degradation that traditional file systems experience when navigating massive directory structures.
Durability and Availability
The primary reason S3 became the default storage for data lakes is its reliability. AWS designed S3 to provide 99.999999999% (11 nines) of durability over a given year.
When an object is written to a standard S3 bucket, AWS automatically and synchronously replicates that data across multiple physical data centers (called Availability Zones) within the selected AWS Region. This means that even if an entire data center experiences a catastrophic failure, the data remains safe and accessible. This built-in fault tolerance completely eliminated the need for data engineering teams to manage complex and expensive Hadoop Distributed File System (HDFS) replication strategies.
S3 in the Data Lakehouse
The architecture of the open data lakehouse relies entirely on the decoupling of compute and storage. S3 provides the ultimate decoupled storage layer.
Data is written to S3 in open table formats like Apache Iceberg, Apache Hudi, or Delta Lake. Because the data resides in S3, it is not “locked” into any specific compute engine. A single Parquet file stored in S3 can be simultaneously queried by Amazon Athena, transformed by an Apache Spark job running on Amazon EMR, and ingested into a Snowflake data warehouse via external stages.
To manage massive analytics workloads, S3 provides features critical for query performance:
- High Throughput: S3 is engineered to support massive parallel access. A distributed compute engine (like Trino) can spin up thousands of worker nodes, all simultaneously issuing
GETrequests to S3, achieving aggregate read speeds of hundreds of gigabytes per second. - Byte-Range Fetches: S3 supports HTTP Range Requests. If an engine only needs to read the metadata footer of a 1GB Parquet file, it can request only the last 64KB of the object. This drastically reduces network transfer costs and query latency.
Storage Tiers and Lifecycle Management
To optimize costs, S3 offers multiple storage classes designed for different data access patterns:
- S3 Standard: For frequently accessed data (e.g., active Iceberg tables).
- S3 Standard-Infrequent Access (S3 Standard-IA): For data accessed less frequently but requiring rapid access when needed (e.g., last year’s sales data).
- S3 Glacier / Glacier Deep Archive: For long-term archiving where retrieval times of minutes or hours are acceptable (e.g., raw audit logs kept for regulatory compliance).
Data engineers use S3 Lifecycle Policies to automatically transition data between these tiers. For example, a policy might dictate that log data is written to S3 Standard, moved to Standard-IA after 30 days, and archived to Glacier after 365 days, dramatically reducing total storage costs without manual intervention.
Summary and Tradeoffs
Amazon S3 is the bedrock of the modern data stack. Its infinite scalability, unparalleled durability, and separation from the compute layer make it the ideal home for the open data lakehouse.
The primary tradeoff with S3 (and all object storage) compared to local block storage (like NVMe SSDs) is network latency. Because every read and write operation occurs over HTTP, individual operations take milliseconds rather than microseconds. Furthermore, S3 objects are generally immutable; you cannot update a single row in an existing file. This immutability requires the use of sophisticated software layers like Apache Iceberg to manage atomic transactions, handle data mutations by writing new files, and provide the ACID guarantees that S3 natively lacks.
Visual Architecture