Apache Doris
Apache Doris is a modern, open-source Massively Parallel Processing (MPP) analytical database designed for blazing-fast, real-time data warehousing. Originally developed by Baidu to handle massive scale advertising and analytics workloads, Doris has become a top-level Apache project renowned for its extreme performance, simplified architecture, and unified ability to handle both high-concurrency point queries and massive-scale interactive analytics. In the context of the open data lakehouse, Doris serves as an exceptionally fast query engine for federated data exploration.
Core Definition
The analytical database landscape is often divided between systems that excel at massive batch processing (like Apache Spark) and systems optimized for sub-second, highly concurrent queries. Apache Doris bridges this gap. It was specifically engineered to deliver interactive analytics—where query responses are expected in milliseconds—on massive, continuously updating datasets.
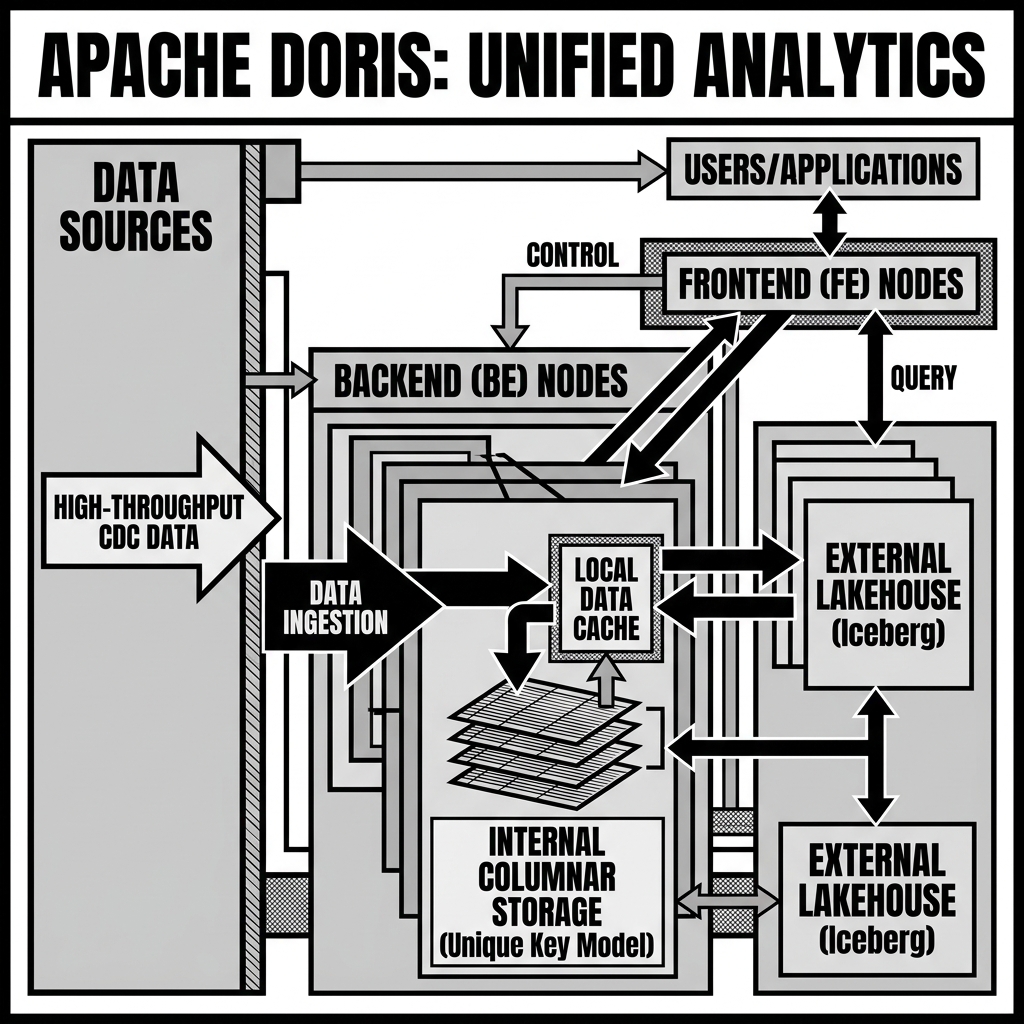
What sets Apache Doris apart from many of its predecessors is its relentless focus on architectural simplicity and operational ease. Older Hadoop-ecosystem databases required deploying and managing a complex menagerie of components: ZooKeeper for coordination, HDFS for storage, and multiple master and worker roles. In contrast, Apache Doris requires zero external dependencies. The entire system is self-contained within two straightforward node types.
This simplicity does not come at the cost of performance. Doris features a fully vectorized execution engine written in C++, which processes data in batches using SIMD (Single Instruction, Multiple Data) instructions to maximize CPU cache utilization. It is backed by an advanced Cost-Based Optimizer (CBO) that intelligently plans query execution, leveraging a wide array of specialized indices to minimize data scanning.
Architecture and Components
The architecture of an Apache Doris cluster is remarkably elegant, consisting of only Frontend (FE) nodes and Backend (BE) nodes.
The Frontend (FE) nodes manage the metadata, coordinate cluster operations, and handle client connections. When a user submits a SQL query, the FE is responsible for parsing, analyzing, and optimizing the query. The FE’s Cost-Based Optimizer evaluates statistical metadata to determine the most efficient distributed execution plan. FE nodes also manage their own high availability; deploying multiple FE nodes establishes a quorum, ensuring continuous operation even if a node fails.
The Backend (BE) nodes do the heavy lifting. They are responsible for both storing data (when Doris is used as an internal data warehouse) and executing the query plans assigned by the FE. The BE nodes execute the vectorized computations in memory. Because Doris uses a shared-nothing architecture, scaling the compute and storage capacity of the cluster is as simple as adding more BE nodes; the cluster automatically rebalances the data and workload without manual intervention.
To achieve its high performance, Doris implements a unique storage engine based on a columnar format. The storage engine supports highly efficient data ingestion, allowing millions of rows to be written per second without impacting read performance. It also utilizes a sophisticated indexing system, including ZoneMaps (min/max indices), Bloom filters, and inverted indices, enabling the engine to aggressively skip irrelevant data blocks during query execution.
Data Lakehouse Federation
While Doris is incredibly powerful as a standalone data warehouse, its role has expanded significantly with the rise of the data lakehouse architecture. The Doris community has heavily invested in its Multi-Catalog federation capabilities.
Through the Multi-Catalog feature, Doris can seamlessly connect to external data sources without requiring data to be ingested or copied into its internal storage. Users can map an entire Apache Iceberg, Delta Lake, or Apache Hudi catalog directly into Doris.
When a query targets an external Iceberg table on Amazon S3, the Doris FE retrieves the Iceberg metadata to perform partition pruning and file skipping. The query fragments are then dispatched to the BE nodes, which read the underlying Parquet or ORC files directly from object storage.
To bridge the performance gap between local storage and remote object storage, Doris employs an aggressive Data Cache mechanism. When BE nodes read blocks of data from an external data lake, they can cache those blocks locally on NVMe SSDs or in memory. Subsequent queries hitting the same data will be served directly from the local cache, delivering performance that rivals querying internal Doris tables.
Real-Time Updates and Materialized Views
One of the most challenging aspects of data engineering is handling real-time, record-level updates and deletes. Traditional data warehouses often struggle with the “Merge-on-Read” penalty associated with updating analytical data. Doris addresses this with a specialized Unique Key storage model. This model ensures that when duplicate records are ingested (e.g., an updated status for an existing order), Doris seamlessly handles the deduplication and presents the most recent state to the user, making it ideal for ingesting Change Data Capture (CDC) streams from operational databases like MySQL or PostgreSQL via tools like Apache Flink.
Furthermore, Doris provides robust support for Materialized Views. Unlike simple cached queries, Doris materialized views are updated asynchronously or synchronously as new data arrives. The query optimizer is “materialized view aware.” If a user writes a complex aggregate query against a massive base table, the optimizer can automatically transparently rewrite the query to utilize a pre-aggregated materialized view if one exists, resulting in instantaneous query responses.
Summary and Tradeoffs
Apache Doris represents the state-of-the-art in modern MPP databases. By combining an ultra-fast vectorized C++ execution engine with a radically simplified, dependency-free architecture, Doris provides a compelling solution for organizations that need real-time analytics without the operational nightmare of managing legacy Hadoop-based systems. Its seamless integration with open table formats like Apache Iceberg makes it a top-tier query engine for the modern data lakehouse.
The primary tradeoff with Apache Doris is related to its internal storage model. While the system is exceptional at handling high-concurrency analytics and real-time CDC ingestion, managing a massive, petabyte-scale stateful cluster requires careful capacity planning. Unlike pure decoupled compute engines (like Trino), which simply scale up and down statelessly over an external data lake, managing Doris as an internal data warehouse involves managing data rebalancing and disk capacities across the BE nodes.
However, organizations are increasingly mitigating this tradeoff by using Doris in its federated mode over an Iceberg lakehouse. By utilizing Doris primarily as a high-performance compute layer with aggressive local caching, data teams can achieve the best of both worlds: the infinite, cheap storage of the open data lakehouse combined with the sub-second, highly concurrent query speeds of Apache Doris.
Visual Architecture