Apache Flink
Apache Flink is an open-source, unified stream-processing and batch-processing framework. It is engineered to process massive streams of data at incredible scale and with extremely low latency. In the modern data architecture landscape, Flink is renowned for its stateful computations, exactly-once processing guarantees, and its ability to treat batch processing as simply a special case of stream processing. As open table formats like Apache Iceberg and Apache Paimon have matured, Flink has become a foundational component for building real-time data lakehouses.
Core Definition
Unlike legacy systems that treated batch and stream processing as two entirely separate paradigms—often requiring developers to maintain two distinct codebases under the Lambda Architecture—Apache Flink was designed from the ground up as a native streaming engine. In Flink’s architecture, a batch of data is simply a stream that happens to have a defined beginning and a defined end. A true stream, conversely, is an unbounded dataset that never concludes.
This philosophical difference fundamentally impacts how the engine operates. Instead of accumulating data into micro-batches before processing them (the approach historically taken by Apache Spark), Flink processes events continuously, row by row, as soon as they arrive. This true event-at-a-time processing model enables sub-millisecond latency, making Flink the engine of choice for fraud detection, real-time analytics, and high-frequency trading platforms.
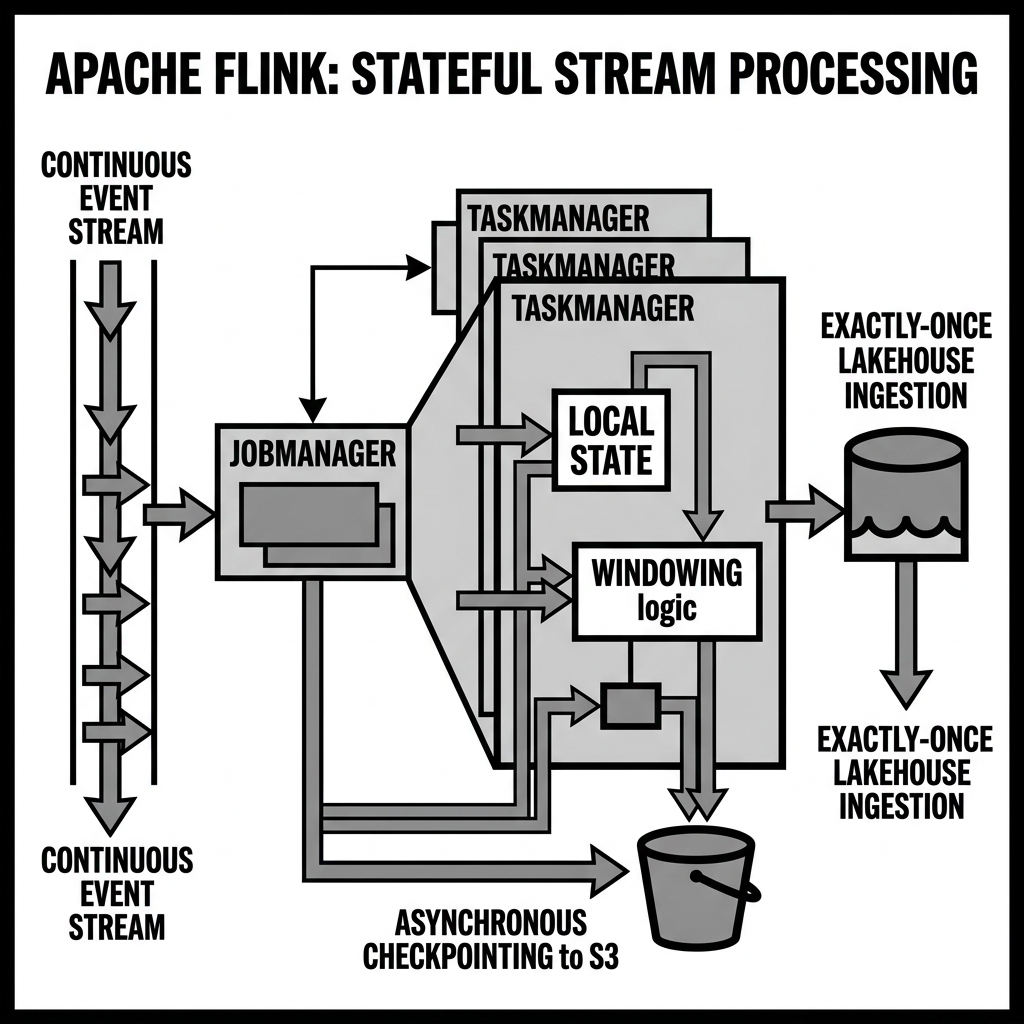
One of Flink’s most critical innovations is its sophisticated state management. Stateful stream processing means that the application remembers information across multiple events. For example, calculating a moving average over a five-minute window requires the engine to maintain the state of the events within that window. Flink manages this state locally on the task managers for maximum performance, while periodically and asynchronously checkpointing that state to durable storage (like Amazon S3 or HDFS) to ensure fault tolerance.
Architecture and Components
The architecture of Apache Flink relies on a distributed, master-worker model consisting of two primary types of processes: JobManagers and TaskManagers.
The JobManager acts as the master node. It is responsible for coordinating the distributed execution of the Flink application. When a client submits a Flink program, the JobManager transforms the logical dataflow graph into a physical execution graph. It requests resources (task slots) from the cluster resource manager, distributes the execution graph to the TaskManagers, and coordinates the checkpointing process to guarantee exactly-once semantics.
The TaskManagers are the worker nodes that execute the actual data processing tasks. Each TaskManager provides a certain number of task slots, which represent a fixed subset of the TaskManager’s resources, primarily memory. TaskManagers receive data streams, process the events according to the instructions provided by the JobManager, maintain local state, and forward the resulting data streams to downstream tasks.
Flink programs are built using one of its core APIs. The DataStream API provides low-level, fine-grained control over streams, state, and time. Flink SQL and the Table API provide a higher-level, declarative interface. Flink SQL is ANSI standard compliant and allows analysts and engineers to define complex streaming aggregations and joins using familiar SQL syntax. Behind the scenes, the Apache Calcite optimizer translates these SQL queries into efficient execution plans.
Time and Windows
Dealing with unbounded data streams introduces complex challenges regarding time. Flink provides robust mechanisms for handling different notions of time to ensure accurate and deterministic results, regardless of network delays or out-of-order events.
Event Time is the time when the event actually occurred at the source device. Processing Time is the time when the event is processed by the Flink machine. In distributed systems, events frequently arrive out of order or are delayed due to network latency. If a system only relies on Processing Time, the results of an aggregation can vary wildly depending on when the data happened to arrive at the engine.
Flink solves this by heavily relying on Event Time. To manage out-of-order events, Flink uses a mechanism called Watermarks. A watermark is a special control record injected into the data stream that declares a specific point in event time. When a Flink operator receives a watermark for time T, it assumes that no more events with an event time older than T will arrive. This allows Flink to safely close time windows and emit accurate results.
Windowing is the process of splitting an infinite stream into finite buckets for computation. Flink supports tumbling windows (fixed size, non-overlapping), sliding windows (fixed size, overlapping), and session windows (defined by periods of inactivity). These windowing functions, combined with event time and watermarks, allow developers to build highly accurate and robust streaming applications.
Integration with the Data Lakehouse
Historically, data lakes were strictly batch-oriented systems. Data was accumulated in object storage and processed nightly or hourly. Flink is playing a major role in shifting the industry toward real-time data lakehouses by bridging the gap between unbounded streams and object storage.
When integrated with Apache Iceberg, Flink can continuously ingest streaming data directly into an Iceberg table. Flink’s checkpointing mechanism integrates tightly with Iceberg’s transactional commits. As Flink processes a stream and writes Parquet files to S3, those files are not immediately visible to downstream readers. Only when Flink successfully completes a global checkpoint does it commit the new metadata to the Iceberg catalog, making the data atomically available. This provides exactly-once ingestion guarantees into the data lake.
Furthermore, Flink can act as a streaming reader for Iceberg tables. Flink can monitor an Iceberg table for new snapshots and continuously read the newly appended data as a stream. This allows organizations to build complex, cascading ETL pipelines entirely on the data lakehouse, replacing expensive message brokers like Apache Kafka for certain intermediate staging layers.
Formats like Apache Paimon have been explicitly designed to maximize Flink’s streaming capabilities, introducing Log-Structured Merge (LSM) tree structures directly onto object storage to support high-throughput streaming updates and deletes.
Summary and Tradeoffs
Apache Flink has established itself as the premier engine for stateful stream processing. Its ability to provide extremely low latency, strong exactly-once guarantees, and robust event-time processing makes it indispensable for real-time data engineering. As the data lakehouse evolves, Flink’s continuous ingestion and streaming read capabilities are enabling organizations to achieve real-time analytics directly on cost-effective object storage.
The primary tradeoff with Apache Flink is its steep learning curve. Mastering concepts like event time, watermarks, state backends, and checkpointing requires a significant paradigm shift for engineers accustomed to traditional batch processing. Operating a Flink cluster in production, particularly tuning memory allocation and managing state sizes, demands specialized expertise.
Despite the operational complexity, the demand for real-time data processing is accelerating. Apache Flink provides the architectural foundation required to process the world’s most demanding data streams without compromising on accuracy or reliability.
Visual Architecture