Apache Hudi
Apache Hudi (Hadoop Upserts Deletes and Incrementals) is the third major pillar of the Open Table Format ecosystem alongside Apache Iceberg and Delta Lake. Born at Uber’s data engineering team in 2016, it was designed to solve a problem far more specific and demanding than general lakehouse reliability: enabling continuous, high-velocity row-level upserts and deletes against massive cloud data lakes at near-real-time latency. Uber’s operational scale — tracking hundreds of millions of GPS events, ride status changes, and payment mutations per day — required a storage architecture that could absorb a relentless stream of row-level mutations without collapsing under write amplification or imposing multi-hour processing windows.
Hudi was the result of that engineering effort. It was open-sourced in 2017 and donated to the Apache Software Foundation, where it became a top-level project. Today, Hudi is deployed across some of the world’s largest data ecosystems, including those at Uber, ByteDance, Alibaba, and Robinhood. Understanding Hudi’s architecture requires a detailed examination of its Timeline, its sophisticated indexing subsystem, its dual table types, and its deeply integrated suite of asynchronous table services.
The Origin Problem: Immutable Lakes and the Upsert Crisis
Before the emergence of Open Table Formats, cloud data lakes built on Apache Hive had a fundamental architectural limitation: they were effectively append-only. You could add new files to a partition, but you could not surgically update or delete individual rows without physically rewriting the entire partition.
For Uber, this was an existential operational problem. A driver’s GPS location changes every few seconds. A ride transitions through dozens of status states (requested, accepted, en_route, arrived, completed, cancelled). Payment records undergo corrections and chargebacks. All of these produce continuous streams of change events that needed to be reflected in the analytical data lake within minutes, not hours.
The only viable solution with a Hive-based lake was to run periodic batch jobs that would completely rebuild affected partitions from scratch, using the latest state of every record. For Uber’s petabyte-scale tables, this was a multi-hour operation that completely blocked downstream reporting and machine learning pipelines.
Hudi was architected specifically to absorb these high-frequency, row-level mutations with minimal latency and without triggering catastrophic, full-partition rewrites.
The Hudi Timeline: The Authoritative State Machine
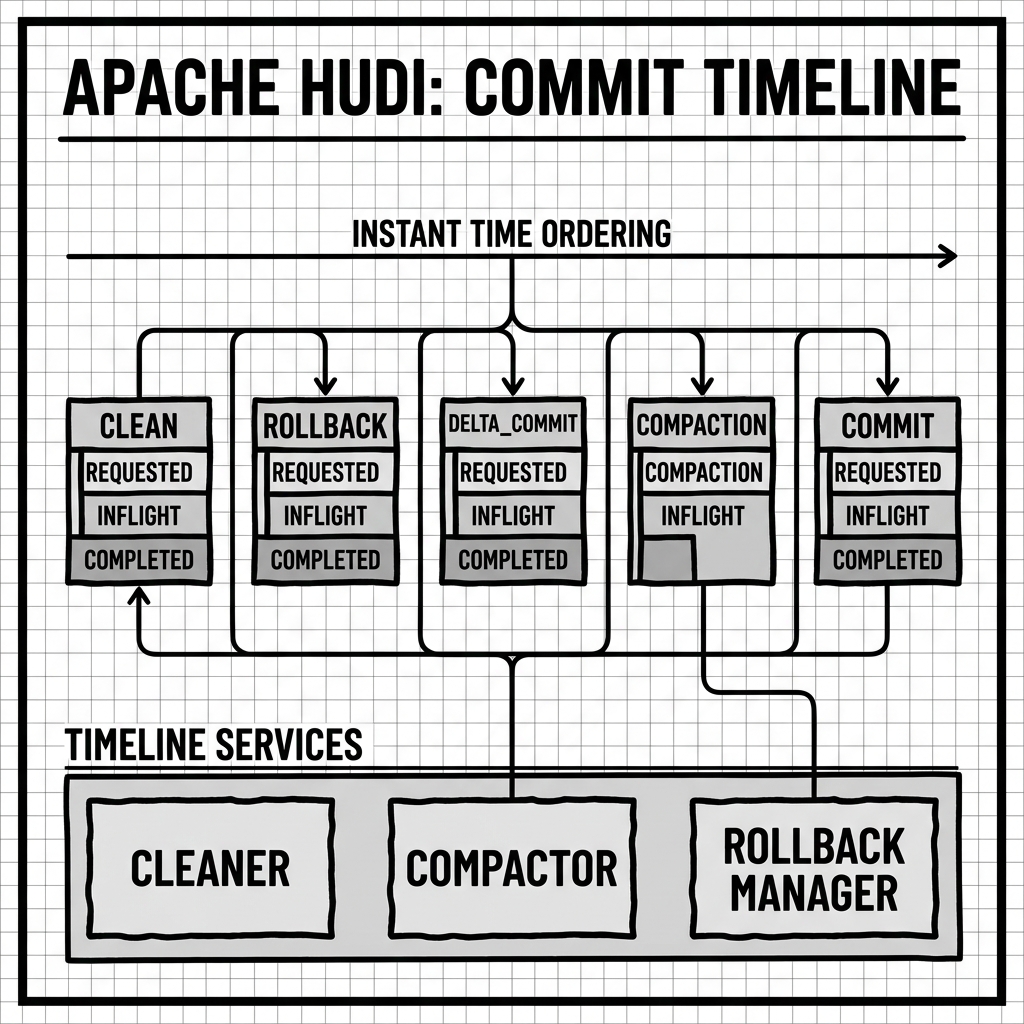
The architectural centerpiece of every Hudi table is the Timeline. The Timeline is Hudi’s equivalent of the Delta Lake transaction log or the Iceberg metadata chain. It is a strict, ordered log of every action ever executed against the table, stored in the .hoodie/ metadata directory at the table’s root.
The Timeline is not simply a log — it is a full state machine. Each entry, called an Instant, has three mandatory fields:
Action: The type of operation, including:
commit: A successful write of new records or upserts to a CoW table.deltacommit: A write of delta log files for a MoR table.compaction: A scheduled or asynchronous merging of delta logs into base Parquet files.clean: Removal of old file versions beyond the configured retention window.rollback: Reversal of a previously failed inflight commit.replacecommit: A clustering operation that reorganizes file groups.
Instant Time: A monotonically increasing timestamp (in milliseconds) that uniquely identifies every action in the Timeline. This ensures strict event ordering.
State: One of three lifecycle states:
REQUESTED: The action has been planned and staged but not yet started.INFLIGHT: The action is currently executing. If a writer crashes mid-operation, this state acts as a flag for subsequent writers to detect and roll back the failed operation before proceeding.COMPLETED: The action has successfully finished and all data is consistent.
This three-state model is Hudi’s primary mechanism for crash recovery. Because every write transitions atomically from REQUESTED to INFLIGHT to COMPLETED, a new writer can inspect the Timeline for any INFLIGHT entries from a previous session and initiate a targeted rollback before starting its own write. This prevents any partially written, inconsistent data from ever becoming visible to readers.
LSM-Based Timeline Storage
Modern Hudi versions (1.x and beyond) replaced the older approach of storing each Timeline Instant as a separate small file with an LSM Tree-based timeline. This is a significant performance improvement for high-frequency write workloads. In the legacy model, a table receiving 10,000 commits per day would accumulate 10,000 individual metadata files in the .hoodie/ directory, causing extreme overhead when listing that directory.
The LSM-based timeline compacts these small per-commit files into larger, sorted metadata blocks — exactly as an LSM tree compacts SSTables in a database like RocksDB or Cassandra. This allows the Timeline to store millions of historical commit entries without degrading metadata access performance, eliminating a major scalability ceiling.
Active vs. Archived Timeline
To further manage metadata performance, the Timeline is segmented into two regions. The Active Timeline contains only the most recent commits (configurable, typically the last N commits or the last T time period). Older entries are evicted from the Active Timeline into the Archived Timeline, which is a compacted, read-optimized archive stored separately. Query engines always read the Active Timeline for current-state planning. Historical Time Travel queries that require older snapshots access the Archived Timeline.
The Indexing Subsystem: The Key to Efficient Upserts
The defining capability of Hudi that distinguishes it most sharply from Iceberg and Delta Lake is its sophisticated Indexing Subsystem. This is the mechanism that makes high-frequency, row-level upserts computationally viable.
When a CDC stream delivers a batch of update events, Hudi must answer a precise question: for each incoming record key, in which specific physical file group does the current version of that record live? Without an index, Hudi would have to scan every file in every partition to find the existing record to update. For a petabyte-scale table, this is obviously not feasible.
Hudi’s index maps record_key -> (partition, file_group_id), allowing the write engine to immediately route each incoming upsert to the specific file group that holds the current version of that record, completely bypassing all other files.
Bloom Filter Index
The default index type. Hudi embeds a Bloom Filter data structure in the footer of each Parquet base file. A Bloom Filter is a probabilistic data structure that can definitively answer “this record key is definitely NOT in this file” (with zero false negatives) or “this record key might be in this file” (with a small, configurable false positive rate). This allows the write engine to quickly prune candidate files, dramatically reducing the number of files that need to be opened and scanned to locate matching records. The GLOBAL_BLOOM variant extends this to cross-partition lookup, essential for CDC streams where a record’s partition value might change.
Record Index
Introduced in Hudi 0.14, the Record Index is a highly scalable, persistent index stored in Hudi’s internal Metadata Table as a dedicated HFile-based index. Unlike the Bloom Filter (which is probabilistic and embedded per-file), the Record Index maintains a complete, exact mapping from every record key to its current partition and file group ID. This makes point lookups for specific records extremely fast and accurate, with no false positives. For large-scale tables with billions of records and very high update rates, the Record Index significantly outperforms the Bloom Filter.
External Indexes (HBase, Redis)
For the most extreme scales, Hudi supports pluggable external index backends such as Apache HBase. In this model, the mapping of record keys to file groups is maintained in an external database, allowing virtually unlimited index scale at the cost of an additional infrastructure dependency.
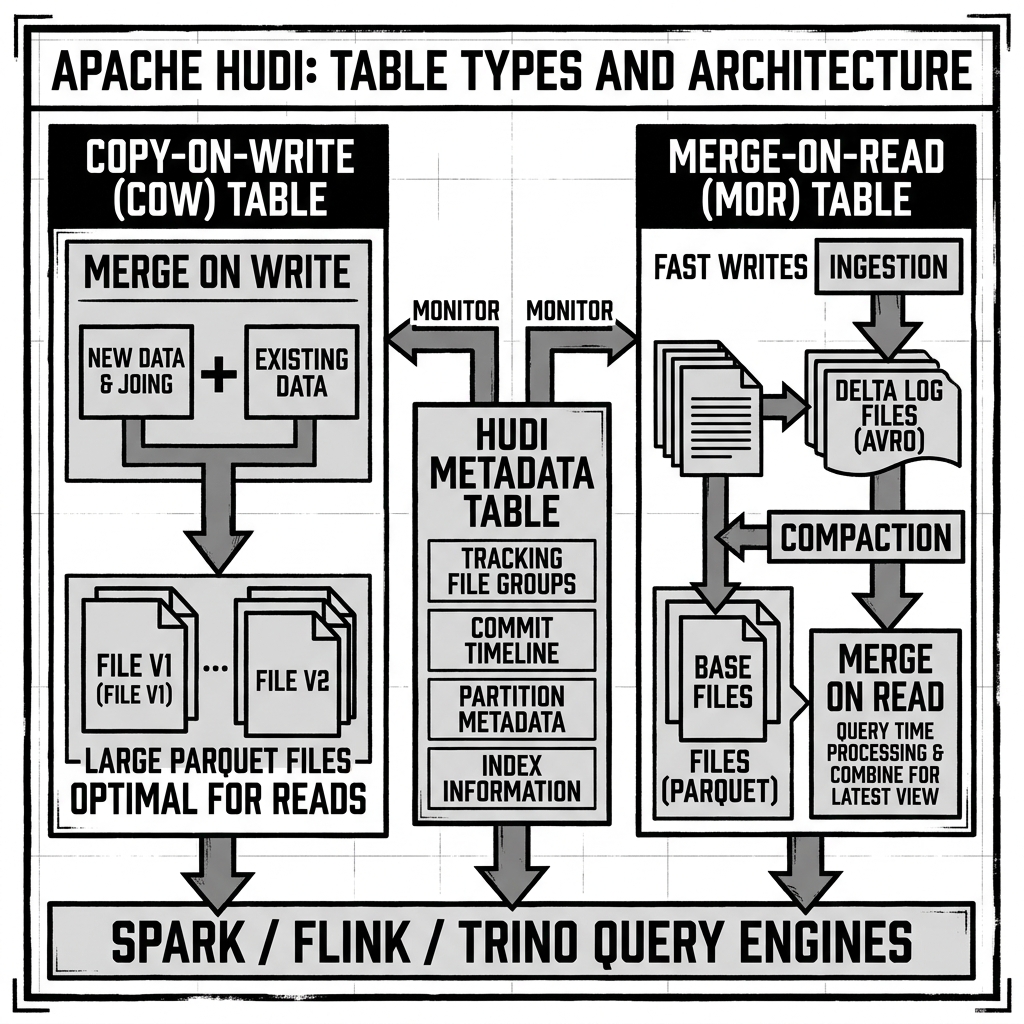
Table Types: Copy-on-Write vs. Merge-on-Read
Hudi’s most critical design decision is the choice of Table Type, which directly determines the write-amplification / read-latency trade-off.
Copy-on-Write (CoW)
In a CoW table, every write that involves an update or delete to an existing record triggers a full rewrite of the affected Parquet base file. The write engine uses the index to identify which base files contain records that need updating, reads those entire files into memory, applies the updates, and writes completely new Parquet files. The old files are logically removed from the Timeline.
The result is a clean, highly optimized set of Parquet files where every read is a direct, sequential scan with no runtime merge overhead. CoW tables deliver the best possible query performance. However, they suffer from significant write amplification: updating one row in a 500MB file requires rewriting all 500MB. CoW is optimal for tables that receive infrequent batch updates but are queried by many concurrent analytical workloads.
Merge-on-Read (MoR)
Hudi pioneered the Merge-on-Read architecture, which is now also supported by Iceberg and Delta Lake (via Deletion Vectors). In a MoR table, writes are split into two layers:
Base Files: Full Parquet (or ORC) snapshots of the table’s records, written during initial ingestion or compaction runs. These are large, columnar, and highly optimized for reads.
Delta Log Files: Row-based Avro log files (*.log) stored in Hudi’s internal format (HoodieLogBlock). When an upsert or delete arrives, instead of rewriting the base file, Hudi simply appends a new log block to the relevant delta log file for that file group. This write is essentially free from an I/O perspective: it is a tiny append to a row-based file.
The delta log file accumulates all mutations since the last compaction. A file group therefore consists of a base Parquet snapshot plus zero or more delta log files. At read time, the query engine must merge the base file and all its associated delta logs, producing the final, current view of each record through an in-memory reconciliation process.
MoR tables enable dramatically faster writes and support near-real-time data ingestion with latencies as low as a few seconds. The trade-off is increased read-time complexity and latency, which grows as delta logs accumulate.
Read Views for MoR Tables
Hudi provides three distinct read views for MoR tables, giving engineers flexible control over the performance trade-off:
Read Optimized View: The query engine reads only the base Parquet files, completely ignoring the delta log files. This gives maximum read speed but only reflects the state of the data as of the last compaction. Records updated after the last compaction will not be visible in their current state.
Near-Real-Time View (also called Snapshot View): The query engine reads the base files and merges all delta log files in memory. This provides the current, accurate state of all records but requires the merge overhead at read time.
Incremental View: A uniquely powerful Hudi capability. Rather than reading the full table, the engine reads only the records that changed between two specified Timeline instants. This powers highly efficient incremental ETL pipelines where downstream jobs only need to process the delta since their last checkpoint.
Table Services: The Built-in Maintenance Engine
Hudi’s most architecturally distinctive feature compared to Iceberg and Delta Lake is its comprehensive suite of built-in, deeply integrated Table Services. These are background maintenance operations that Hudi manages internally, often running asynchronously alongside live write streams.
Compaction
Compaction is mandatory for MoR tables. It is the process of reading a file group’s base Parquet file and all its accumulated delta log files, merging them in memory to produce the final current state of every record, and writing a brand-new, clean Parquet base file. The old delta log files are then scheduled for deletion by the Cleaner.
Hudi supports two compaction execution modes:
Inline Compaction: Compaction is triggered automatically within the same write job that writes data. After every N deltacommits, the write engine will compact the table before completing. This is simple to configure but can add latency to the primary write path during peak ingestion.
Async Compaction: A separate Spark or Flink job runs compaction concurrently alongside the primary write stream. The write stream continues appending deltacommits at full speed, while the async compaction job continuously merges older log files into fresh base files in the background. This requires more operational coordination but delivers maximum write throughput for the primary pipeline.
Clustering
Clustering is analogous to Z-Ordering in Delta Lake’s OPTIMIZE command. It reorganizes the physical layout of the base Parquet files without changing the logical data. By rewriting files to sort or cluster the data by specific columns commonly used in query predicates (e.g., customer_id, region, event_type), clustering tightens the min/max statistics within each file. This allows the query engine to skip far more files during predicate pushdown, dramatically reducing query latency for analytical workloads.
Clustering is driven by configurable strategies that analyze current file statistics and determine the optimal new layout. It can be executed inline with writes or asynchronously.
Cleaner
The Cleaner is the garbage collector for Hudi tables. It runs automatically after each commit and removes older file versions that are no longer needed. In a CoW table, this means removing the old base files that were replaced by the latest rewrite. In a MoR table, it removes delta log files that have been absorbed by a completed compaction. The Cleaner respects a configurable retention window (expressed as a number of commits or a time period) to ensure that ongoing Time Travel queries or incremental readers with older checkpoints still have access to the historical file versions they need.
Hudi’s Metadata Table
To eliminate expensive directory-listing operations against object storage — the same problem that plagued Hive — Hudi maintains an internal Metadata Table. This is a separate, self-managed Hudi table (specifically an MoR table) that serves as a persistent, always-up-to-date index of the data table’s physical file system.
The Metadata Table tracks every file in every partition without requiring a live LIST call against S3 or GCS. When a write adds or removes files, the Metadata Table is updated atomically alongside the primary data commit. Query engines read the Metadata Table to get the complete file list for query planning in milliseconds, completely bypassing the slow and expensive object-store listing operation.
In recent Hudi versions, the Metadata Table also stores secondary indexes: column statistics (min/max for every column of every file), bloom filter indexes, and record-level indexes. This centralizes all the metadata required for intelligent query planning into a single, efficiently maintained structure.
Incremental Processing: Hudi’s Unique Analytical Primitive
One of Hudi’s most compelling and distinctive capabilities is Incremental Processing. Every other Open Table Format treats the table as a point-in-time snapshot — you read the current state or you time-travel to a historical state. Hudi adds a third mode: reading only the records that changed between two Timeline instants.
An incremental query looks like: “Give me all records that were inserted, updated, or deleted between commit T1 and commit T2.”
This is extraordinarily powerful for building efficient data pipeline architectures. A downstream Silver-layer ETL job no longer needs to re-read the entire Bronze table every 15 minutes to find what changed. Instead, it reads only the incremental delta since its last successful checkpoint, processes those records, and updates the Silver table. This can reduce downstream pipeline compute costs by 95% or more on large, slowly-changing tables.
Ecosystem and Adoption
Apache Hudi is deeply integrated with Apache Spark as the primary write engine, with full support also available for Apache Flink for continuous streaming ingestion. It is natively supported on all major cloud platforms, including AWS (EMR, Glue), Google Cloud (Dataproc), and Azure (HDInsight and Synapse).
Hudi tables can be read by Trino, Presto, Apache Hive, Dremio, Impala, and Spark SQL using the Hudi bundle JAR. AWS Athena and Google BigQuery also provide native Hudi read support.
The Hudi 1.x roadmap continues to push the boundaries of streaming lakehouse architectures, with improvements to the LSM Timeline, enhanced multi-modal indexing, and tighter integration with the emerging Apache Paimon ecosystem for continuous streaming tables.
Conclusion
Apache Hudi occupies a unique and irreplaceable position in the Open Table Format ecosystem. It is the undisputed leader for high-frequency, row-level mutation workloads, particularly those driven by Change Data Capture pipelines and continuous streaming ingestion. Its combination of a multi-state crash-safe Timeline, a sophisticated pluggable indexing subsystem, flexible CoW/MoR table types, deeply integrated asynchronous Table Services, and the unique capability of incremental processing makes it the most comprehensive and operationally rich of the three major formats. Organizations building real-time lakehouse architectures where data must be visible within seconds of a source system change, and where individual records undergo frequent updates throughout their lifecycle, will find Apache Hudi provides architectural capabilities that Iceberg and Delta Lake simply have not yet matched.
Visual Architecture