Apache Iceberg
As data lakes grew in popularity, organizations quickly realized that simply dumping raw Parquet or ORC files into Amazon S3 was not a viable long-term strategy for analytics. Query engines had to perform expensive directory-listing operations just to find the data they needed to read. Updating a single record required rewriting entire directories. Concurrent writes often resulted in data corruption or phantom reads.
Apache Iceberg was created at Netflix to solve these exact problems. It is an open table format for huge analytic datasets. Iceberg adds tables to compute engines like Spark, Trino, PrestoDB, Flink, Hive, and Impala using a high-performance format that works just like a SQL table. In essence, Apache Iceberg acts as the translation layer between the compute engine and the raw data files sitting in object storage, enabling ACID transactions, time travel, and schema evolution on the data lake.
The Metadata Tree Architecture
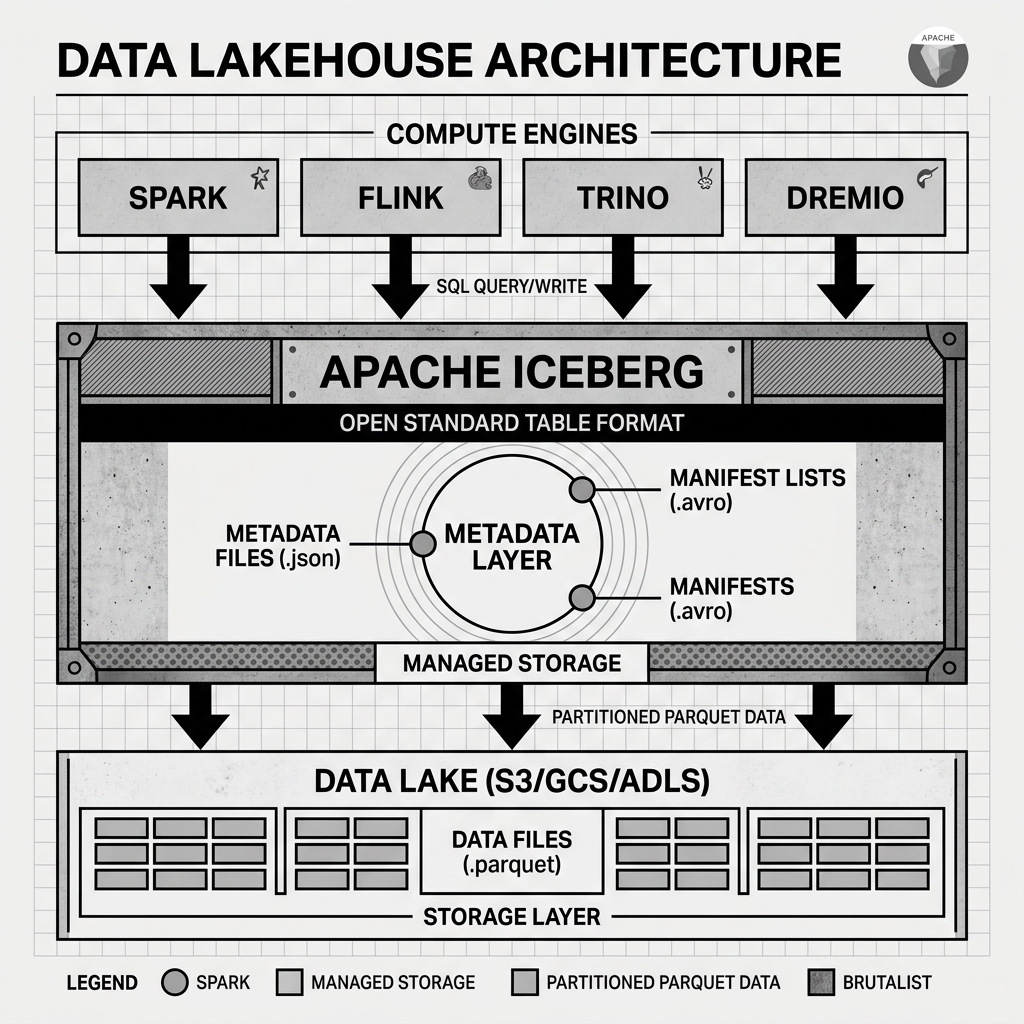
The secret to Apache Iceberg’s performance and reliability is its architectural design. Unlike legacy formats like Apache Hive, which tracked data at the folder or directory level, Apache Iceberg tracks data at the individual file level using a strict hierarchy of metadata files. This is known as the Metadata Tree.
At the very top of the tree is the Metadata File (typically a JSON file). This file contains the highest-level information about the table, such as the table’s schema, partitioning configuration, and an array of historical snapshots. A snapshot represents the state of the table at a specific point in time.
When a snapshot is created, it points to a Manifest List (an Avro file). The manifest list contains an array of pointers to the next layer down: the Manifest Files. Crucially, the manifest list also stores aggregated statistics about the data contained within each manifest file, such as the upper and lower bounds of partition values. This allows query engines to quickly prune massive amounts of data without actually opening the underlying files.
The Manifest Files (also Avro files) sit below the manifest list. These files contain direct pointers to the physical raw data files (typically Parquet files) sitting in object storage. Like the manifest list, manifest files also store column-level statistics for each individual data file.
Because of this tree structure, an engine like Apache Spark can evaluate a SQL WHERE clause by reading the metadata file, pruning irrelevant manifest lists, pruning irrelevant manifest files, and ultimately identifying only the specific handful of Parquet files that contain the requested data. This eliminates the need for slow O(N) directory listing operations and enables blazing-fast query performance.
Diagram 1: Conceptual Architecture
Core Capabilities
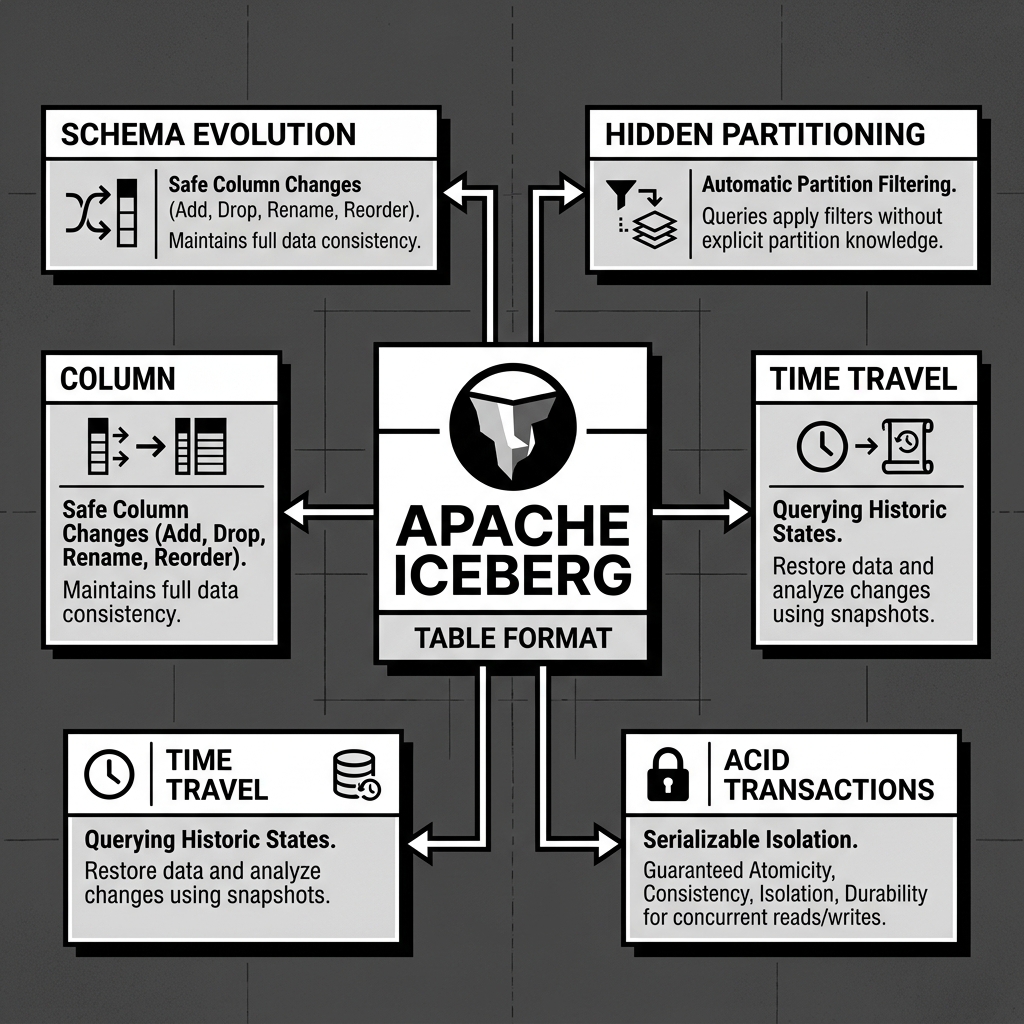
Because Apache Iceberg tracks data via explicit metadata rather than implicit directory structures, it unlocks several powerful capabilities that were previously impossible on a data lake.
ACID Transactions: When a compute engine writes data to an Iceberg table, it creates a completely new snapshot. The new metadata tree is constructed alongside the old one. Once the write is complete, the engine atomically swaps the current snapshot pointer in the catalog. If two engines attempt to write simultaneously, Iceberg uses optimistic concurrency control to ensure that only one write succeeds, preventing data corruption. Readers are never blocked by writers, as they simply read the snapshot that was active when their query began.
Hidden Partitioning: In legacy systems like Hive, partitioning data by a derived column (such as extracting the month from a timestamp) required creating a completely separate, explicit column for the month. Users had to remember to include both the timestamp and the month column in their queries, or else they would trigger massive, full-table scans. Iceberg handles this automatically via Hidden Partitioning. The partition logic is defined in the metadata, not the data files. Users simply query the timestamp column natively, and Iceberg automatically translates the query to prune the correct partitions under the hood.
Schema Evolution: Changing a table’s schema in a traditional data lake often required rewriting all the historical data to match the new format. Iceberg tracks schemas independently via unique column IDs. This means you can add, drop, rename, or reorder columns instantly as a metadata operation. Historical data remains untouched, and queries seamlessly handle the discrepancies between old and new files.
Time Travel: Because Iceberg retains previous snapshots in its metadata file, users can literally query the table as it existed at any point in the past. This is invaluable for machine learning reproducibility, auditing, and recovering from accidental data deletions.
Diagram 2: Operational Flow
The Catalog Layer
While the metadata tree defines the structure of a single table, the Apache Iceberg architecture requires one additional component: the Catalog.
The catalog acts as the central registry for the entire lakehouse. When a query engine wants to interact with an Iceberg table, it must first ask the catalog, “Where is the current metadata file for this table?” The catalog responds with the URI of the active JSON metadata file in object storage.
This mechanism is what guarantees atomic transactions across multiple concurrent systems. The catalog must provide an atomic swap operation (e.g., a Compare-and-Swap). When an engine finishes creating a new metadata file, it tells the catalog to update its pointer from the old metadata file to the new one. If the atomic swap succeeds, the transaction is committed. Popular catalogs include the Iceberg REST Catalog specification, Project Nessie, AWS Glue, and Tabular.
By completely separating the compute engines from the storage layer and mediating their interactions entirely through metadata, Apache Iceberg has become the de facto standard for building modern, vendor-neutral data lakehouses.