Apache Paimon
Apache Paimon is the youngest and most architecturally distinctive of the major Open Table Formats. Whereas Apache Iceberg was born to solve massive-scale metadata performance problems at Netflix, Delta Lake was built to bring reliability to Spark jobs at Databricks, and Apache Hudi was designed for high-frequency upserts at Uber, Paimon emerged from the Apache Flink community with a fundamentally different thesis: that a table format should be designed from its foundations to be a native, first-class citizen of a continuous streaming architecture, not a batch format bolted onto streaming workflows after the fact.
Originally known as Flink Table Store, the project was donated to the Apache Software Foundation and graduated as Apache Paimon in 2023. It has since become a core component of real-time lakehouse architectures, particularly within the Chinese internet industry ecosystem (Alibaba, ByteDance, Meituan) and increasingly in global enterprise deployments seeking sub-minute data freshness without the operational complexity of maintaining separate streaming databases alongside analytical lakehouse tables.
Understanding Paimon requires understanding a fundamentally different design philosophy from the other Open Table Formats. While Iceberg and Delta Lake were built as reliable batch storage layers that were later extended to support streaming, Paimon was purpose-built as a streaming storage layer that also supports efficient batch reads. This inversion of priority produces an architecture that is genuinely unique in the ecosystem.
The Core Problem: The Streaming-Batch Integration Gap
In the pre-Paimon streaming lakehouse architecture, a typical data pipeline looked like this:
- Apache Kafka ingests raw events from application systems.
- Apache Flink consumes from Kafka, performs real-time aggregations and joins, and writes results to… somewhere.
The “somewhere” was the problem. The options were:
A relational database (e.g., MySQL, PostgreSQL): Fast for individual record updates, but catastrophically slow for large analytical scans. Completely unsuitable for the data volumes typical in a lakehouse context.
Apache Cassandra or HBase: Horizontally scalable key-value stores, but lacking SQL richness, join support, and analytical query optimization.
Write back to Kafka: Enables downstream Flink jobs to consume, but Kafka is not designed for long-term storage or ad-hoc batch queries.
Write to Parquet files on S3 via Iceberg or Hudi: Supports batch reads but requires periodic compaction to make streaming writes queryable. The data is typically unavailable for hours after it is written, completely undermining the value of real-time streaming processing.
None of these options provided a single storage layer that could simultaneously absorb continuous, high-velocity streaming writes at sub-second latency AND serve fast, consistent batch analytical queries. Apache Paimon was built to fill exactly this gap.
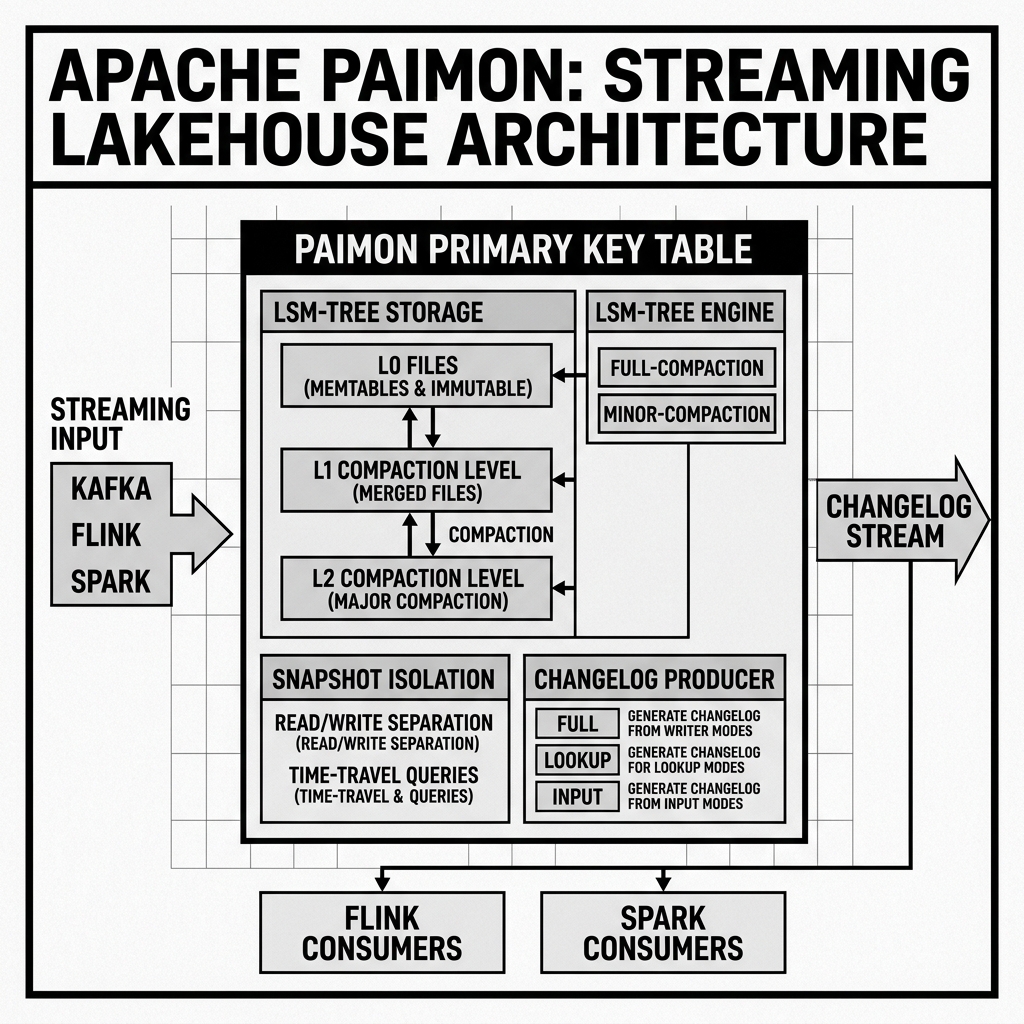
The LSM-Tree Foundation
The most important architectural decision in Apache Paimon is its use of the Log-Structured Merge (LSM) Tree as the internal storage engine for Primary Key tables. This is a fundamentally different approach from Iceberg, Delta, and Hudi, all of which store data exclusively in columnar Parquet or ORC files.
An LSM tree is the storage engine that powers some of the world’s most write-optimized databases, including RocksDB (embedded in Flink’s state backend), Cassandra, HBase, and ClickHouse. Its core insight is that writes to spinning or solid-state disks are dramatically faster when performed as sequential appends rather than random overwrites. An LSM tree converts all writes — including updates and deletes — into sequential append operations, making the write path extremely fast regardless of which specific records are being modified.
The LSM Write Path in Paimon
When a Flink streaming job writes a batch of records to a Paimon Primary Key table, the process unfolds as follows:
-
Level 0 (L0) Write: The incoming records are written as a new sorted Parquet file at Level 0 of the LSM tree within the relevant data bucket. This write is sequential and extremely fast. Multiple L0 files accumulate over time.
-
Compaction: When the number of L0 files exceeds a configured threshold (or a scheduled compaction is triggered), Paimon’s compaction process kicks in. It reads the L0 files, merges them with the existing Level 1 (L1) sorted files, resolves any duplicate keys (keeping only the latest version of each record), and writes a new set of sorted files at L1. This process repeats across multiple levels (L0 → L1 → L2 → …) in a cascading, controlled fashion.
-
Lookup for Updates: When a new incoming record has the same primary key as an existing record, Paimon uses an efficient lookup mechanism against the existing LSM levels to find the old version. The new record is written at L0, and the old version will be superseded during the next compaction pass. This process is analogous to how Hudi uses its indexing subsystem to locate existing records, but Paimon achieves it through the intrinsic structure of the LSM tree.
The Read Path and Sorted Runs
For batch analytical queries, a Paimon read scan must traverse multiple LSM levels and merge the results. Because the data within each level is sorted by the primary key, the merge is an efficient k-way merge sort (similar to what a database does when merging sorted runs during a sort-merge join). Files at higher LSM levels (L1, L2) are larger and have less overlap than L0, so a fully compacted table with minimal L0 files provides the fastest batch read performance.
Data Organization: Tables, Buckets, and Partitions
Paimon organizes data using a hierarchy of three logical abstractions:
Partitions: Top-level data organization, identical in concept to Iceberg or Hive partitions. A partition divides the data into non-overlapping segments based on the values of one or more designated partition columns (e.g., dt=2026-05-18). Each partition is a separate directory in object storage.
Buckets: Within each partition, data is further divided into Buckets. A Bucket is the smallest unit of parallelism and the smallest unit of a single LSM tree. Each bucket contains its own independent set of LSM files. The assignment of a record to a bucket is determined by hashing its primary key modulo the configured number of buckets. Buckets ensure that all records with the same primary key always land in the same bucket, making key-lookup and compaction operations fully local and parallelizable.
Files: Within each bucket, data is stored as Parquet or ORC files organized across the LSM levels. Each snapshot of the table records which files exist at each LSM level within each bucket, providing snapshot-consistent reads.
Changelog Production: Streaming the Lakehouse
Paimon’s most distinctive capability — and the one that most clearly differentiates it from all other Open Table Formats — is its Changelog Producer. This system allows a Paimon table to serve not just as a static data store, but as an active, queryable change stream.
A Changelog is a sequence of change events (INSERT, UPDATE_BEFORE, UPDATE_AFTER, DELETE) that precisely describes every mutation made to the table’s records over time. This is exactly the format that Flink and other streaming engines consume natively.
The ability to read changes from a Paimon table as a Flink changelog source allows downstream Flink jobs to build real-time, incrementally-updating aggregations directly on top of Paimon tables, without any intermediate Kafka topic. The Paimon table itself becomes the durable, queryable, changelog-capable streaming source.
Paimon supports four Changelog Producer modes:
None (Default)
In this mode, no explicit changelog is generated. Downstream consumers can still read changes between two snapshots (via snapshot diff), but the individual change events (UPDATE_BEFORE / UPDATE_AFTER) are not individually tracked. This mode has the lowest storage and write overhead and is suitable when downstream consumers only need the final state after each batch, not a complete change event history.
Input Mode
In this mode, Paimon directly saves the input change records (as provided by the Flink CDC source) as separate changelog files alongside the regular data files. The change events emitted by the source system (e.g., a Debezium MySQL CDC connector) are preserved verbatim. This is the most accurate and complete changelog, as it captures the exact semantics of the source change events, but it requires the upstream source to provide full UPDATE_BEFORE / UPDATE_AFTER pairs.
Lookup Mode
When the upstream source does not provide complete UPDATE_BEFORE events (e.g., it only provides the new value of an upserted record), Paimon can generate the changelog using a lookup against its existing data. During compaction, Paimon looks up the current value of each key before applying the update, emitting an UPDATE_BEFORE event for the old value and an UPDATE_AFTER event for the new value. This mode adds overhead to the compaction process but enables full changelog semantics from upsert-only sources.
Full Compaction Mode
In this mode, a complete changelog between two full compaction states is generated. After each full compaction, Paimon compares every record in the new compacted state against the previous compaction’s state and emits the difference as change events. This is the most complete changelog with the lowest write amplification during ingestion, but it has higher latency because changes are only published after a full compaction completes.
Lookup Joins: Paimon as a Streaming Dimension Store
A Lookup Join is a common pattern in stream processing: enrich each event in a real-time event stream with static or slowly-changing reference data from a dimension table (e.g., enrich a clickstream event with the user’s country, tier, and account status by looking up their user_id).
In traditional Flink architectures, this required either loading the entire dimension table into Flink’s managed state (expensive and stateful), or querying an external database on every event (high latency and external coupling).
Paimon natively supports Lookup Joins against its Primary Key tables. Because Paimon’s LSM structure allows individual-key lookups to be executed in milliseconds, a Flink streaming job can perform real-time lookups against a Paimon dimension table for every incoming event. The lookup is served directly from Paimon’s local cache (backed by the LSM structure’s RocksDB-like read path), making it fast and self-contained.
For very large dimension tables, Paimon supports Shuffle Lookup, which distributes the dimension table’s data across Flink subtasks (partitioned by bucket) so that each subtask only needs to maintain a fraction of the dimension data in its local cache. This allows lookup joins to scale to dimension tables with billions of records that would never fit in Flink’s managed state.
Append-Only Tables vs. Primary Key Tables
Paimon supports two fundamentally different table modes:
Primary Key Tables: The LSM-based storage model described above, supporting full upserts, deletes, and changelog production. This is the more complex and feature-rich mode, designed for mutable dimensional or fact data that undergoes continuous updates.
Append-Only Tables: A simpler storage mode where data is only ever inserted, never updated or deleted. Append-only tables do not use an LSM tree. Instead, new records are simply written directly as new Parquet files, similar to how Iceberg or Delta Lake handle pure insert workloads. This mode has significantly lower write overhead and is optimal for immutable event log data (clickstreams, sensor readings, transaction logs) where the data model guarantees no record is ever modified after creation.
Snapshot Isolation and Time Travel
Like all modern Open Table Formats, Paimon maintains a snapshot-based version history. Every successful write commits a new immutable Snapshot to the Paimon metadata, which records the exact set of files at each LSM level within every bucket at that point in time.
This enables standard Time Travel queries (querying the table as of a specific snapshot ID or timestamp) using any supported query engine. It also provides the foundation for incremental batch reads: a downstream Spark or Flink batch job can read only the files that were added or changed between snapshot ID N and snapshot ID M, processing only the new data since its last checkpoint.
Ecosystem: Flink-First, But Not Flink-Only
Paimon’s primary and most deeply integrated compute engine is Apache Flink. All advanced streaming features — changelog production, incremental source reads, lookup joins — require Flink or a Flink-compatible engine. The Paimon Flink integration is a first-class, fully native experience.
However, Paimon also provides read connectors for Apache Spark, Trino, and Apache Hive, allowing data written by Flink streaming jobs to be queried by batch analytical engines. A complete real-time lakehouse architecture built on Paimon might look like: Flink continuously ingests CDC events and writes to Paimon tables (using the Input changelog mode), Spark batch jobs periodically perform heavy analytical transformations on those tables, and Trino or Dremio serves interactive ad-hoc SQL queries for business analysts — all reading from and writing to the same underlying Paimon tables.
Conclusion
Apache Paimon represents a genuine architectural innovation in the Open Table Format ecosystem. By building on an LSM-tree foundation instead of a pure Parquet-file model, and by introducing native changelog production as a first-class primitive, it solves the streaming-batch integration gap that remains an unsolved pain point in architectures built on Iceberg, Delta, and Hudi. For organizations whose data architecture is driven by Apache Flink, whose operational requirement is sub-minute data freshness, and whose data modeling involves continuously mutating records that must simultaneously support fast key-value lookups AND large-scale analytical scans, Paimon provides a uniquely cohesive and powerful architectural foundation that no other Open Table Format currently matches.
Visual Architecture