Apache Spark
Apache Spark
Apache Spark is a unified analytics engine designed for large-scale data processing. It provides high-level APIs in Java, Scala, Python, and R, along with an optimized engine that supports general execution graphs. It is the dominant compute engine in the modern data ecosystem and plays a central role in open data lakehouse architectures.
Core Definition
Apache Spark was originally developed at UC Berkeley’s AMPLab in 2009 and later donated to the Apache Software Foundation. It was created as a response to the limitations of the Hadoop MapReduce computing model. MapReduce required writing data to disk between every intermediate step of a calculation. This disk I/O became a massive bottleneck for iterative algorithms and interactive data mining.
Spark introduced the concept of Resilient Distributed Datasets or RDDs. An RDD is a fault-tolerant collection of elements that can be operated on in parallel. The key innovation of Spark was that RDDs could be cached in memory. By keeping intermediate data in RAM rather than writing it back to a physical disk, Spark achieved performance gains of up to one hundred times over Hadoop MapReduce for certain workloads.
Over time, Spark evolved beyond RDDs to introduce higher-level abstractions like DataFrames and Datasets. These abstractions are built on top of the Catalyst Optimizer, which analyzes logical query plans and generates highly optimized physical execution plans. This shift allowed developers to write declarative SQL or DataFrame code, leaving the complex optimization details to the Spark engine itself.
In the context of the data lakehouse, Apache Spark serves as the primary engine for data engineering, ETL pipelines, and large-scale transformations. It integrates natively with open table formats like Apache Iceberg, Delta Lake, and Apache Hudi. This integration allows Spark to perform ACID transactions, schema evolution, and time travel queries directly against object storage systems like Amazon S3, Google Cloud Storage, and Azure Data Lake Storage.
Architecture and Components
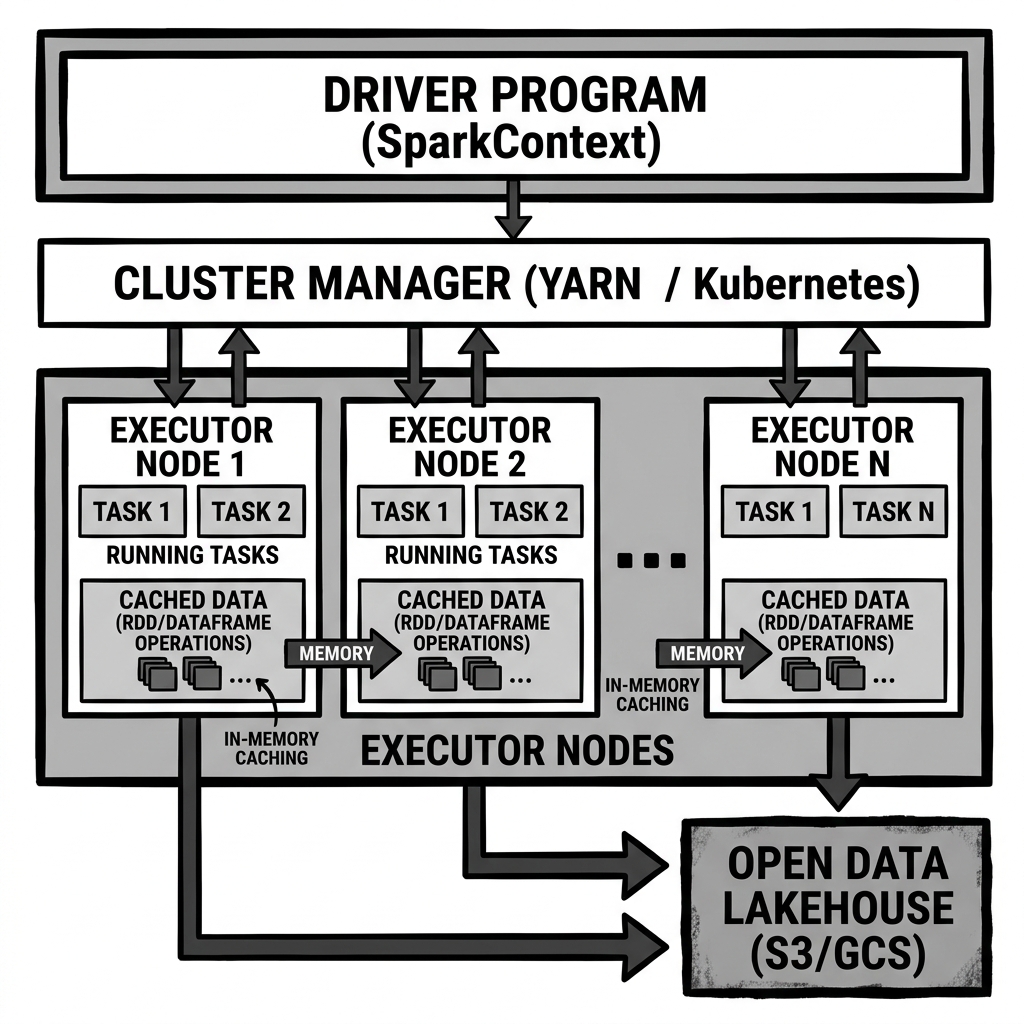
The architecture of Apache Spark is based on a distributed master-worker model. A Spark application consists of a driver program that runs the user’s main function and executes various parallel operations on a cluster.
The driver program is responsible for converting the user program into a Directed Acyclic Graph or DAG of tasks. It also coordinates the scheduling of these tasks across the cluster. The driver communicates with a cluster manager, which is responsible for allocating resources across the applications. Spark supports multiple cluster managers, including Hadoop YARN, Apache Mesos, and Kubernetes, as well as a standalone cluster manager included with Spark.
The cluster manager allocates resources to executor processes running on worker nodes. Executors are the workhorses of a Spark application. They run the tasks scheduled by the driver, store data in memory or on disk, and return the results to the driver. Each Spark application gets its own set of executor processes, which remain alive for the duration of the application and run tasks in multiple threads.
This isolation means that Spark applications cannot share data across applications without writing it to an external storage system. This is where open table formats and catalogs become essential in a lakehouse architecture, providing a shared metadata and storage layer that multiple Spark applications can read from and write to concurrently without data corruption.
Implementation and Operations
When a user submits a query or transformation using the DataFrame API, Spark does not execute it immediately. Instead, Spark uses lazy evaluation. It builds up a logical plan of the transformations required to produce the final result. Execution is only triggered when an action, such as writing data to a file or collecting results to the driver, is called.
Once an action is triggered, the Catalyst Optimizer takes over. The optimizer applies a series of rules to simplify and improve the logical plan. This includes techniques like predicate pushdown, where filters are applied as close to the data source as possible to minimize the amount of data read from disk. It also includes column pruning, ensuring that only the columns required for the calculation are actually read.
After the logical plan is optimized, Catalyst generates multiple physical plans and uses a cost model to select the most efficient one. The selected physical plan is then converted into Java bytecode using Tungsten’s whole-stage code generation. This generated code is heavily optimized to leverage modern CPU features and minimize memory allocations, bypassing much of the overhead of the Java Virtual Machine.
The physical execution plan is broken down into a series of stages, separated by shuffle operations. A shuffle occurs when data needs to be redistributed across the cluster, such as during a group-by or join operation. Shuffles are expensive operations because they involve disk I/O, data serialization, and network transmission. Optimizing Spark applications often involves minimizing the amount of data shuffled.
Data Lakehouse Integration
Spark’s integration with the data lakehouse is facilitated through the Data Source V2 API. This API allows external data sources and table formats to push computations directly down to the storage layer.
When reading from an Apache Iceberg table, for example, Spark queries the Iceberg catalog to locate the current metadata file. It then reads the manifest lists and manifest files to determine exactly which Parquet data files contain the relevant data. By leveraging Iceberg’s hidden partitioning and column-level statistics, Spark can skip vast amounts of irrelevant data before launching a single read task.
When writing to an Iceberg table, Spark executes the write tasks in parallel across its executors. Each executor writes its assigned data to new Parquet files in object storage. Once all executors have finished writing successfully, the Spark driver commits the transaction to the Iceberg catalog. If the driver crashes before the commit, the transaction fails entirely, and the newly written files become orphan files that are ignored by future readers. This atomic commit mechanism guarantees strong consistency.
Advanced Capabilities
Spark encompasses several specialized libraries built on top of its core engine. Spark SQL provides a SQL interface for querying data and allows for seamless interoperability between SQL and the DataFrame API.
Structured Streaming allows developers to process real-time data streams using the exact same DataFrame API used for batch processing. Spark handles the complexities of incremental processing, state management, and exactly-once delivery guarantees. This unified approach greatly simplifies the development and maintenance of data pipelines, as the same code can be used for both historical backfills and real-time ingestion.
MLlib is Spark’s distributed machine learning framework. It provides a wide range of algorithms for classification, regression, clustering, and collaborative filtering. By running directly on the Spark cluster, MLlib allows data scientists to train models on massive datasets that would not fit into the memory of a single machine.
GraphX is an API for graphs and graph-parallel computation. It extends the Spark RDD abstraction to support directed multigraphs with properties attached to each vertex and edge.
Summary and Tradeoffs
Apache Spark remains the foundational compute engine for large-scale data engineering. Its unified API, in-memory processing capabilities, and advanced query optimizer make it incredibly versatile and powerful. Its tight integration with open table formats like Apache Iceberg has cemented its position as the primary ingestion and transformation engine for the modern open data lakehouse.
However, Spark is not without its tradeoffs. Managing a Spark cluster, particularly tuning memory configurations and handling out-of-memory errors, requires significant expertise. The JVM overhead and the cost of shuffle operations can make Spark less suitable for ad-hoc, low-latency exploratory queries compared to specialized MPP engines like Trino or StarRocks.
Despite these challenges, the ecosystem surrounding Spark is unparalleled. From managed services like Databricks and Amazon EMR to its vast community support, Apache Spark continues to be the most critical skill for data engineers building scalable data platforms.
Visual Architecture