Apache XTable (OneTable)
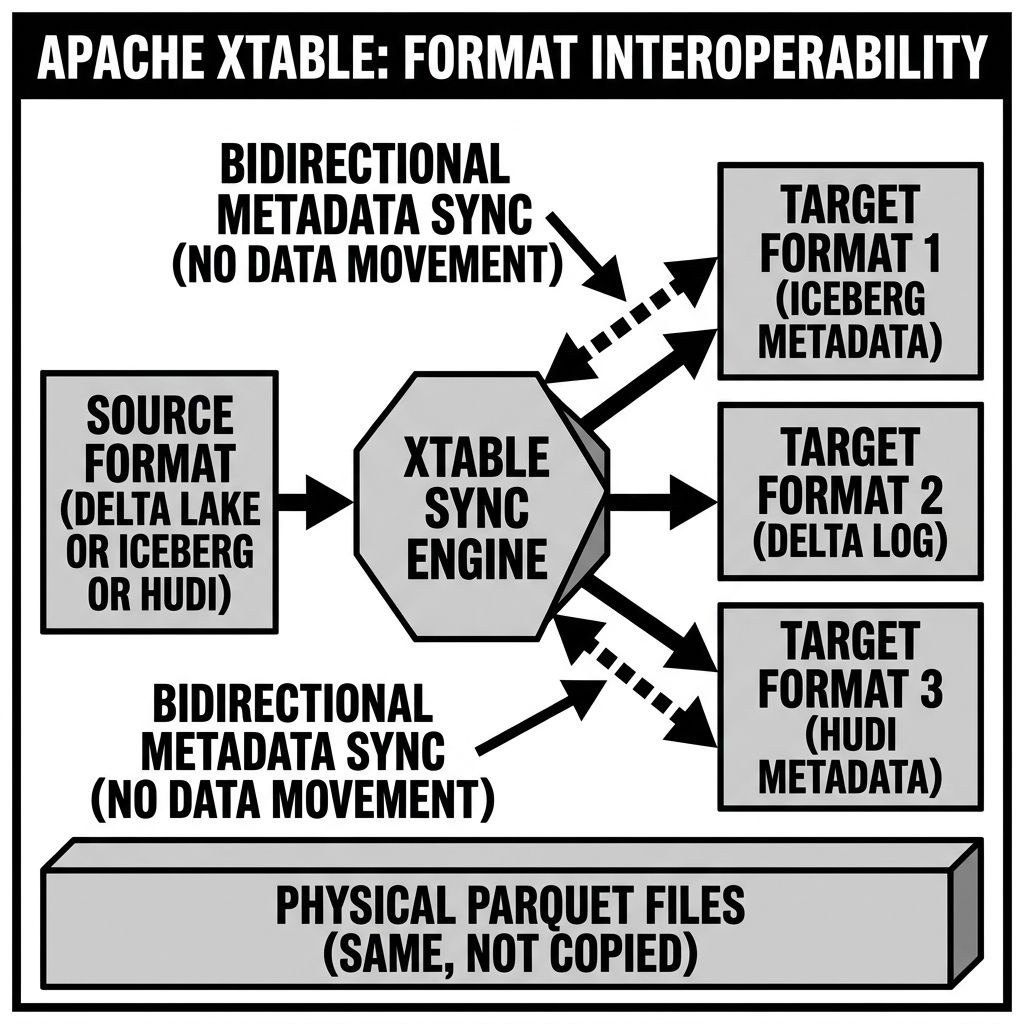
Apache XTable, originally released by Onehouse as “OneTable” and donated to the Apache Software Foundation, represents a fundamentally different category of software from the Open Table Formats it bridges. Apache Iceberg, Delta Lake, Apache Hudi, and Apache Paimon are all table formats — specifications and implementations for how data should be stored and managed on object storage. Apache XTable is not a table format. It is a metadata translation layer: a tool whose sole purpose is to generate, synchronize, and maintain the metadata representations of multiple table formats simultaneously, all pointing to the same underlying Parquet data files.
The emergence of XTable is a direct consequence of the fragmentation that inevitably followed the proliferation of competing Open Table Formats. Organizations that adopted Delta Lake on Databricks found their data stranded from Trino clusters that expected Iceberg. Teams that ran Hudi-based streaming pipelines could not easily share their tables with Snowflake, which reads Iceberg natively. XTable dissolves these silos by separating a crucial architectural reality that was always true but rarely exploited: the physical Parquet data layer and the metadata layer are entirely independent, and there is no technical reason the same set of Parquet files cannot be described simultaneously by multiple metadata representations.
The Fundamental Architecture: Metadata as the Variable, Data as the Constant
All three major Open Table Formats — Iceberg, Delta Lake, and Hudi — share a common structural pattern. They pair:
-
A physical data layer: Parquet (or ORC, or Avro) files stored on object storage. These contain the actual rows and columns of business data. The format of these files is standardized and universally readable.
-
A metadata layer: A set of format-specific index, log, and manifest files that track which physical files exist, what data they contain, how they are partitioned, what schema they conform to, and in what order transactions occurred. This metadata is entirely format-specific and not interchangeable.
The insight that powers XTable is precisely this: the physical Parquet files themselves are perfectly identical regardless of which table format “owns” them. A Parquet file written by a Hudi streaming job is byte-for-byte identical to a Parquet file that Iceberg would have written to store the same data. What differs is only the metadata layer that points to, describes, and tracks those files.
XTable exploits this by maintaining multiple metadata layers — one per target format — all pointing to the exact same set of physical Parquet files. There is no data copying, no ETL transformation, and no storage duplication. Only the lightweight metadata (JSON files, Avro manifests, Parquet log entries) is written multiple times.
The Source-Target Paradigm
XTable operates on a clear Source-Target model:
Source Format: The primary, authoritative table format. This is the format that the write engine uses to commit transactions. All writes go through the source format’s native transaction protocol. The source is the single writer, and its metadata is the ground truth for what physical files exist and when they were committed.
Target Formats: One or more additional formats whose metadata XTable generates and maintains as read-only representations of the same underlying data. These target metadata sets are generated by XTable and should never be written to directly by other tools — they are XTable-owned artifacts.
The choice of source format is a critical architectural decision. It should be the format that your primary write engine supports best and that your write-heavy pipelines produce. If you run a Databricks Spark fleet, Delta Lake is likely the optimal source. If you run Flink streaming pipelines, Hudi might be the better source. If your primary readers are Iceberg-native engines like Dremio, Trino, or Snowflake, Iceberg as the source and Delta or Hudi as targets might be the right configuration.
The Translation Process: Deep Technical Detail
XTable’s translation is an active, ongoing synchronization process, not a one-time migration. It is designed to run continuously alongside the primary write pipeline, keeping all target format metadata synchronized with every new commit in the source format.
Step 1: Source Metadata Ingestion
The XTable process begins by reading the source format’s metadata. For each source format, XTable has a dedicated Source Reader module:
- Hudi Source Reader: Reads the Hudi Timeline from the
.hoodie/directory. It parses the completed commit instants to identify which files were added, which were removed, and the associated partition and column-level statistics for each file. - Delta Source Reader: Reads the
_delta_log/directory. It replays the JSON commit files (starting from the latest checkpoint) to reconstruct the current set of activeaddandremoveentries with their embedded column statistics. - Iceberg Source Reader: Reads the
metadata.jsonpointer file, follows the chain to the active Manifest List, and enumerates all active Manifest Files and their tracked data files.
The output of the Source Reader is a format-neutral, internal representation of the table’s current state: a complete list of all active data files with their paths, partition values, record counts, file sizes, and column-level statistics (min, max, null count).
Step 2: Incremental Change Detection
For ongoing synchronization (as opposed to an initial full-sync), XTable performs incremental change detection rather than re-reading the entire table state on every sync cycle. It tracks the last successfully processed commit (by version number for Delta, by Timeline instant for Hudi, by snapshot ID for Iceberg) and reads only the metadata for commits that occurred after that watermark. This is critical for performance: a busy production table might receive thousands of commits per day, and re-reading the full table state for every sync would be prohibitively expensive.
Step 3: Internal Unified Representation
The Source Reader’s output is a language- and format-agnostic internal data model that represents the canonical state of the table’s active file set. This unified representation includes:
- The complete, current schema in a neutral type system.
- The current partition specification.
- The complete list of active physical file paths with per-file statistics.
- The transaction ordering information (which files were added in which commit order).
This internal model is the “lingua franca” that the Target Writers consume.
Step 4: Target Metadata Generation
For each configured target format, XTable has a dedicated Target Writer module that translates the unified internal representation into format-specific metadata:
- Iceberg Target Writer: Creates or updates Iceberg Manifest Files (one per partition or file batch), groups them into a Manifest List, and writes a new
metadata.jsonfile pointing to the latest Manifest List. The result is a perfectly valid Iceberg table metadata structure, readable by any Iceberg-compatible query engine. - Delta Target Writer: Creates or appends to the
_delta_log/directory, writing a new JSON commit file that lists the current set of active files asaddactions with their statistics. The result is a valid Delta Lake transaction log, readable by any Delta-compatible engine. - Hudi Target Writer: Updates the Hudi Timeline in the
.hoodie/directory to reflect the current set of active files. The result is a valid Hudi table state.
Step 5: Coexistence on Object Storage
After XTable runs, the object storage bucket contains:
- The original source metadata (e.g., Hudi’s
.hoodie/directory). - The generated target metadata (e.g., Iceberg’s
metadata/directory and Delta’s_delta_log/). - The physical Parquet data files (completely unchanged, shared by all formats).
A Trino cluster configured to read Iceberg tables can now point at this bucket and read the Iceberg metadata. A Databricks cluster configured to read Delta tables can point at the same bucket and read the Delta metadata. Both see the same data, with no duplication of the actual Parquet bytes.
Operational Patterns: Full Sync vs. Incremental Sync
XTable supports two operational modes:
Full Sync: XTable reads the complete current state of the source table and generates complete target format metadata from scratch. This is used for the initial bootstrap of a new XTable configuration, or as a recovery mechanism after a detected inconsistency. Full syncs can be slow for large tables with millions of files, as they must enumerate and process all active file metadata.
Incremental Sync: The standard production mode. XTable reads only the metadata for commits that occurred since the last successful sync watermark, computes the delta (files added, files removed), and updates the target format metadata accordingly. Incremental syncs are typically extremely fast — often completing in seconds — and can run continuously alongside the write pipeline.
In practice, XTable is typically configured to run as a separate process (a scheduled Spark job, a Kubernetes sideJob, or a managed cloud service) that executes incremental syncs every few minutes, keeping the target format metadata within a few commits of the source.
The Staleness Problem and Its Implications
A critical operational characteristic of XTable is that target format metadata is always slightly stale relative to the source. Because XTable runs asynchronously after source commits, there is inevitably a lag between when a new source commit is created and when the corresponding target format metadata is updated.
This staleness has direct implications for downstream consumers of the target format metadata. If a Trino Iceberg job reads the table while XTable’s sync is in progress (or before it has caught up to the latest source commit), Trino will see a slightly older version of the data than what the source format’s native readers see.
For most analytical use cases, a lag of one to five minutes is entirely acceptable — the data is recent enough for dashboards, reports, and data science notebooks. However, for use cases requiring strict read-after-write consistency or sub-minute freshness guarantees, XTable’s asynchronous synchronization model is an architectural constraint that must be explicitly accounted for.
XTable vs. Delta UniForm
Delta Lake’s UniForm feature (described in the Delta Lake article) is conceptually similar to XTable but architecturally quite different. UniForm generates Iceberg metadata synchronously, as part of the same Delta commit transaction. This means there is zero lag between a Delta write and the availability of the corresponding Iceberg metadata — the two are atomically consistent.
XTable, by contrast, is asynchronous and format-agnostic. Its key advantages over UniForm are:
- Format Neutrality: XTable supports Hudi as a source, which UniForm does not. If your write pipeline uses Hudi, UniForm is not available; XTable is the only option for multi-format interoperability.
- Bidirectionality: XTable can translate in any direction (Hudi → Iceberg, Iceberg → Delta, Delta → Hudi, etc.). UniForm is strictly Delta → Iceberg.
- Independence from the Write Engine: XTable runs as a separate process, completely decoupled from the write engine. It can be retrofitted onto existing Hudi or Iceberg tables that were not originally configured for multi-format access.
UniForm’s key advantage is synchronous consistency and zero operational overhead for Databricks users already committed to the Delta Lake ecosystem.
Governance Considerations
When using XTable in production, the target format metadata directories must be treated as XTable-owned, read-only artifacts. If another tool accidentally writes a Delta commit or an Iceberg snapshot directly to the target metadata directories — bypassing XTable’s control — the consistency between the source and target representations will be broken. XTable’s incremental sync will attempt to reconcile the discrepancy, but depending on the nature of the out-of-band write, this can result in unrecoverable metadata corruption.
Clear operational governance is required: the source format is the only write-enabled format; all other formats are read-only XTable artifacts. Downstream teams must be educated and prevented (through IAM policies on the metadata directories if possible) from using native writers against the target format metadata.
Conclusion
Apache XTable occupies a unique and valuable position in the Open Table Format ecosystem. It is the only tool that provides true format-neutral, bidirectional, data-free interoperability across all major Open Table Formats. For organizations navigating the reality of multi-format, multi-team data lakehouses — where historical format decisions have created isolated silos — XTable provides the most pragmatic path to a unified, universally accessible data layer without the cost and complexity of wholesale data migration. Its asynchronous, metadata-only translation model is both its primary strength (low cost, no data duplication) and its primary constraint (inherent staleness). Understanding this trade-off is essential to deploying XTable responsibly in production.
Visual Architecture