Avro Format
While Apache Parquet dominates the landscape of analytical data storage, it is not the only file format found in a modern data lakehouse. Apache Avro plays a highly specialized, absolutely critical role in big data architectures.
Unlike Parquet, which is a columnar format optimized for reading specific columns across massive datasets, Apache Avro is a row-based format. It is optimized for writing entire records as fast as possible.
Because of its row-based nature and its unique approach to schema management, Avro is the undisputed king of two specific domains: real-time streaming data ingestion and storing complex metadata.
The Architecture of an Avro File
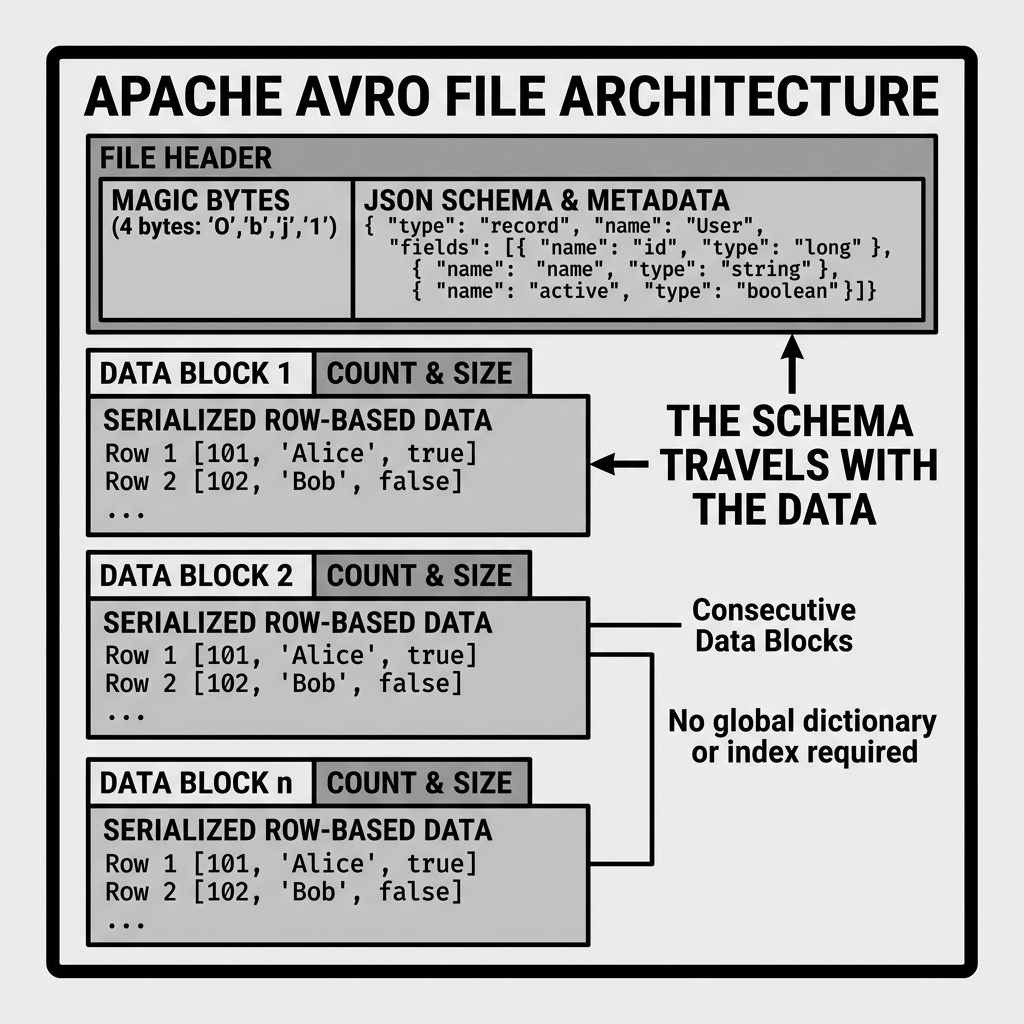
The defining feature of Apache Avro is that the schema travels with the data.
In an Avro file, the very first thing written to the file header is the complete schema, defined in JSON. Following the header are blocks of serialized, binary row data.
This design solves a massive problem in distributed systems. If a producer (like a microservice) sends an Avro message to a Kafka topic, and a consumer (like a Spark Streaming job) picks it up a week later, the consumer does not need to look up the schema in an external registry to understand the message. The schema is embedded right inside the file.
Furthermore, Avro uses binary serialization. It is incredibly compact compared to plain text JSON or CSV. Because it writes row by row, appending a new record to an Avro file is an extremely lightweight, fast operation, making it ideal for high-throughput streaming systems.
Diagram 1: Avro File Architecture
Avro in the Data Lakehouse
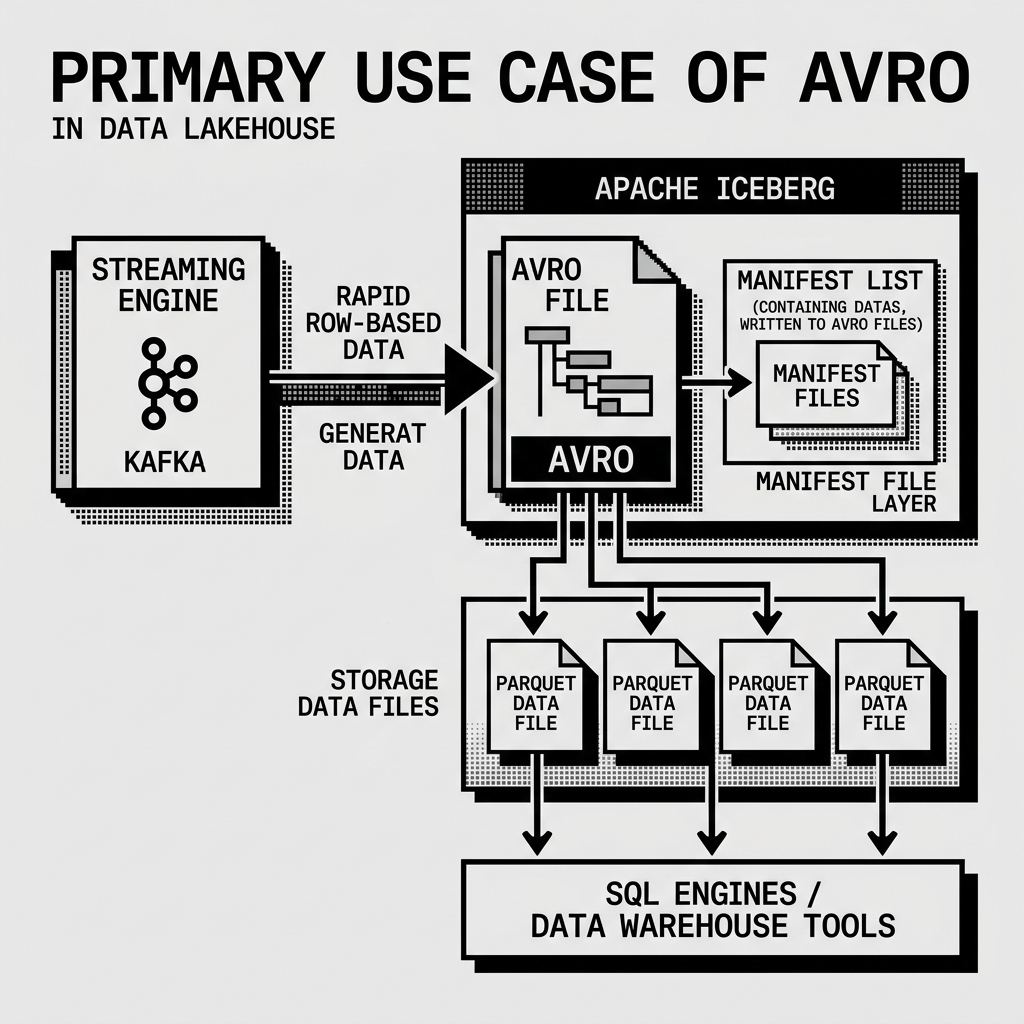
If you look closely at an Apache Iceberg table, you will notice that the actual raw data files are usually Parquet files. However, the Manifest Lists and Manifest Files are always Avro files.
Why did the creators of Iceberg choose Avro for the metadata?
- Row-Level Operations: A Manifest File is essentially a list of pointers to Parquet files. When Iceberg creates a new snapshot, it needs to quickly write a new Manifest File containing thousands of rows (each row being a file pointer). A row-based format like Avro writes these complete records much faster than a columnar format.
- Schema Evolution: Avro is famous for its robust schema evolution rules. It handles missing fields, added fields, and data type changes gracefully. Because Iceberg metadata evolves over time, Avro’s strict but flexible schema enforcement guarantees that old metadata files can always be read by newer Iceberg clients.
- Read Completeness: When an engine reads a Manifest File, it usually needs to read all the columns in that record (the file path, the min stats, the max stats, the null counts). Columnar formats are beneficial when you only want to read one or two columns and skip the rest. If you need to read every column in a row, a row-based format like Avro is actually faster to deserialize.
Diagram 2: Avro’s Role in the Lakehouse
Parquet vs. Avro
The general rule in data engineering is: Write with Avro, Read with Parquet.
If you are pulling real-time telemetry from thousands of IoT devices via Apache Kafka, you serialize that data into Avro. It handles the massive write throughput without breaking a sweat.
However, once that data lands in the data lakehouse, a batch job (often running on Spark or Flink) will read those Avro files and convert them into Parquet files. This conversion prepares the data for analytical workloads, where BI dashboards and SQL engines can leverage Parquet’s columnar compression and predicate pushdown to execute blazing-fast aggregations.