AWS Glue Data Catalog
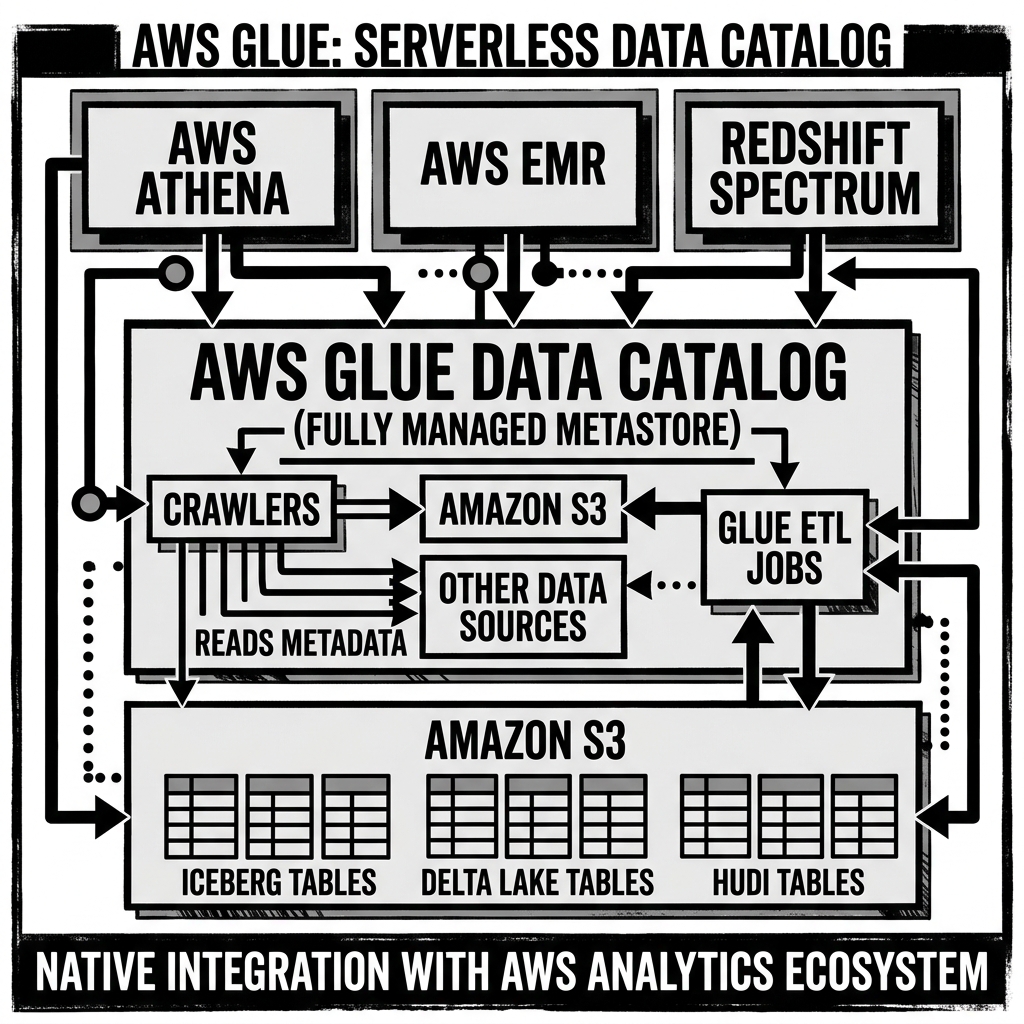
The AWS Glue Data Catalog is Amazon Web Services’ fully managed, serverless metadata catalog service — the central metadata registry for the entire AWS analytics ecosystem. It provides persistent, scalable storage for table definitions, schema metadata, partition information, and (for Apache Iceberg tables) the critical metadata pointer that enables atomic commits and consistent reads.
Unlike the Hive Metastore (which requires provisioning and managing a JVM service and a relational database backend) or Apache Polaris (which requires deploying and operating a Java service), the Glue Data Catalog is entirely serverless: there is no catalog infrastructure to provision, no service to monitor, no database to back up, and no capacity to plan. Organizations simply use the Glue API to register tables, and Glue handles the storage, availability, and scalability of the metadata service automatically. This operational simplicity makes the Glue Data Catalog the most common catalog choice for AWS-native data lakehouse deployments, and the default catalog for Amazon Athena, AWS Glue ETL, Amazon EMR, and Amazon Redshift Spectrum.
The Glue Data Catalog Architecture
The Metadata Storage Model
The Glue Data Catalog stores metadata as a hierarchy of objects:
Databases: Top-level organizational units within the catalog. A Glue database corresponds to an Iceberg namespace and groups related tables together.
Tables: The central metadata object. Each Glue table record stores:
- The table name and parent database.
- The table’s physical storage location (the S3 URI of the table’s root directory).
- The table type (EXTERNAL_TABLE for Iceberg and other Open Table Format tables).
- The table’s schema (column names and types, represented in Glue’s own type system).
- The SerDe (serialization/deserialization) library configuration (for Hive-format tables) or Iceberg-specific parameters.
- For Iceberg tables: the
metadata_locationtable parameter pointing to the currentmetadata.jsonfile on S3. - For Hive-partitioned tables: the partition scheme specification.
Partitions: For Hive-format tables, individual partition records storing the partition key values and partition-specific storage locations.
Table Parameters: Key-value metadata properties attached to tables. For Iceberg tables, the most critical parameter is metadata_location, which Glue updates with each new Iceberg commit.
The API Layer
The Glue Data Catalog is accessed through two API surfaces:
AWS SDK / Glue API: The native Glue API, accessible through the AWS SDKs for Python (boto3), Java, Go, and other languages. The Glue API exposes operations like CreateTable, GetTable, UpdateTable, BatchCreatePartition, and GetPartitions. This API is used by AWS services (Glue ETL jobs, Glue Crawlers, Lake Formation, Athena) and by Iceberg catalog clients configured to use the Glue catalog backend.
Apache Hive Metastore (HMS) Thrift API emulation: Glue provides an HMS-compatible Thrift endpoint that allows Spark and other Hive-compatible engines to connect to Glue using the standard Hive Metastore client protocol. This compatibility layer allows existing Spark configurations that use spark.sql.catalogImplementation=hive and hive.metastore.uris=thrift://... to work with Glue by simply pointing the Thrift URI at the Glue endpoint.
Iceberg REST Catalog API: Glue now exposes an Iceberg REST Catalog-compatible endpoint, allowing any Iceberg REST Catalog client to connect directly to Glue without the engine-specific Glue connector. This REST API endpoint enables Trino, Flink, and other engines that support the Iceberg REST Catalog protocol to use Glue as their catalog backend without writing Glue-specific connector code.
Serverless Scaling and Availability
The Glue Data Catalog is backed by AWS’s internal distributed systems infrastructure, providing:
- Automatic scaling: The catalog handles thousands of concurrent API calls without any capacity planning by the user.
- Cross-region replication: Glue metadata is durably stored with multiple-availability-zone redundancy within each AWS region.
- No provisioned capacity: There are no nodes, servers, or database instances to manage. Glue charges per API call (read and write operations), not per provisioned capacity.
- Built-in versioning: Glue tracks table schema versions, allowing administrators to view and revert to previous schema definitions.
Iceberg Integration with AWS Glue
Glue’s Iceberg catalog integration works through the metadata_location table parameter pattern, identical to the HMS integration:
When an Iceberg table is created with Glue as its catalog:
- The Iceberg engine writes the initial
metadata.jsonto S3. - The engine calls the Glue
CreateTableAPI withmetadata_locationset to the newmetadata.jsonURI. - The table is registered in Glue.
When an Iceberg writer commits a new table state:
- The writer writes new Iceberg metadata files (Manifest Files, Manifest List, new
metadata.json) to S3. - The writer calls
UpdateTable(or a Glue-native Iceberg commit API, depending on the engine’s Glue connector implementation) to update themetadata_locationto the newmetadata.jsonURI. - Glue’s underlying storage performs a conditional update to ensure the commit is atomic — verifying the
metadata_locationhasn’t changed since the writer began, then updating it to the new value.
The critical technical detail of Glue’s Iceberg commit protocol is that Glue uses its own internal conditional update mechanism (not exposed to users as a compare-and-swap API) to ensure that the metadata_location update is atomic. This prevents concurrent writers from simultaneously corrupting the table’s metadata pointer, providing the same ACID commit guarantee as HMS’s lock-based approach but without requiring a distributed lock service.
Glue Crawlers and Schema Discovery
AWS Glue Crawlers are automated schema discovery jobs that scan S3 data and automatically register or update table definitions in the Glue Data Catalog. Crawlers support Iceberg, Delta Lake, Hudi, Parquet, ORC, CSV, and JSON formats.
For Iceberg tables, the Glue Crawler reads the table’s Iceberg metadata (starting from the metadata.json) and registers the current schema and partition spec in the Glue catalog. Crawlers can be scheduled (hourly, daily) to automatically update Glue metadata as tables evolve, without requiring manual schema registration.
For unmanaged data (S3 directories containing Parquet or CSV files without Open Table Format metadata), Crawlers perform schema inference by sampling data files and registering inferred schemas. This automatic discovery is one of Glue’s most valuable operational features for teams ingesting data from external sources.
AWS Lake Formation: The Governance Layer
The AWS Glue Data Catalog, by itself, provides no access control. Any IAM principal with Glue API permissions can read or modify any table in the catalog. Fine-grained access control for Glue-managed data is provided by AWS Lake Formation, which sits as a governance layer on top of the Glue Data Catalog.
Lake Formation’s Data Permissions Model
Lake Formation extends IAM with a data-specific permissions model:
Database permissions: CREATE TABLE, DROP, DESCRIBE, ALTER — controlling who can create and modify database objects.
Table permissions: SELECT, INSERT, DELETE, DESCRIBE, ALTER, DROP — controlling who can read, write, and modify specific tables.
Column-level permissions: Lake Formation can grant SELECT on specific columns of a table, restricting users to reading only the columns they are authorized to see. Users without column permission will see those columns as NULL.
Row-level security: Lake Formation Data Filters allow administrators to define SQL WHERE conditions that restrict which rows a specific IAM role can access. A data filter WHERE region = 'EU' applied to a role means users in that role only see EU rows when querying the table, regardless of the query they submit.
Cell-level security: The combination of column-level and row-level permissions provides cell-level security, ensuring that specific users see only specific rows AND specific columns of sensitive tables.
Lake Formation and Credential Vending
Lake Formation integrates with the Glue Iceberg REST Catalog endpoint to provide credential vending for Iceberg tables. When an external engine (Spark, Trino) accesses an Iceberg table through the Glue REST Catalog endpoint, Lake Formation:
- Validates the caller’s IAM identity.
- Evaluates Lake Formation data permissions for the requested table.
- Generates temporary S3 credentials (AWS STS tokens) scoped to the table’s S3 prefix.
- Returns the scoped credentials alongside the Iceberg table metadata.
The Lake Formation “hybrid access mode” allows organizations to gradually migrate from IAM-based S3 bucket permissions to fine-grained Lake Formation permissions, supporting mixed environments where some tables are governed by Lake Formation and others by IAM during the transition period.
Managed Table Optimization for Iceberg
One of Glue’s most operationally significant Iceberg features is managed table optimization — built-in, fully managed compaction, snapshot expiry, and orphan file cleanup for Iceberg tables in Glue.
Automatic Compaction
When enabled, Glue automatically runs compaction on Iceberg tables to merge small files into optimally sized files (128–512MB target file sizes). The compaction job runs in the background, using Glue-managed EMR Serverless infrastructure, without requiring any user action or compute provisioning.
Configuration:
{
"TableOptimizerConfiguration": {
"Enabled": true,
"RoleArn": "arn:aws:iam::account:role/GlueOptimizerRole"
}
}The optimizer role needs IAM permissions to read and write the table’s S3 storage location. Once configured, Glue monitors the table’s file size distribution and triggers compaction automatically when small file proliferation degrades query performance.
Snapshot Expiry and Orphan File Cleanup
Glue also manages automatic snapshot expiry (removing old Iceberg snapshots beyond the retention window) and orphan file cleanup (removing unreferenced Parquet files left by failed write operations). These operations are also fully managed — Glue determines when to run them based on the table’s commit history and file inventory, without requiring user-scheduled maintenance jobs.
The Glue Data Catalog’s Position in the AWS Analytics Stack
The Glue Data Catalog is the central metadata hub for the entire AWS analytics ecosystem:
Amazon Athena: Athena uses Glue as its default catalog. Every Athena SQL query resolves table names against Glue. Athena natively supports Iceberg DDL (CREATE TABLE, ALTER TABLE, time travel queries) directly against Glue-registered Iceberg tables.
AWS Glue ETL: Glue’s serverless Spark-based ETL service reads and writes to Iceberg tables registered in Glue, using the Glue catalog client for metadata coordination.
Amazon EMR: EMR Spark, Flink, and Trino clusters can be configured to use Glue as their Hive Metastore (via the Glue Hive Metastore compatibility layer), enabling seamless access to Glue-registered Iceberg and Hive tables.
Amazon Redshift Spectrum: Redshift Spectrum can query external tables registered in Glue, enabling Redshift users to join Redshift-native tables with Glue-registered S3-backed Iceberg tables in a single SQL query.
Amazon SageMaker Feature Store: SageMaker’s offline feature store uses Glue to register feature table metadata, enabling Athena and other engines to query feature data stored in S3.
Limitations and Trade-offs
AWS vendor lock-in: The Glue Data Catalog is a proprietary AWS service. Tables registered in Glue are not portable to non-AWS environments without additional catalog migration tooling. Organizations that anticipate moving to multi-cloud or hybrid cloud deployments should evaluate the portability implications of Glue dependency.
API rate limits: Glue imposes per-account API rate limits for catalog operations (reads, writes, partition listings). High-frequency ETL pipelines that commit to many tables simultaneously can encounter rate limiting, requiring backoff and retry logic.
Limited REST Catalog feature coverage: While Glue’s Iceberg REST Catalog endpoint provides basic compatibility, it may not implement the full feature set of the REST Catalog specification (e.g., advanced multi-table commit operations) available in purpose-built REST Catalog implementations like Polaris.
No native branching or versioning: Unlike Nessie, Glue has no concept of catalog branches, tags, or versioned catalog state. All tables have a single current state.
Conclusion
The AWS Glue Data Catalog is the most operationally simple and AWS-integrated catalog option for organizations building data lakehouses on Amazon S3. Its serverless architecture eliminates catalog infrastructure management entirely, its native integration with Athena, EMR, Glue ETL, and Redshift Spectrum makes it the zero-friction catalog for AWS-native analytics, and its managed table optimization features (automatic compaction, snapshot expiry, orphan file cleanup) reduce lakehouse maintenance overhead significantly. Its emerging Iceberg REST Catalog API compatibility positions it as increasingly interoperable with non-AWS engines. For organizations deeply invested in the AWS ecosystem that do not require multi-cloud portability, Git-like catalog versioning, or the advanced RBAC capabilities of Polaris or Unity Catalog, the Glue Data Catalog is the natural, lowest-friction choice for their lakehouse catalog infrastructure.
Visual Architecture