Azure Blob Storage
Azure Blob Storage is Microsoft’s massively scalable object storage solution for the cloud. Designed to store massive amounts of unstructured data (like text or binary data), it is the foundational storage layer for applications running on the Azure cloud. Within the context of big data analytics and the open data lakehouse, Azure extends standard Blob Storage with a critical feature set known as Azure Data Lake Storage (ADLS) Gen2, bridging the gap between traditional object storage and high-performance file systems.
Standard Azure Blob Storage
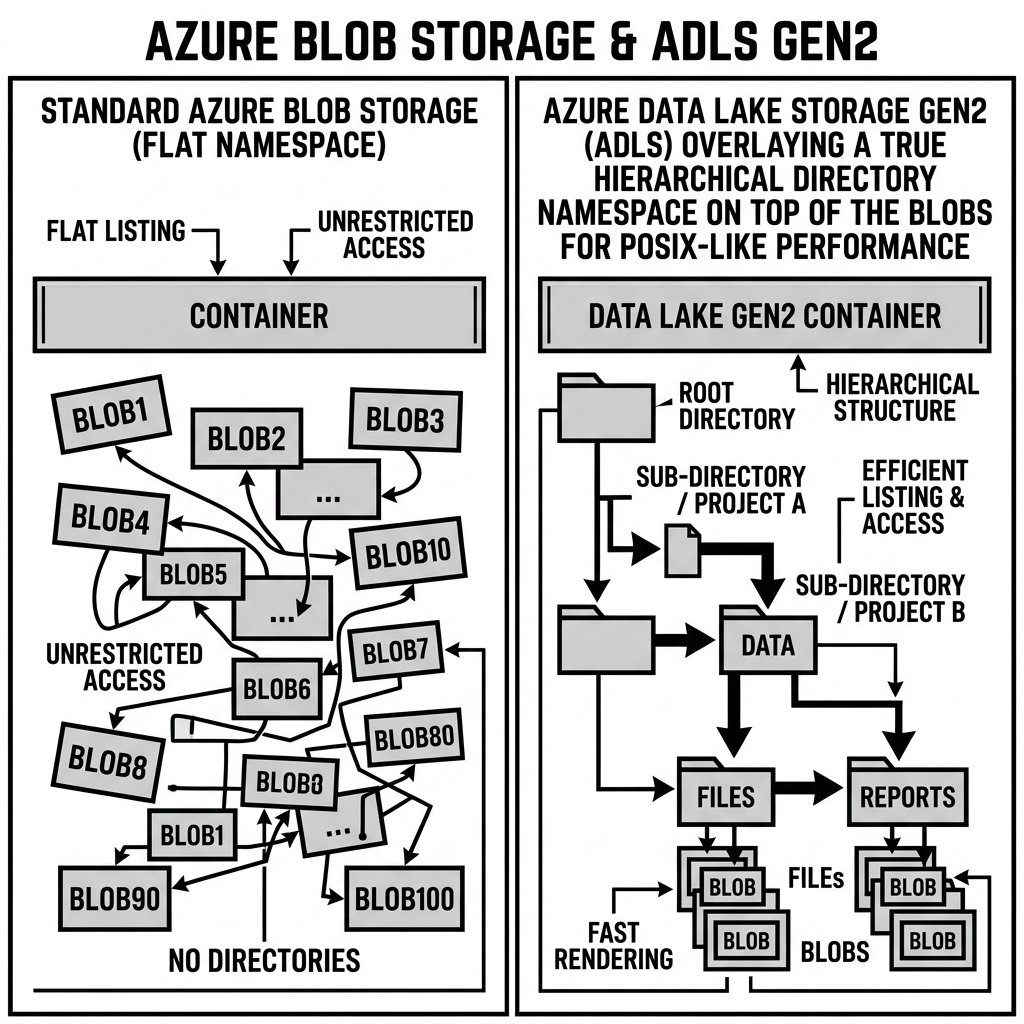
Like Amazon S3 and Google Cloud Storage, standard Azure Blob Storage utilizes a flat namespace. Data is stored as objects (blobs) within containers. It provides HTTP/REST access, infinite scalability, lifecycle management to move data to cooler, cheaper tiers (Hot, Cool, Archive), and massive durability through geo-redundant storage (GRS) options.
However, standard object storage possesses inherent weaknesses when executing complex big data workloads (like Apache Spark or Hadoop jobs). Because the namespace is flat, “directories” do not actually exist; they are merely prefixes in the object’s name (e.g., folder1/folder2/file.txt).
If a Spark job needs to rename a directory containing a million files (a common operation during commit phases in traditional Hadoop architectures), standard object storage cannot simply rename the parent folder. It must physically copy all one million individual files to a new prefix location and delete the old ones. This process is incredibly slow, consumes massive network bandwidth, and frequently causes big data pipelines to fail or stall.
Azure Data Lake Storage (ADLS) Gen2
To solve the performance issues of standard object storage for analytics, Microsoft introduced Azure Data Lake Storage Gen2. ADLS Gen2 is not a separate storage service; rather, it is a set of big data capabilities built directly on top of Azure Blob Storage.
The defining feature of ADLS Gen2 is the introduction of a true Hierarchical Namespace (HNS).
When a storage account is enabled with HNS, Azure overlays a POSIX-compliant file system on top of the object storage layer. Directories are now real, first-class entities, not just simulated prefixes. This provides several massive advantages for data lakehouse architecture:
1. Atomic Directory Operations: If a Spark job needs to rename a directory, ADLS Gen2 performs a single, atomic metadata update. Renaming a folder with a million files takes milliseconds instead of hours. This dramatically accelerates ETL pipeline execution times.
2. POSIX-compliant Access Control: Standard object storage relies on complex IAM policies applied at the container or object prefix level. ADLS Gen2 allows organizations to apply POSIX-like access control lists (ACLs) directly to files and directories, similar to a local Linux file system. This provides incredibly granular security, allowing administrators to restrict access to specific folders within a lakehouse at a granular level.
3. Hadoop Compatible File System (HDFS) Driver: ADLS Gen2 provides an ABFS (Azure Blob File System) driver that allows big data frameworks (like Hadoop, Spark, and Trino) to interact with the storage exactly as if it were a native HDFS cluster, ensuring seamless compatibility and optimized performance.
Integration in the Lakehouse
ADLS Gen2 is the preferred storage backend for modern lakehouse architectures deployed on Azure. When using Azure Databricks or Microsoft Fabric, the underlying data (stored in Delta Lake or Apache Iceberg formats) is residing in ADLS Gen2.
The hierarchical namespace makes managing these open table formats highly efficient. While modern table formats like Iceberg do not rely on directory renaming for atomic commits (they use metadata pointers instead), the underlying file system semantics provided by ADLS Gen2 still accelerate operations like directory listing and granular permission management.
Furthermore, Microsoft has heavily integrated ADLS Gen2 with Azure Synapse Analytics and Microsoft Purview, providing a cohesive ecosystem where data can be stored efficiently, queried rapidly via serverless SQL pools, and governed centrally through data cataloging.
Summary and Tradeoffs
Azure Blob Storage, empowered by ADLS Gen2, provides a unique and highly performant storage foundation for the data lakehouse. By combining the infinite scalability and low cost of object storage with the performance and directory semantics of a hierarchical file system, Microsoft solved many of the most frustrating bottlenecks associated with cloud-based big data pipelines.
The primary tradeoff when using Azure Blob Storage is ensuring that ADLS Gen2 (the Hierarchical Namespace) is explicitly enabled when creating the storage account intended for analytics. Enabling HNS incurs a slightly different pricing structure for API calls, as file system operations require more complex metadata management behind the scenes. However, for any workload involving Apache Spark, Trino, or open table formats, the massive performance gains in job execution and directory manipulation far outweigh the minor differences in API costs, making ADLS Gen2 an absolute necessity for Azure-based data engineers.
Visual Architecture