Bronze Layer
In the Medallion Architecture that structures modern data lakehouses, data does not simply arrive and immediately become analytically ready. It passes through a series of progressive refinement stages, each adding a layer of quality, governance, and business context. The Bronze Layer is the first and most foundational of these stages. It is the point of entry, the place where all data from all sources lands when it first arrives in the lakehouse.
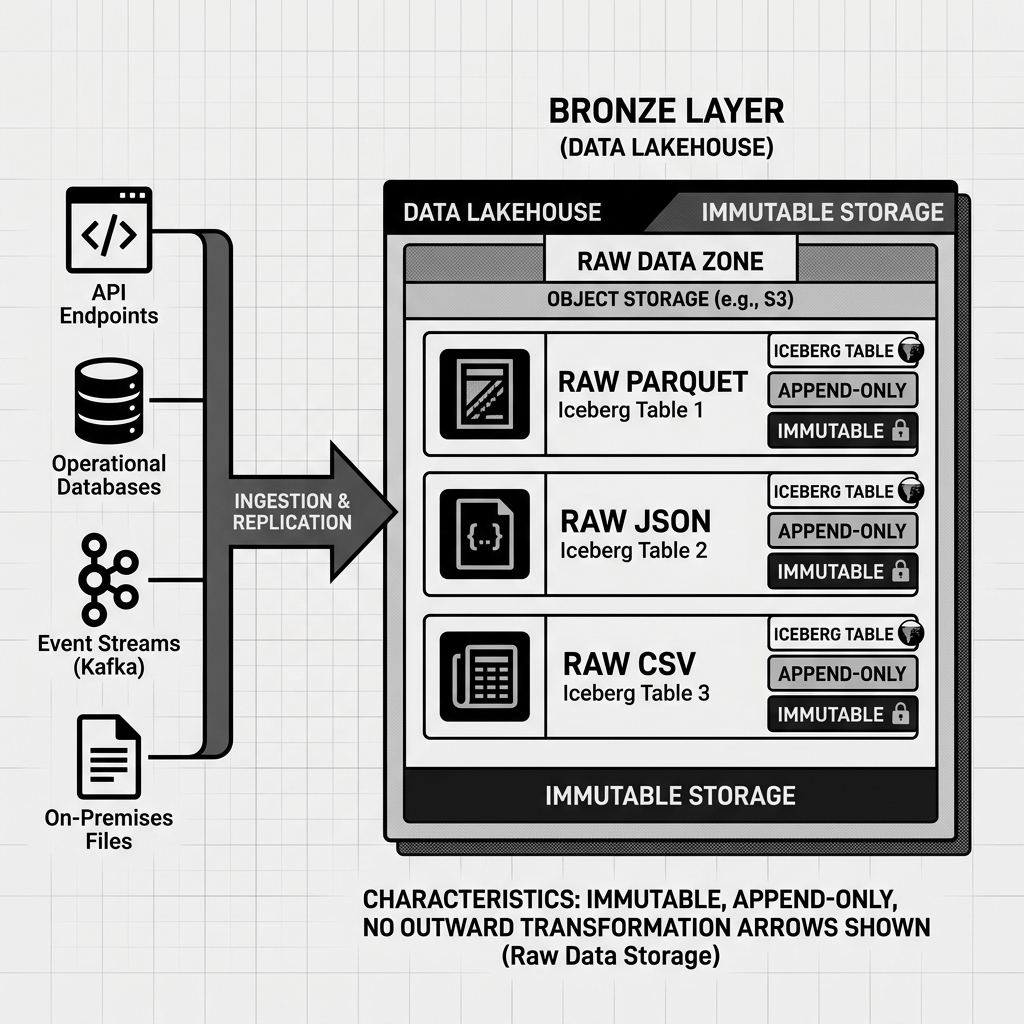
The defining characteristic of the Bronze Layer is complete source fidelity. Data in the Bronze Layer is stored exactly as it arrived from the source system. No cleaning, no transformation, no schema enforcement, no deduplication. If the source API sends a malformed JSON record with a null in a required field, that malformed record is stored in Bronze. If the source system uses inconsistent date formats between different versions of its export, both formats exist side by side in Bronze. The Bronze Layer is an honest, uncorrupted mirror of everything the source systems have emitted.
This commitment to raw preservation is not laziness on the part of the data engineering team. It is a deliberate architectural decision with significant long-term operational benefits.
Why Raw Preservation Matters
The most important operational benefit of the Bronze Layer’s raw storage approach is historical reprocessability. Suppose a data engineering team builds a Silver-layer transformation pipeline that cleanses and models customer order data. Six months later, the finance team discovers that the revenue calculation in the Silver layer has been slightly wrong since the beginning because of an incorrect handling of refunded orders.
Without a Bronze Layer, fixing this problem requires going back to the source system and re-extracting six months of historical order data, which may not even be possible if the source system only retains a rolling window of records. With a Bronze Layer, the fix is straightforward: correct the Silver-layer transformation logic and rerun it against the existing Bronze data. The full six-month history of raw order records is right there, untouched, exactly as they arrived.
The Bronze Layer also serves as an audit trail. Regulatory requirements in industries like finance and healthcare often require organizations to demonstrate exactly what data they received from third parties and when. Because Bronze tables are append-only and immutable, they provide a tamper-evident log of all ingested data with precise ingestion timestamps. This satisfies compliance requirements that would be impossible to meet if data were transformed and the original records discarded.
Diagram 1: Bronze Layer Architecture
Designing Bronze Tables
Designing Bronze tables requires resisting the instinct to clean and structure data prematurely. The schema of a Bronze table should be minimal and flexible, reflecting the shape of the source data rather than the desired shape of the analytical output.
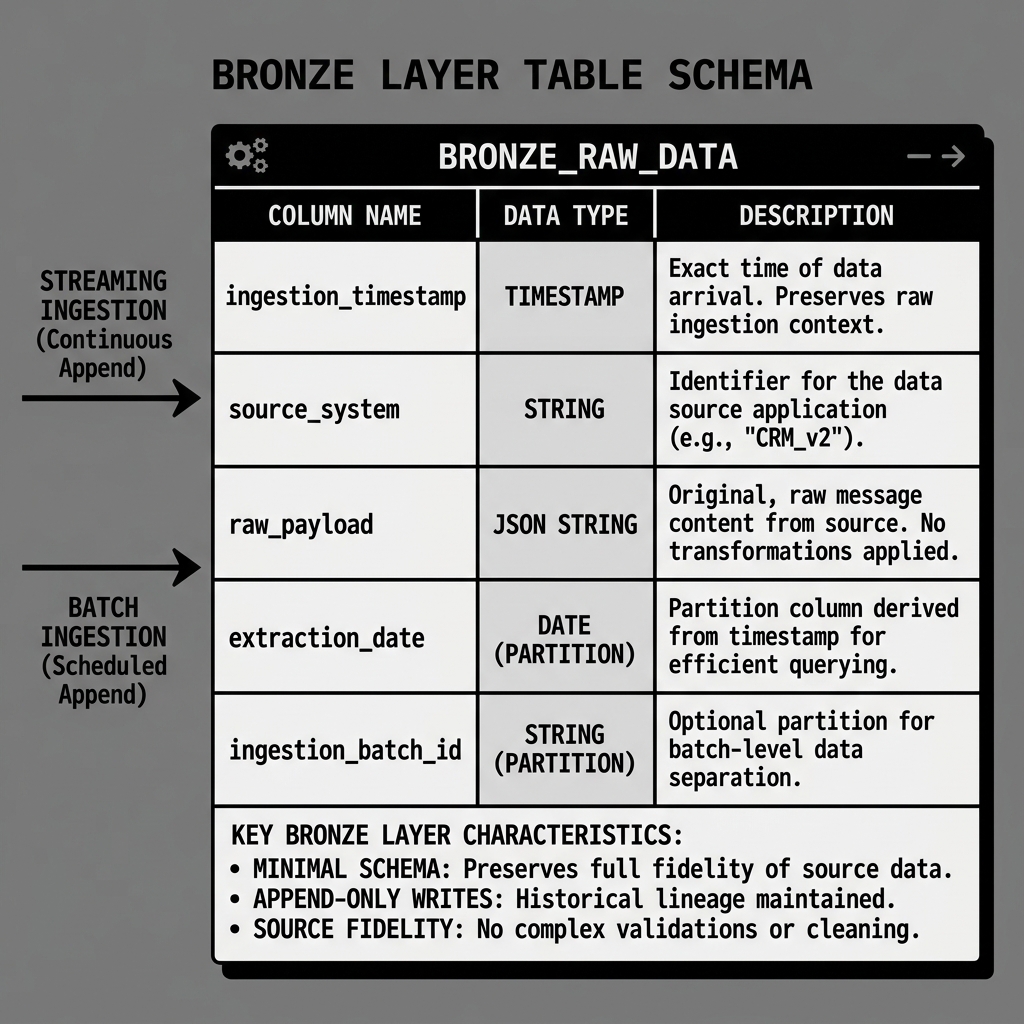
A common pattern for Bronze tables that receive semi-structured data (such as JSON events from a web application) is to store each event as a single STRING or VARIANT column containing the raw JSON payload, alongside a small set of system-generated metadata columns: ingestion_timestamp recording when the record arrived in the lakehouse, source_system identifying the system that produced the record, and ingestion_batch_id linking the record to the specific pipeline run that ingested it.
For more structured sources, such as database exports from PostgreSQL or MySQL, Bronze tables can have more explicit column definitions that mirror the source table schema. Even so, the data types should be as permissive as possible. Numeric columns that occasionally arrive as strings should be stored as strings in Bronze, allowing the Silver layer to handle the conversion and error handling explicitly.
Partitioning Bronze tables by ingestion_date (derived from ingestion_timestamp) is standard practice. This makes it efficient for Silver-layer transformation jobs to perform incremental processing by reading only the partitions that contain records ingested since the last transformation run, rather than scanning the entire Bronze table.
Diagram 2: Bronze Layer Table Schema
Access Patterns and Governance
The Bronze Layer is not generally accessible to business analysts or data scientists for ad-hoc querying. Access is restricted to automated ingestion pipelines (which write to it) and data engineering pipelines (which read from it for Silver-layer processing). This access restriction serves two purposes.
First, Bronze data is not trustworthy for analytical use. It contains duplicates, nulls, schema inconsistencies, and occasionally corrupted records. An analyst who queries Bronze directly and builds a business report on the results is building on an unreliable foundation. Restricting access to Bronze prevents this misuse.
Second, open access to Bronze creates a compliance risk. Bronze tables often contain raw PII, financial records, or other sensitive data in its original, unmasked form. Only after the Silver-layer transformation has applied the appropriate masking and tokenization should data become accessible to a broader audience.
Despite these access restrictions, the Bronze Layer’s existence is what makes the entire Medallion Architecture trustworthy. The Silver and Gold layers can be confidently rebuilt from scratch at any time because the Bronze Layer guarantees that the source truth is permanently preserved. This guarantee is the bedrock of data quality in a modern data lakehouse.