ClickHouse
ClickHouse is an open-source, column-oriented database management system (DBMS) built expressly for online analytical processing (OLAP). Developed initially by Yandex to power Yandex.Metrica (the world’s second-largest web analytics platform), ClickHouse is renowned across the industry for its extreme query execution speed. By aggressively leveraging hardware capabilities, data compression, and specialized indices, ClickHouse can query billions of rows in milliseconds, making it a dominant force for real-time analytics, monitoring, and telemetry data.
Core Definition
The core philosophy of ClickHouse is simple: do not waste hardware resources. Traditional databases, even many analytical ones, often incur massive overhead from object abstractions, locking mechanisms, and inefficient memory management. ClickHouse strips away these abstractions. It is written in C++ and interacts directly with the operating system and hardware.
As a column-oriented database, ClickHouse stores data sequentially by column rather than by row. When a user executes a query to calculate the average of a specific column, ClickHouse only reads the exact bytes associated with that column from the disk. This drastically reduces disk I/O, which is typically the primary bottleneck in analytical workloads.
Furthermore, storing data by column allows for extremely efficient data compression. Because values in a single column are often highly repetitive or similar (e.g., a column of timestamps or status codes), ClickHouse employs specialized compression algorithms like LZ4 and Zstandard to reduce the data footprint on disk by a factor of ten or more. This compression not only saves storage costs but also significantly speeds up queries, as the CPU can decompress data faster than the disk can read uncompressed data.
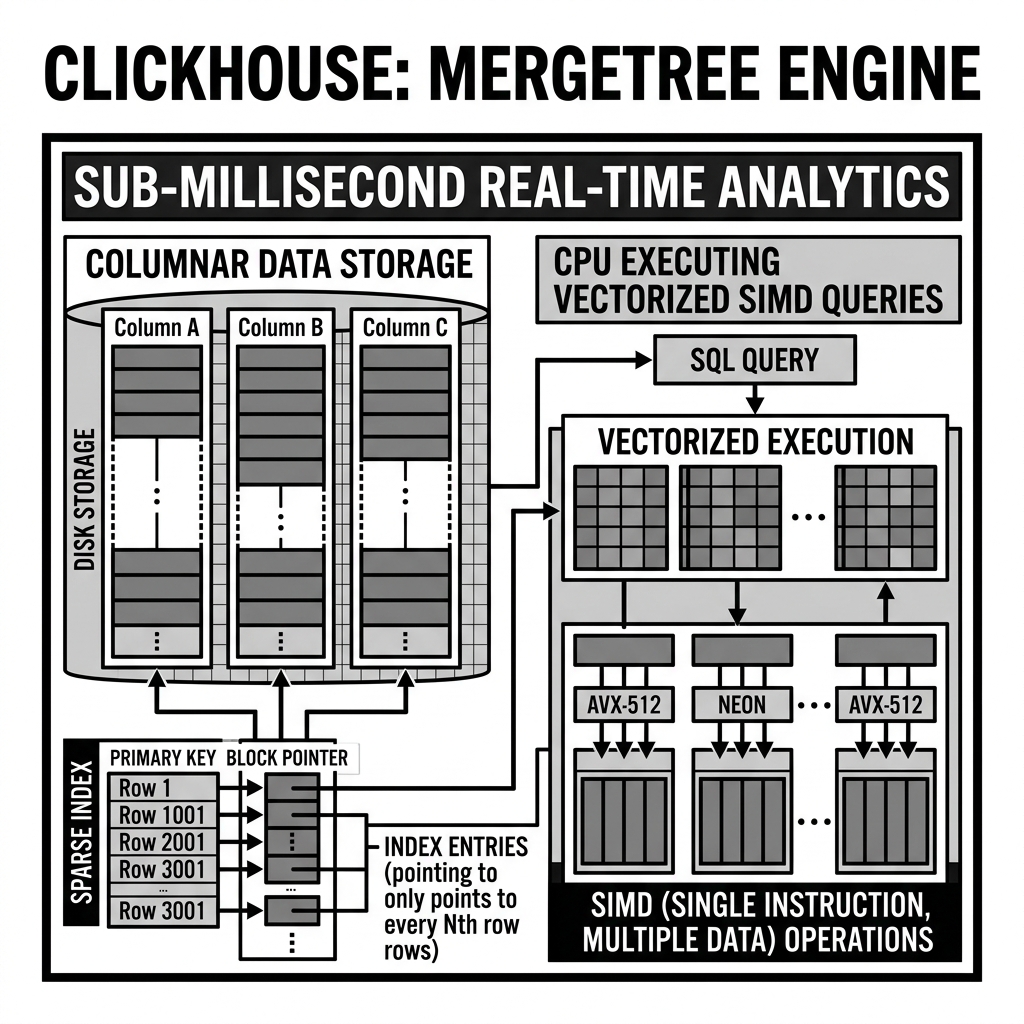
The engine also relies heavily on vectorized query execution. Similar to StarRocks, ClickHouse processes data in blocks (vectors) rather than individual rows. This allows the engine to utilize SIMD (Single Instruction, Multiple Data) instructions, enabling the CPU to process multiple data points simultaneously within a single clock cycle.
Architecture and Components
ClickHouse utilizes a shared-nothing architecture, meaning that each node in a ClickHouse cluster operates independently with its own CPU, memory, and disk storage. Nodes communicate with each other during distributed query execution but do not rely on a central master node for basic operations, eliminating single points of failure.
The defining characteristic of ClickHouse’s architecture is its reliance on the MergeTree family of table engines. The MergeTree engine is the heart of ClickHouse and dictates how data is stored, indexed, and retrieved.
When data is written to a MergeTree table, it is not immediately appended to existing files. Instead, ClickHouse writes the data to a new, small “part” on the disk and immediately acknowledges the write. In the background, ClickHouse constantly merges these smaller parts into larger, optimized parts. This Log-Structured Merge (LSM) tree approach allows ClickHouse to accept massive write throughput—millions of rows per second—without blocking or slowing down read queries.
Data within a MergeTree part is strictly sorted based on an ORDER BY key defined during table creation. ClickHouse uses this sorted structure to build a sparse primary index. Unlike a B-Tree index in a traditional relational database, which stores a pointer for every single row, a sparse index only stores a pointer for every Nth row (the index granularity, typically every 8192 rows). Because the data is physically sorted, ClickHouse can use the sparse index to rapidly locate the specific chunk of rows required for a query, loading the entire block into memory and scanning it in microseconds.
Integration with the Data Lakehouse
Historically, ClickHouse was primarily utilized as a standalone data silo; data had to be explicitly ingested from external sources into ClickHouse’s internal MergeTree format to achieve fast query speeds. However, as the open data lakehouse pattern has matured, ClickHouse has rapidly expanded its integration capabilities.
ClickHouse introduces the concept of Integration Engines. These engines allow ClickHouse to directly query external data sources without copying the data into local storage. ClickHouse provides native integration engines for Apache Iceberg, Delta Lake, and Apache Hudi.
When an analyst issues a SQL query in ClickHouse targeting an external Iceberg table located on Amazon S3, the ClickHouse engine retrieves the Iceberg metadata, evaluates the partition pruning logic, and dispatches highly optimized, parallel HTTP requests to S3 to fetch only the necessary Parquet or ORC data chunks.
While querying data directly from S3 will inherently be slower than querying data stored on local NVMe SSDs in the native MergeTree format, ClickHouse’s highly parallelized C++ execution engine makes it one of the fastest ways to query raw lakehouse data. Organizations frequently adopt a hybrid approach: massive, historical datasets are kept in Apache Iceberg on S3 and queried via ClickHouse’s external tables, while the most recent, heavily accessed “hot” data is ingested into native MergeTree tables for sub-millisecond dashboard performance.
Real-Time Observability and Telemetry
One of the most prominent use cases for ClickHouse is in the realm of observability, log analytics, and telemetry. Applications generate massive streams of log data, metrics, and tracing events. Storing and analyzing this data in real-time is challenging for traditional data warehouses.
ClickHouse excels at this workload. Its ability to ingest millions of events per second makes it an ideal target for streaming pipelines powered by Apache Kafka or vector agents. ClickHouse provides specialized materialized views and aggregation functions specifically designed for time-series data.
For example, ClickHouse can automatically compute downsampled metrics (e.g., rolling up minute-level data into hourly summaries) as the data is ingested, storing the results in an AggregatingMergeTree table. This means that dashboards displaying network traffic or application performance can load instantaneously, regardless of how much raw underlying data exists. This capability has led many modern observability platforms to replace legacy systems like Elasticsearch with ClickHouse.
Summary and Tradeoffs
ClickHouse is a marvel of database engineering. By ruthlessly optimizing every layer of the storage and execution engine to exploit modern hardware, it delivers query speeds that consistently beat industry benchmarks. Whether deployed as a dedicated real-time analytics backend or as an external query engine for an open data lakehouse, ClickHouse provides unmatched performance for analytical workloads.
The primary tradeoff with ClickHouse lies in its complexity and its departure from traditional relational database norms. ClickHouse is not a transactional database; it does not support full ACID transactions for granular UPDATE or DELETE operations. Modifying data in ClickHouse requires complex workarounds using specialized mutations or CollapsingMergeTree engines, making it completely unsuitable for OLTP workloads.
Furthermore, getting the absolute best performance out of ClickHouse requires a deep understanding of its inner workings. Engineers must carefully design the ORDER BY keys, understand index granularity, and properly configure the various MergeTree engines. However, for organizations willing to invest in this expertise, ClickHouse offers the scalability and sheer speed required to power the most demanding real-time analytics platforms in the world.
Visual Architecture