Columnar Formats
Columnar formats are data storage layouts where data is physically organized and stored by column, rather than by row. This structural paradigm shift—pioneered by academic systems like C-Store and popularized by formats like Apache Parquet and Apache ORC—is the fundamental enabling technology for modern high-performance analytical databases and the open data lakehouse. Columnar storage dramatically reduces disk I/O and maximizes compression, allowing engines to scan petabytes of data in seconds.
Row-Oriented vs. Column-Oriented Storage
To appreciate columnar formats, one must understand the legacy approach: row-oriented storage.
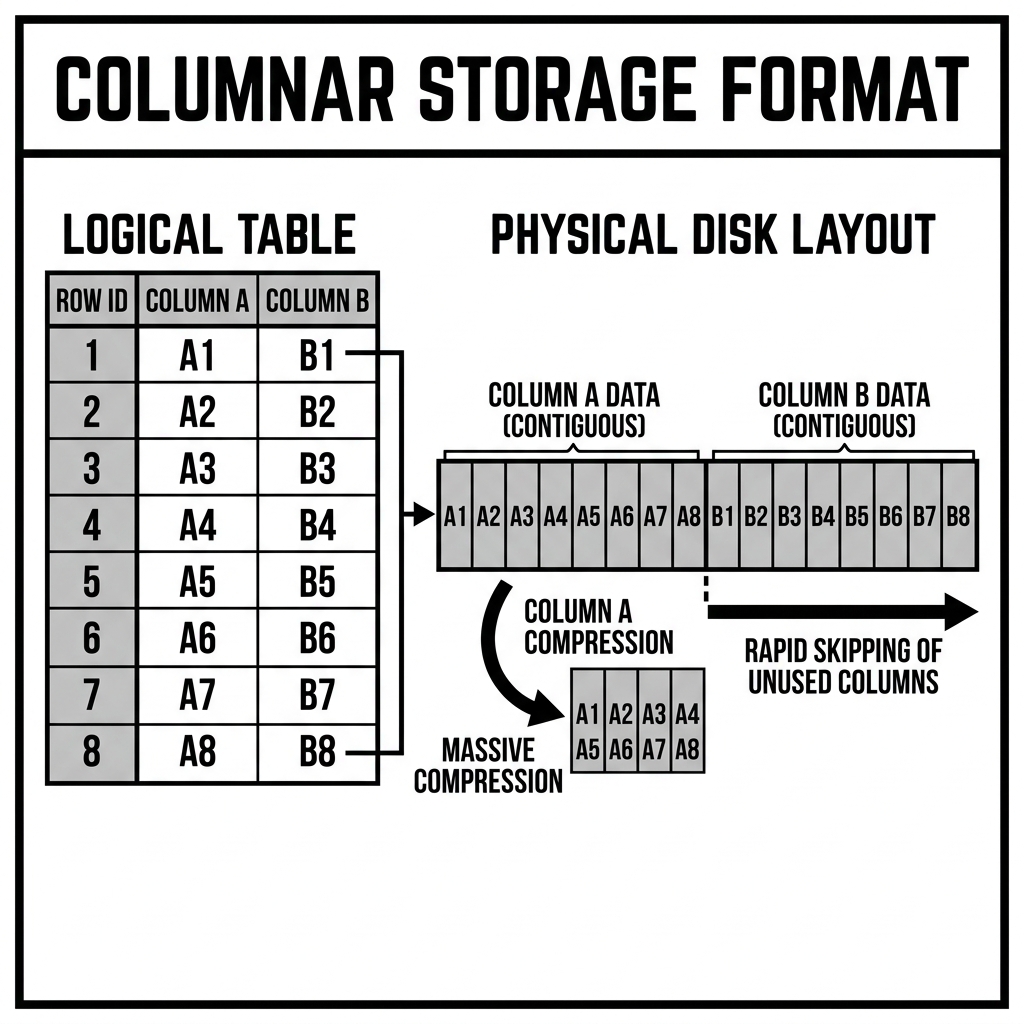
In a row-oriented format (like CSV, JSON, or traditional PostgreSQL tables), data is stored sequentially on the physical disk exactly as it appears in a spreadsheet. Row 1’s data (ID, Name, Age, Salary) is written to the disk, followed immediately by Row 2’s data.
This is highly efficient for Transactional (OLTP) workloads. If an application needs to retrieve or insert a single complete user record, the disk head only needs to go to one physical location to read or write the entire row.
However, row-oriented storage is catastrophic for Analytical (OLAP) workloads. If an analyst queries SELECT SUM(Salary) FROM Employees, a row-oriented database must read every single row from the disk, scanning through the ID, Name, and Age data just to extract the Salary value. This results in massive, wasted disk I/O (input/output).
Columnar formats invert this architecture. All values for the ID column are stored contiguously on the physical disk, followed by all values for the Name column, followed by all values for the Salary column.
The Advantages of Columnar Storage
Organizing data by column unlocks two massive performance benefits for analytical queries:
1. Projection Pushdown (Column Skipping):
When the analyst runs SELECT SUM(Salary) FROM Employees against a columnar file (like Parquet), the query engine only reads the physical block of disk containing the Salary column. It completely ignores the ID, Name, and Age data blocks on the disk. By physically skipping unneeded data, the engine drastically reduces disk I/O. For wide tables with hundreds of columns, column skipping can make queries 100x faster simply by preventing the engine from reading irrelevant data from the slow storage layer.
2. Extreme Data Compression: Data compression algorithms work by finding repetitive patterns. In a row-oriented format, a single block of disk contains an integer (ID), a string (Name), a date (DOB), and a float (Salary). Because the data types and values are heterogeneous, compression is highly inefficient.
In a columnar format, a single block of disk contains 10,000 Salaries (e.g., all floats) or 10,000 States (e.g., repeating strings like “CA”, “NY”, “CA”). Because the data is highly homogeneous, specialized compression algorithms (like Dictionary Encoding or Run-Length Encoding) can compress the data phenomenally well. Columnar files are often 70% to 90% smaller than their row-based equivalents (like raw CSVs). This smaller footprint reduces cloud storage costs and means less data must be transferred over the network during query execution.
The Role in the Lakehouse
In the open data lakehouse architecture, data is stored in cheap, remote object storage (like Amazon S3). Because network bandwidth to S3 is relatively slow compared to local SSDs, minimizing the amount of data transferred over the network is paramount.
Columnar formats like Apache Parquet are the de facto standard for the lakehouse. When an engine like Trino queries the lakehouse, it relies entirely on the columnar layout of the Parquet files to execute Projection Pushdown, pulling only the required bytes over the network.
Furthermore, modern columnar formats contain rich internal metadata. A Parquet file stores the Minimum and Maximum values for every column chunk within its footer. The query engine reads this tiny footer first; if the query says WHERE age > 50, and the footer indicates the maximum age in this file block is 45, the engine skips reading the block entirely (Predicate Pushdown).
Summary and Tradeoffs
Columnar formats are the engine that makes big data analytics possible, sacrificing write speed for unparalleled read performance and compression.
The primary tradeoff with columnar storage is the immense penalty for single-row inserts or updates. If you need to insert a single new row into a columnar file, you cannot just append it to the end of the file. You must physically break the row apart, find the end of the ID column, write the ID, find the end of the Name column, write the name, and so on. This random I/O is incredibly slow.
This is why columnar formats are used exclusively for bulk, analytical workloads. Data is typically ingested in massive batches, converted to columnar format in memory, and then written to disk as large, immutable files. When updates are required in a lakehouse, open table formats like Apache Iceberg manage the complexity of logically updating records while physically managing large, immutable columnar files behind the scenes.
Visual Architecture