Compaction
A modern data lakehouse is often fed by continuous, real-time data streams (like Apache Kafka or Flink). To ensure low latency, these streaming engines commit data to the lakehouse frequently, often every minute or even every few seconds.
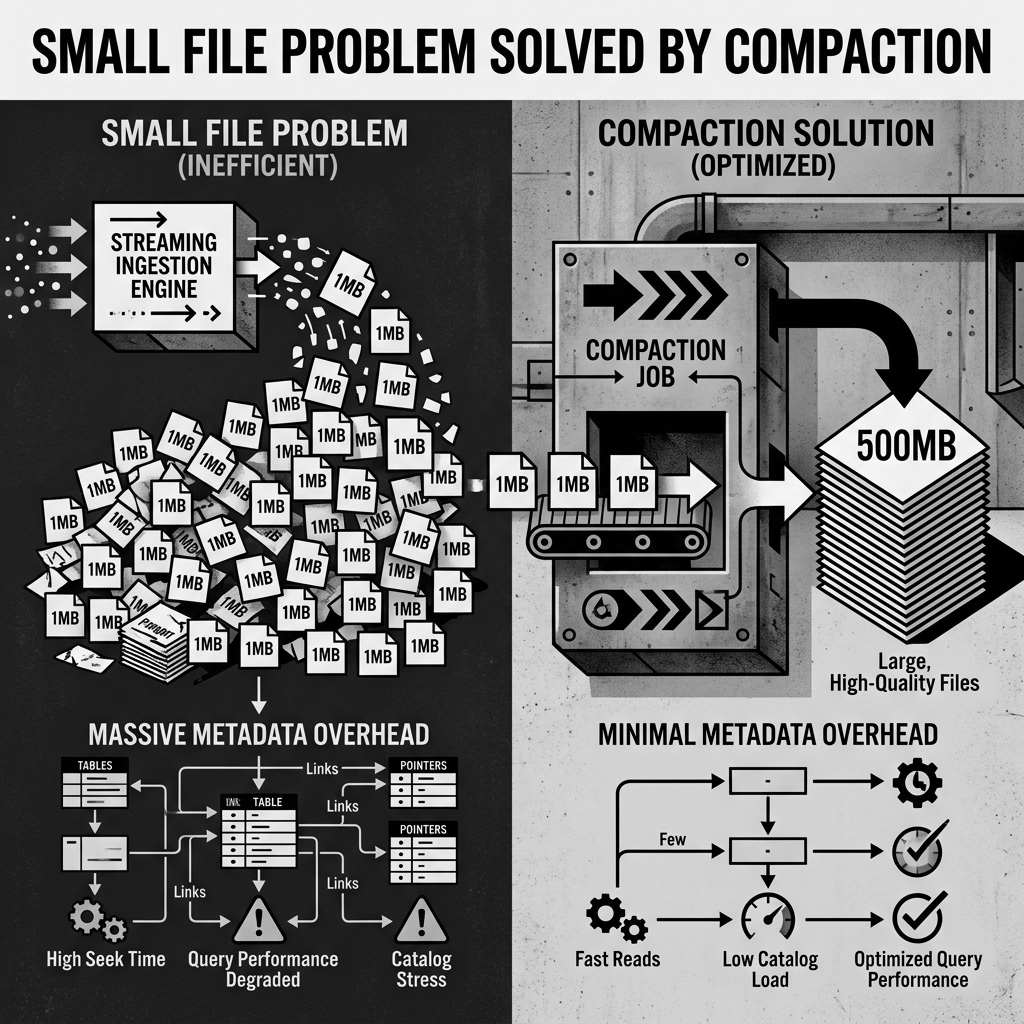
This architecture creates a severe operational challenge known as the Small File Problem. Over the course of a day, a single table might accumulate hundreds of thousands of tiny 1-megabyte Parquet files.
When an analyst queries this table, the query engine spends 90% of its time simply opening and closing network connections to read file headers, and only 10% of its time actually processing data. Furthermore, tracking the metadata for millions of tiny files places an enormous burden on the Iceberg Manifests, slowing down query planning.
The solution to the Small File Problem is Compaction.
Merging Files for Performance
Compaction is an asynchronous maintenance job (often run via Spark or a managed service like Dremio Arctic) that cleans up the physical storage layer without interrupting downstream queries.
The compaction job reads the thousands of tiny Parquet files created by the streaming engine, merges them together in memory, and rewrites them back to object storage as a few perfectly sized, large Parquet files (typically targeting 256MB or 512MB).
Once the large files are written, Iceberg performs an atomic catalog commit. It swaps the metadata pointers so that future queries read the new large files instead of the old tiny ones. Because Iceberg provides Snapshot Isolation, this entire process is completely invisible to users currently querying the table.
Diagram 1: Solving the Small File Problem
The Bin Packing Strategy
Rewriting data is computationally expensive. If a compaction job blindly rewrote every single file in a partition every night, the compute costs would be astronomical.
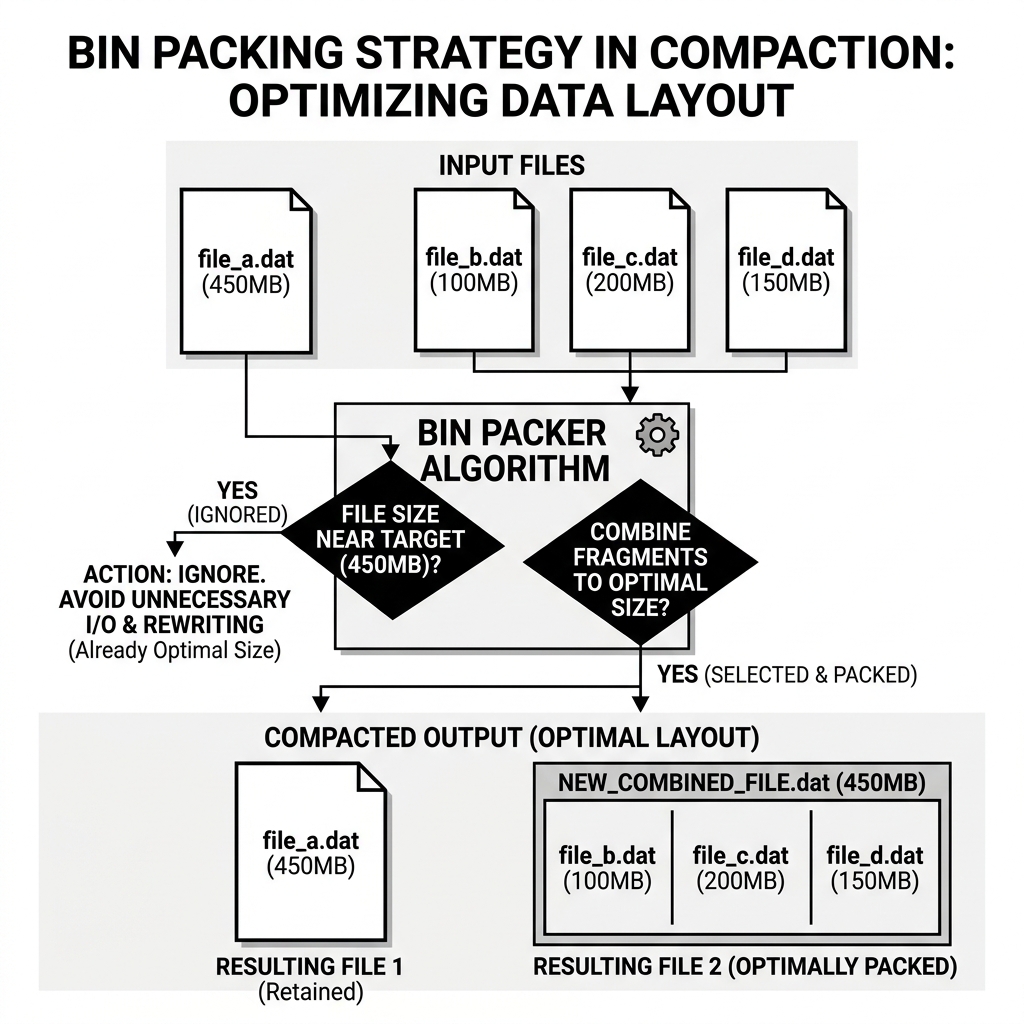
Iceberg solves this using a Bin Packing algorithm during the Rewrite Data Files procedure.
When the compaction job evaluates a partition, it looks at the size of every file. If it sees a file that is 450MB, and the target size is 500MB, the algorithm ignores it. It knows that rewriting a 450MB file to gain 50MB of efficiency is a waste of compute resources.
Instead, the Bin Packer specifically hunts for the tiny files. It gathers files that are 10MB, 50MB, and 100MB, and “packs” them together into a new file until it reaches the optimal 500MB target. This surgical approach ensures that engineering teams only pay compute costs to fix the data that is actively hurting performance.
Diagram 2: Bin Packing Algorithm