Copy-on-Write (CoW)
In a traditional relational database, if you execute an UPDATE statement to change a user’s address, the database engine physically overwrites the specific bytes on the hard drive where that old address lived. This is called in-place mutation.
Data lakehouses do not use in-place mutation. They store data in columnar formats like Parquet, which are highly compressed and completely immutable. Once a Parquet file is written, it can never be altered.
To support UPDATE, DELETE, and MERGE operations on immutable files, Apache Iceberg must employ specialized file management strategies. The default, and historically most common strategy, is Copy-on-Write (CoW).
The CoW Mechanism
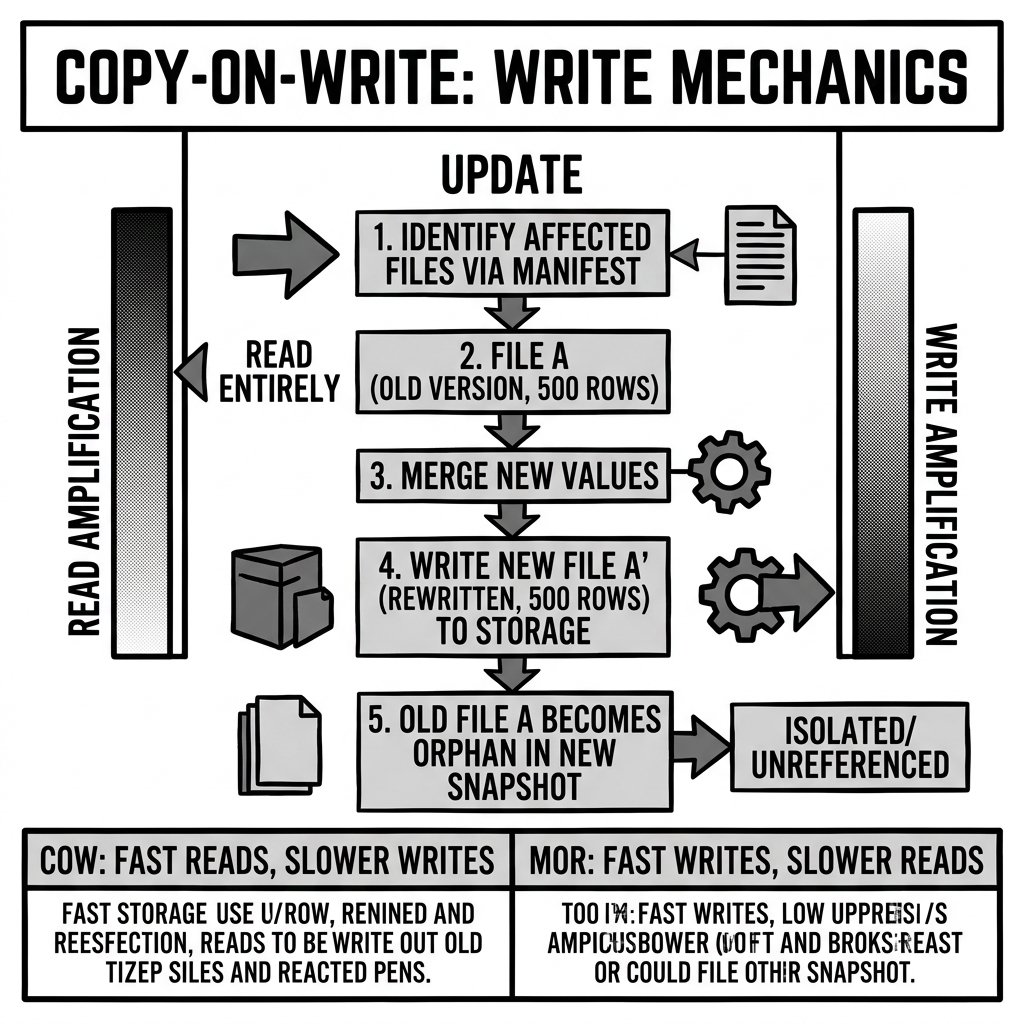
Imagine a 500MB Parquet file containing 1 million rows of customer data. A data engineer executes a DELETE statement targeting a single customer (1 row).
Under the Copy-on-Write strategy, the query engine (e.g., Apache Spark) must do the following:
- Read: It reads the entire 500MB Parquet file into memory.
- Filter: It filters out the 1 single row that was targeted for deletion, keeping the other 999,999 rows.
- Write: It writes a completely brand-new 500MB Parquet file containing only those 999,999 rows.
- Commit: Iceberg performs an atomic catalog commit. The metadata now points to the new file, and the old file is logically deleted (unreferenced).
The Trade-off: Read vs. Write Performance
Copy-on-Write makes a very specific architectural trade-off: It sacrifices write performance to guarantee absolute maximum read performance.
Because the query engine is doing all the heavy lifting during the UPDATE or DELETE operation, the resulting Parquet files are perfectly clean. When an analyst subsequently queries the data, the query engine can simply stream the bytes off the disk as fast as possible. There is no runtime overhead, no fragmented files, and no complex logic to resolve.
However, this comes at the severe cost of Write Amplification. Modifying a single 1-kilobyte row required the system to perform 500MB of I/O operations. In environments with continuous, high-frequency updates or deletes (like streaming CDC pipelines), Copy-on-Write can cause pipelines to grind to a halt due to massive compute and storage overhead.
For tables that are written once a day (batch) and read thousands of times a day, Copy-on-Write remains the optimal, highly performant strategy.
(Diagram 1: The Copy-on-Write execution flow - Pending Generation) (Diagram 2: Trade-offs of Write Amplification vs Read Performance - Pending Generation)
Visual Architecture