Cost-Based Optimizer (CBO)
A Cost-Based Optimizer (CBO) is the intelligent “brain” within a modern relational database or distributed compute engine. Its sole responsibility is to evaluate a user’s SQL query, consider numerous different ways that query could physically be executed, and select the single execution plan that will be the fastest and least resource-intensive. In the era of the open data lakehouse, where queries often span multiple petabyte-scale tables across distributed storage, a highly advanced CBO is the difference between a query completing in three seconds or crashing after three hours.
Core Definition
SQL is a declarative language. When a data analyst writes a query, they are telling the database what data they want to retrieve, not how to retrieve it.
Consider a query joining three tables: Customers, Orders, and Products. There are dozens of ways to execute this mathematically. Should the engine join Customers to Orders first, and then join the result to Products? Or should it join Orders to Products first? Should it use a Hash Join or a Sort-Merge Join?
Early databases used a Rule-Based Optimizer (RBO), which applied static, hardcoded heuristics (e.g., “always join the smaller table first based on the syntax order”). However, these rigid rules failed spectacularly as data sizes grew and schemas became complex.
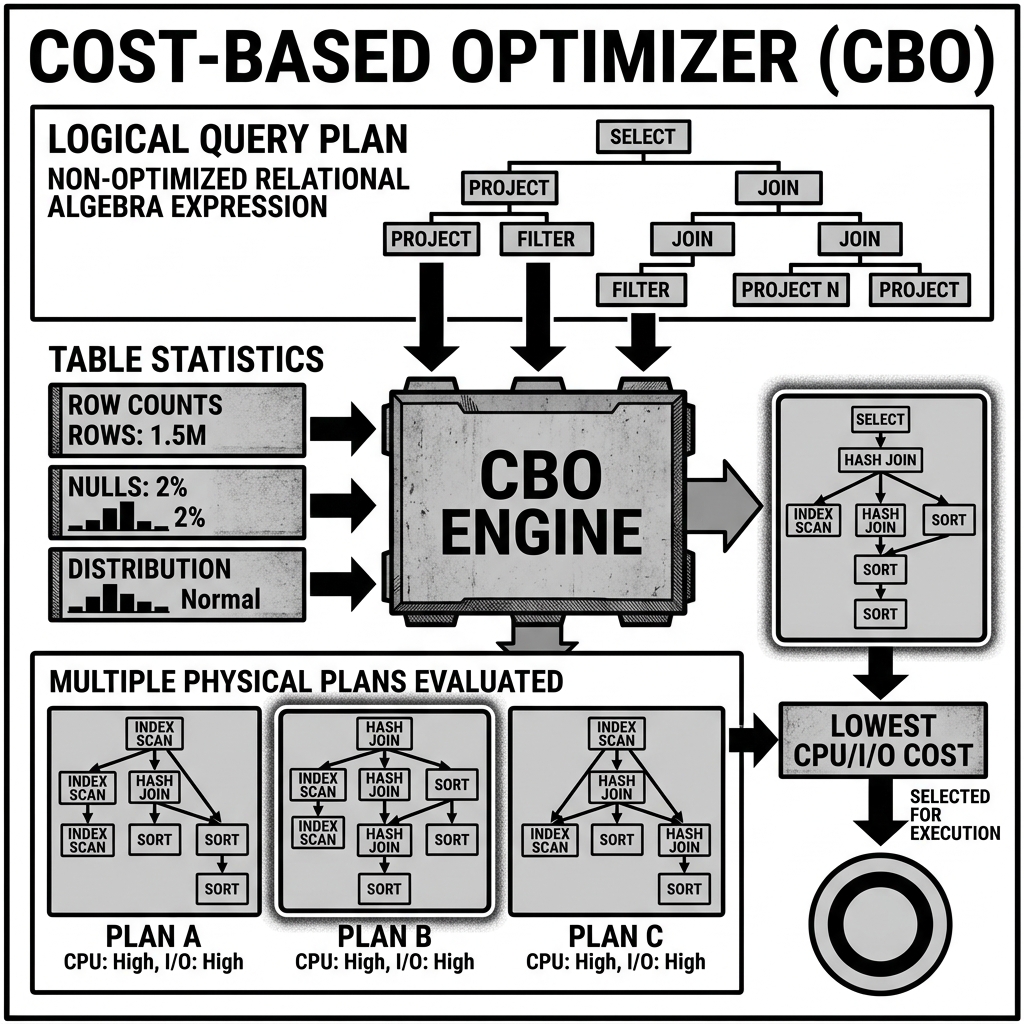
A Cost-Based Optimizer takes a dynamic, mathematical approach. It generates multiple possible physical execution plans for a given query. For each plan, the CBO calculates an estimated “cost.” This cost is an abstract mathematical score that represents the expected CPU cycles, memory usage, disk I/O, and network bandwidth required to execute that specific plan. The CBO then selects the plan with the lowest overall cost and hands it off to the execution engine.
The Importance of Statistics
A CBO is utterly dependent on accurate metadata statistics. To calculate the cost of a plan, the optimizer must know the shape and distribution of the underlying data. Without statistics, the CBO is flying blind.
Modern compute engines maintain statistics on several levels:
- Table-Level: Total number of rows in the table, total file size.
- Column-Level: Number of distinct values (cardinality), number of NULL values, minimum and maximum values, and average data length.
- Histograms: Detailed data distributions showing data skew (e.g., determining that 90% of the orders in the table originate from only two specific states).
Using these statistics, the CBO performs cardinality estimation. If the query includes WHERE state = 'CA', the CBO looks at the histogram to estimate exactly how many rows will survive this filter.
If the CBO accurately estimates that only 10,000 rows will survive the filter on a billion-row table, it might decide that a broadcast join (where the small resulting 10,000-row table is copied to all worker nodes) is the cheapest plan. If the statistics are missing or stale, the CBO might assume a billion rows will survive, and instead choose an expensive, cluster-wide shuffle join. The accuracy of the statistics directly dictates the quality of the execution plan.
CBO in the Data Lakehouse
In traditional, closed data warehouses (like Oracle or Teradata), the database managed both the compute and the storage. It had complete control over the ingestion process and could seamlessly update statistics in the background every time data was inserted.
In the open data lakehouse, compute and storage are decoupled. Data is written to object storage (like Amazon S3) by one tool (e.g., Apache Flink) and read by a completely different tool (e.g., Trino). How does the Trino CBO get the statistics it needs?
This is where open table formats like Apache Iceberg, Delta Lake, and Apache Hudi become critical. These formats explicitly store detailed column-level metrics (min/max values, null counts) within their metadata files (like Iceberg manifests).
Furthermore, modern formats have introduced advanced statistical structures like Apache DataSketches to calculate and store Approximate Count Distinct (NDV) metrics and column distributions (Puffin files in Iceberg). When a compute engine queries the lakehouse, its CBO reads these standardized metadata files to gather the statistics required to perform join reordering and cost estimation, enabling enterprise-grade query optimization over decoupled open storage.
Advanced Optimization Techniques
Modern CBOs employ highly sophisticated techniques to reduce query costs:
Join Reordering: The order in which tables are joined has the most massive impact on performance. A CBO uses dynamic programming algorithms to evaluate different join permutations, aiming to perform joins that dramatically reduce the dataset size as early in the execution plan as possible.
Adaptive Query Execution (AQE): A limitation of traditional CBOs is that they must finalize the execution plan before the query begins, based on estimates. If the estimates are wrong, the plan is terrible. Engines like Apache Spark have introduced AQE. During execution, if Spark realizes the actual data size of a completed stage is vastly different from the CBO’s initial estimate, it will pause, recalculate the statistics based on the real intermediate data, and dynamically change the physical execution plan for the remainder of the query (e.g., switching a Sort-Merge join to a Broadcast join mid-flight).
Summary and Tradeoffs
The Cost-Based Optimizer is the most complex software component in a modern data platform, often requiring decades of engineering effort to mature. It is the magic layer that allows analysts to write complex, nested SQL without needing to understand the physical distribution of the underlying data.
The primary tradeoff with a CBO is the overhead of plan generation. For a query joining a dozen tables, there are millions of possible execution plans. Evaluating all of them would take longer than actually running the query. Therefore, CBOs employ heuristics and timeout limits to stop searching and pick a “good enough” plan if the search space is too large.
Additionally, a CBO is entirely reliant on the health of its statistics. If data engineering pipelines fail to run the ANALYZE commands to update table statistics, the CBO will generate catastrophic execution plans, leading to out-of-memory errors and sluggish performance. In the modern data lakehouse, maintaining rigorous metadata hygiene is paramount to ensuring the CBO can do its job effectively.
Visual Architecture