Data Fabric
Modern enterprises rarely store their data in a single place. A typical large company manages data across dozens of environments simultaneously: legacy on-premises Oracle databases, cloud data warehouses like Snowflake, data lakes in Amazon S3, SaaS applications like Salesforce, streaming platforms like Apache Kafka, and a growing collection of departmental databases that accumulated over years of mergers and acquisitions. Getting a unified view of a customer, a product, or a business process across all of these disconnected environments is extraordinarily difficult.
Data Fabric is an architectural approach designed to address this specific challenge. Where Data Mesh focuses on organizational decentralization, and the Data Lakehouse focuses on unifying compute and storage through open formats, Data Fabric focuses on creating an integrated, intelligent, and unified layer across all data environments, regardless of where the data physically lives. It does not require moving data to a single location. Instead, it connects data in place via a combination of metadata management, data virtualization, and active metadata intelligence.
Gartner, which has been one of the primary advocates of the Data Fabric concept, defines it as a design concept that uses continuous analytics over existing, discoverable, and inferring metadata assets to support the design, deployment, and utilization of integrated and reusable data across all environments.
The Role of Active Metadata
The defining characteristic that separates a Data Fabric from a simple data integration tool is its reliance on Active Metadata.
Traditional metadata is passive. A data catalog records what data exists, where it is, what its schema looks like, and who owns it. This is genuinely useful, but it is static. A traditional catalog must be manually updated as the data landscape changes.
Active metadata goes further. A Data Fabric continuously collects metadata from all connected data sources, processing not just technical metadata (schemas, data types) but also operational metadata (query patterns, access logs, pipeline execution statistics) and business metadata (data domains, ownership, quality scores). This rich metadata is then processed by machine learning models to generate recommendations and trigger automated actions.
For example, an active metadata engine might observe that a specific table in the data warehouse is frequently joined with a specific table in the data lake by multiple different teams. Based on this usage pattern, the fabric can automatically recommend that these two sources be virtualized into a unified logical view, saving every team the effort of writing the same join. It can also automatically detect when a data asset that is heavily used by downstream consumers has not been refreshed in longer than its expected schedule, and alert the owning team before consumers are impacted.
Diagram 1: Conceptual Architecture
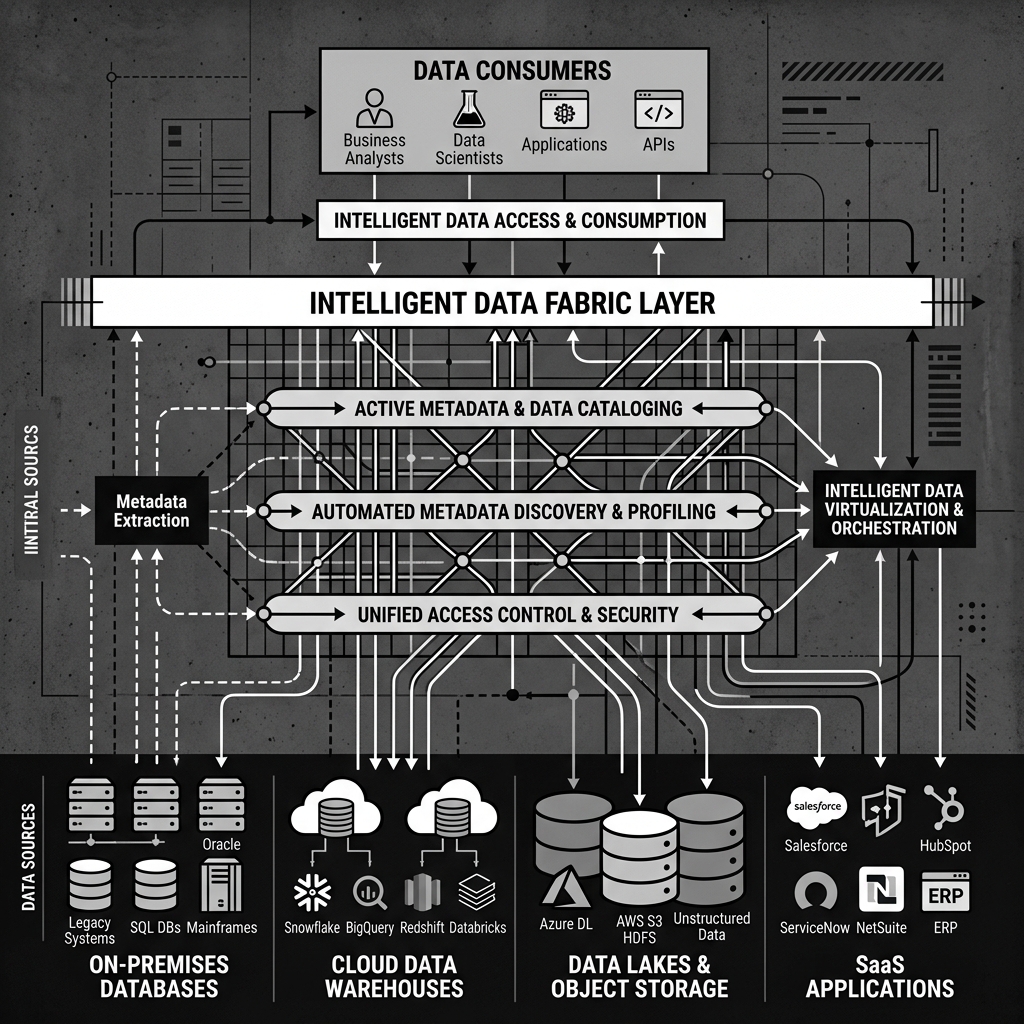
Data Virtualization as the Access Layer
A central technical component of most Data Fabric implementations is data virtualization. Rather than physically copying and moving data between systems, data virtualization creates a logical abstraction layer that makes distributed data appear as if it exists in a single unified database.
When a business analyst submits a SQL query against the virtual layer, the data fabric’s query engine breaks that query apart, pushes relevant portions of the query down to each native data source (a process called query pushdown), retrieves the results, and assembles them into a unified response. The analyst never needs to know that the data they are querying came from five different systems across three different clouds.
The performance of this approach depends heavily on the sophistication of the query optimizer and the availability of rich metadata. If the fabric knows the cardinality, partition structure, and index characteristics of each source system, it can generate highly optimized query plans that minimize data movement. Platforms like Dremio have built their entire product around this concept, using Apache Arrow as an in-memory columnar format to efficiently transfer data between distributed query nodes without serialization overhead.
Diagram 2: Active Metadata Engine
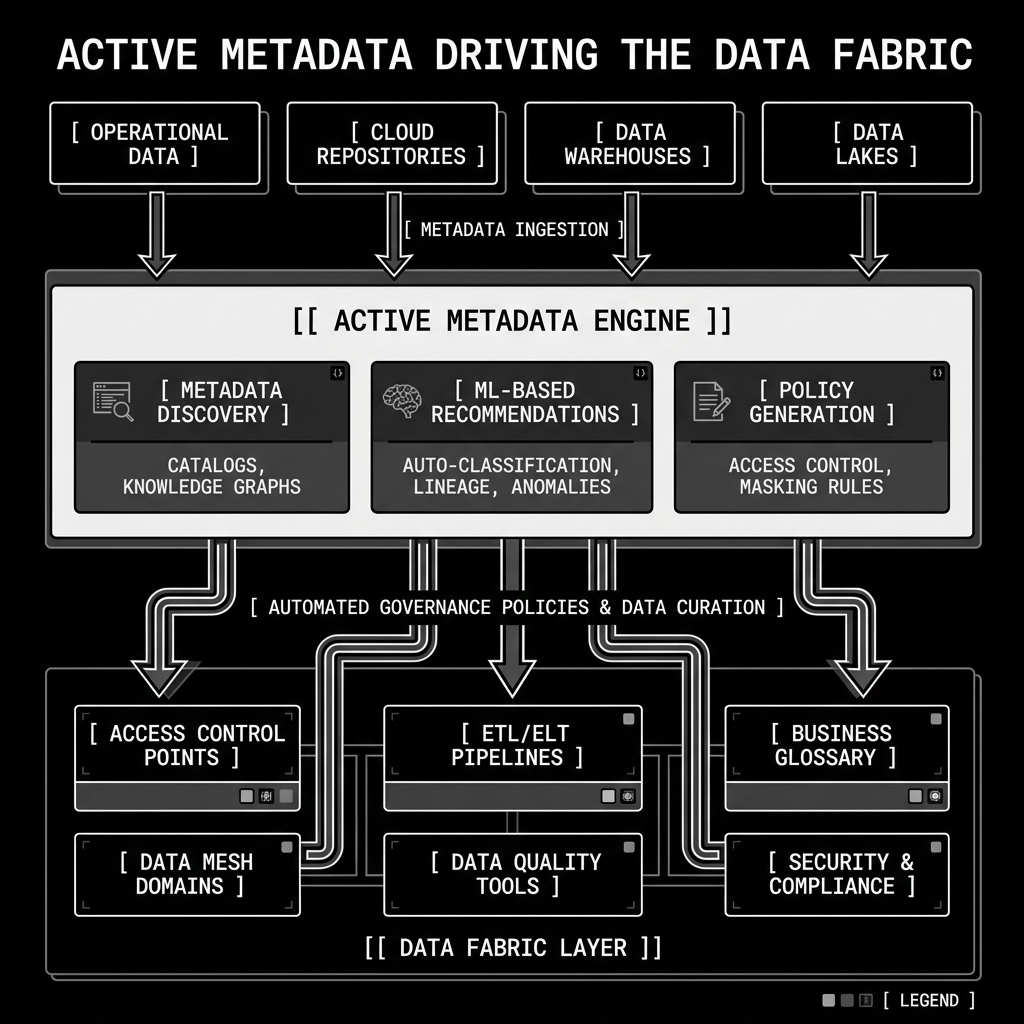
Data Fabric vs. Data Mesh
Data Fabric and Data Mesh are frequently compared, and they are often confused. They address related problems but from fundamentally different angles.
Data Mesh is an organizational model. It answers the question of who should own and manage data by distributing that responsibility to domain teams. It requires cultural change, product thinking, and organizational restructuring.
Data Fabric is a technical model. It answers the question of how data from many different environments can be unified for discovery and access without requiring it to be physically centralized. It is implemented through technology: metadata engines, virtualization layers, and automated governance tools.
The two approaches are not mutually exclusive. An organization can implement both simultaneously. A Data Mesh provides the governance structure and domain ownership model, while a Data Fabric provides the technical layer that connects all of the domain-owned data products into a single discoverable, accessible ecosystem. In this combined model, each domain team owns and manages its data products according to Data Mesh principles, and the Data Fabric provides the active metadata intelligence and virtualization layer that makes those products discoverable and queryable by any other team across the organization without data movement.
Implementation Challenges
Building a true Data Fabric is an ambitious undertaking. The most immediate challenge is metadata completeness. The fabric’s intelligence is only as good as the metadata it can collect. Legacy systems often have poor or nonexistent metadata APIs, making automated discovery difficult. Manual metadata curation at scale is expensive and error-prone.
The second challenge is query performance. Federated queries that span multiple remote systems can be slow, particularly when the source systems are on different clouds with high network latency between them. Sophisticated caching strategies and aggressive query pushdown optimization are essential to making the virtualization layer perform acceptably for interactive analytics.
Despite these challenges, the Data Fabric approach is gaining significant adoption as enterprises recognize that the alternative, which is trying to physically consolidate all data into a single platform, is neither technically feasible nor economically rational at modern data volumes.