Data File
If you peel back the complex layers of an open data lakehouse—past the query engines, past the Catalog, past the metadata tree of Manifest Lists and Manifest Files—you finally arrive at the absolute bottom of the stack: the Data File.
The Data File is where the actual bytes of information live. It is the physical manifestation of the raw data resting in cloud object storage (like Amazon S3, Azure Blob, or Google Cloud Storage). While the metadata layer tells the query engine where to look, the Data File is what the engine is actually looking for.
In a modern data lakehouse, Data Files are almost exclusively stored in open, columnar formats. Apache Parquet is the overwhelming industry standard, though ORC (Optimized Row Columnar) is also widely supported, particularly in legacy Hadoop environments. The choice of file format at this physical layer dictates the absolute limits of query performance.
The Columnar Advantage
If you open a CSV file in a text editor, you see data stored row by row. This is intuitive for humans and fine for transactional (OLTP) systems that frequently insert or retrieve single, complete records (like a user profile).
However, analytical (OLAP) queries rarely need entire rows. An analyst might run a query to find the average age of all users. In a row-based format, the engine must read every single byte of the file, scanning past names, addresses, and phone numbers, just to extract the age values.
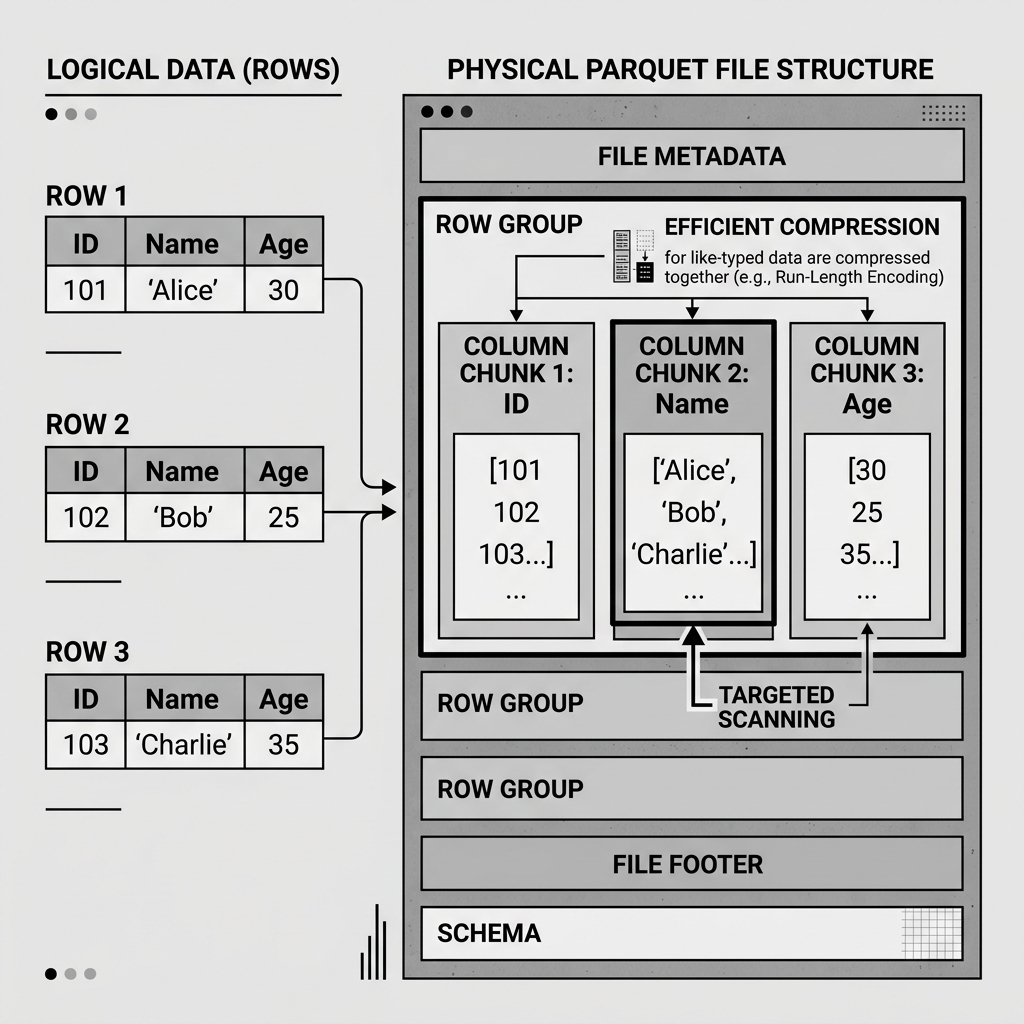
Columnar data files, like Parquet, solve this by storing data column by column. The file is divided into logical “Row Groups.” Inside each Row Group, all the values for Column A are stored contiguously, followed by all the values for Column B.
When the query engine needs to calculate the average age, it simply seeks to the specific byte offset in the file where the “Age” column chunk begins and reads only those bytes, completely ignoring the names and addresses. This targeted scanning drastically reduces disk I/O, which is typically the slowest part of any data operation.
Diagram 1: Columnar Data File Structure
Compression and Encoding
Because columnar files store identical data types next to each other (e.g., a million integers in a row), they achieve extraordinary compression ratios.
Data Files utilize advanced encoding techniques before applying standard compression (like Snappy or Zstandard). For example, if a column tracks a boolean is_active flag, the file doesn’t need to write the string “true” or “false” a million times. It uses Run-Length Encoding (RLE) to simply say “The next 50,000 values are True, followed by 10,000 Falses.”
Dictionary encoding is another powerful technique. If a “State” column only contains 50 unique values (NY, CA, TX, etc.) spread across a billion rows, the Data File creates a small dictionary mapping those strings to integers (NY=1, CA=2). The massive column of data is then stored as a highly compressible list of tiny integers. These techniques allow a 100 GB CSV file to often be compressed down to a 10 GB Parquet Data File.
Diagram 2: Data Files in the Lakehouse
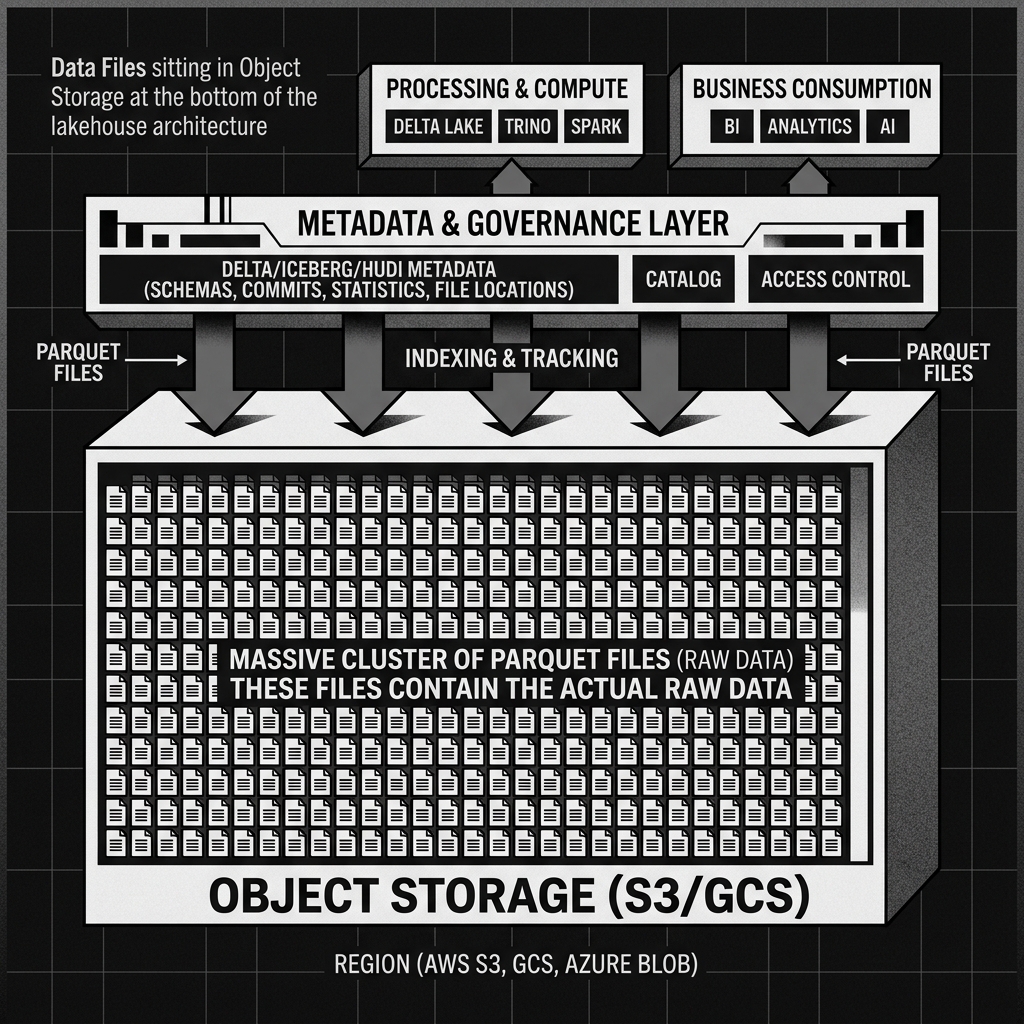
The Relationship to the Metadata Layer
In an Apache Iceberg table, Data Files are completely dumb. They know nothing about the table they belong to, the schema changes that have occurred, or whether they have been logically “deleted” by a recent transaction. They are just raw, immutable blobs of bytes in S3.
The intelligence lives entirely in the metadata layer. When a row is deleted from an Iceberg table, the underlying Data File containing that row is usually not modified. Instead, the metadata layer (specifically the Manifest File) is updated to point to a newly rewritten Data File that excludes the deleted row, or it creates a separate “Delete File” that tells the engine to ignore that specific row during read time.
This strict separation—where Data Files handle the physical storage of bytes and the Metadata Layer handles the logical state of the table—is the fundamental architectural principle that allows the open data lakehouse to scale infinitely while maintaining transactional integrity.