Data Lake
Data Lake
The explosion of digital information over the last decade created a massive storage problem. Organizations were suddenly flooded with data generated from mobile applications, connected devices, server logs, and social media interactions. Traditional data warehouses were ill-equipped to handle this volume and variety. They required data to be meticulously cleaned, structured, and transformed before it could even be saved. This process, known as Schema-on-Write, was too slow and expensive to scale. The solution to this bottleneck was the Data Lake.
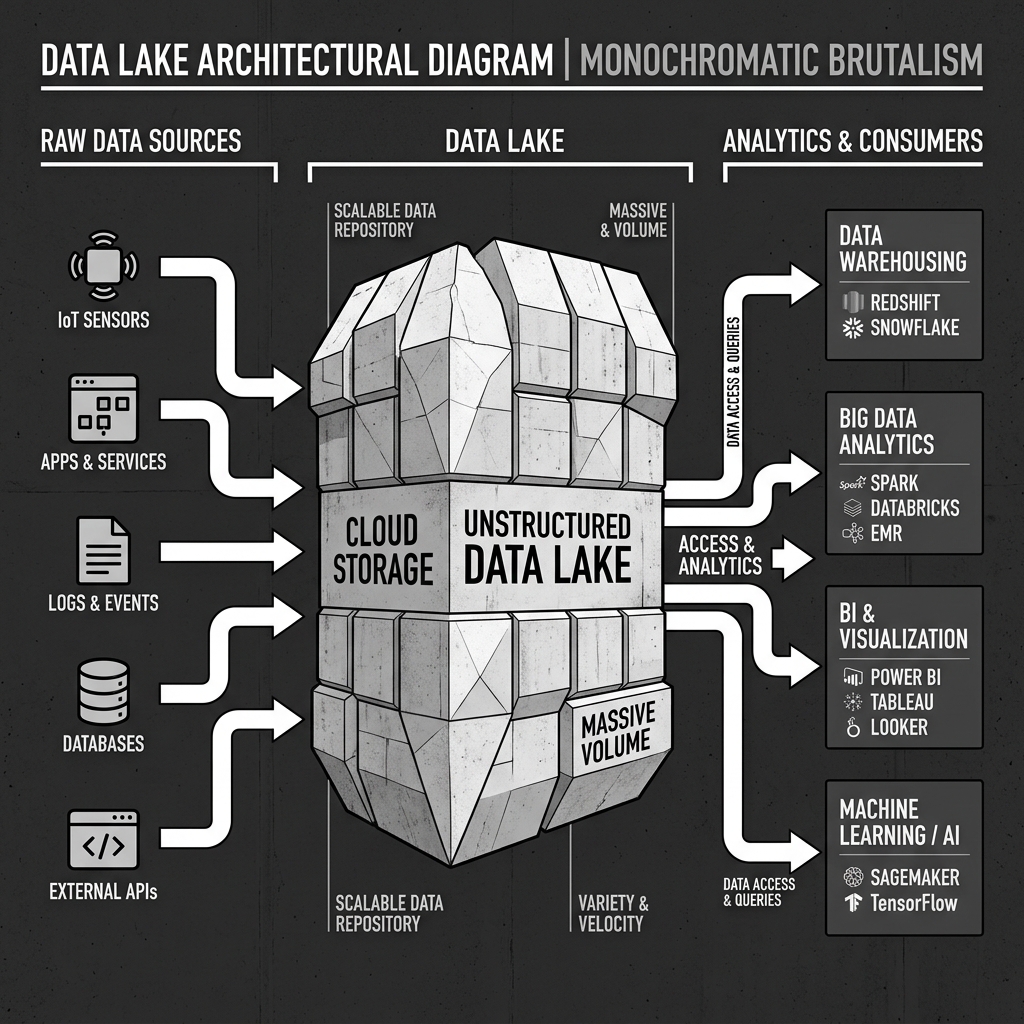
A data lake is a centralized repository designed to store, process, and secure large amounts of structured, semistructured, and unstructured data. It can store data in its native format and process any variety of it, ignoring size limits. This paradigm relies on Schema-on-Read, meaning the data is stored raw, and structure is only applied when the data is queried or read by an analytical tool.
The Evolution of Raw Storage
Data lakes originally gained prominence during the era of on-premises Hadoop clusters. Hadoop Distributed File System (HDFS) allowed organizations to stitch together arrays of commodity hardware to create massive, scalable storage pools. However, maintaining on-premises Hadoop clusters required specialized teams and significant capital expenditure.
The modern iteration of the data lake shifted to cloud object storage. Services like Amazon S3, Google Cloud Storage, and Azure Data Lake Storage provide virtually infinite scalability, high durability, and lower costs compared to on-premises solutions. Object storage decouples storage from compute entirely. This separation means you only pay for the storage you use, and you can spin up entirely separate compute clusters to analyze the data without impacting the storage layer itself.
The primary advantage of a data lake is its flexibility. You can store relational data from line-of-business applications, JSON documents from NoSQL databases, raw text logs from web servers, and even binary files like images and audio. Data scientists and data engineers can then access this raw, unadulterated data to train machine learning models, run ad-hoc analytics, or build complex data pipelines.
Diagram 1: Conceptual Architecture
Data Lake Challenges
While data lakes solved the immediate problem of scalable storage, they introduced new architectural challenges. Because a data lake accepts data without enforcing a schema or quality checks, it can easily degenerate into a “Data Swamp.” A data swamp is a disorganized, undocumented mess of files where data becomes undiscoverable and unusable.
Without strict governance and metadata management, data consumers cannot trust the data they pull from the lake. Furthermore, traditional data lakes lack ACID transaction support. If an ingestion job fails halfway through writing a massive dataset, the lake is left with partial, corrupted data. Readers querying the lake at the same time might read incomplete data, leading to inaccurate analytical results. Updating or deleting individual records in a data lake, such as for GDPR compliance, requires extremely costly operations that involve rewriting entire files or partitions.
These challenges eventually led to the development of the Data Lakehouse architecture, which overlays data warehouse-like governance and transactional guarantees on top of the data lake. However, the foundational storage layer of a lakehouse remains the data lake itself.
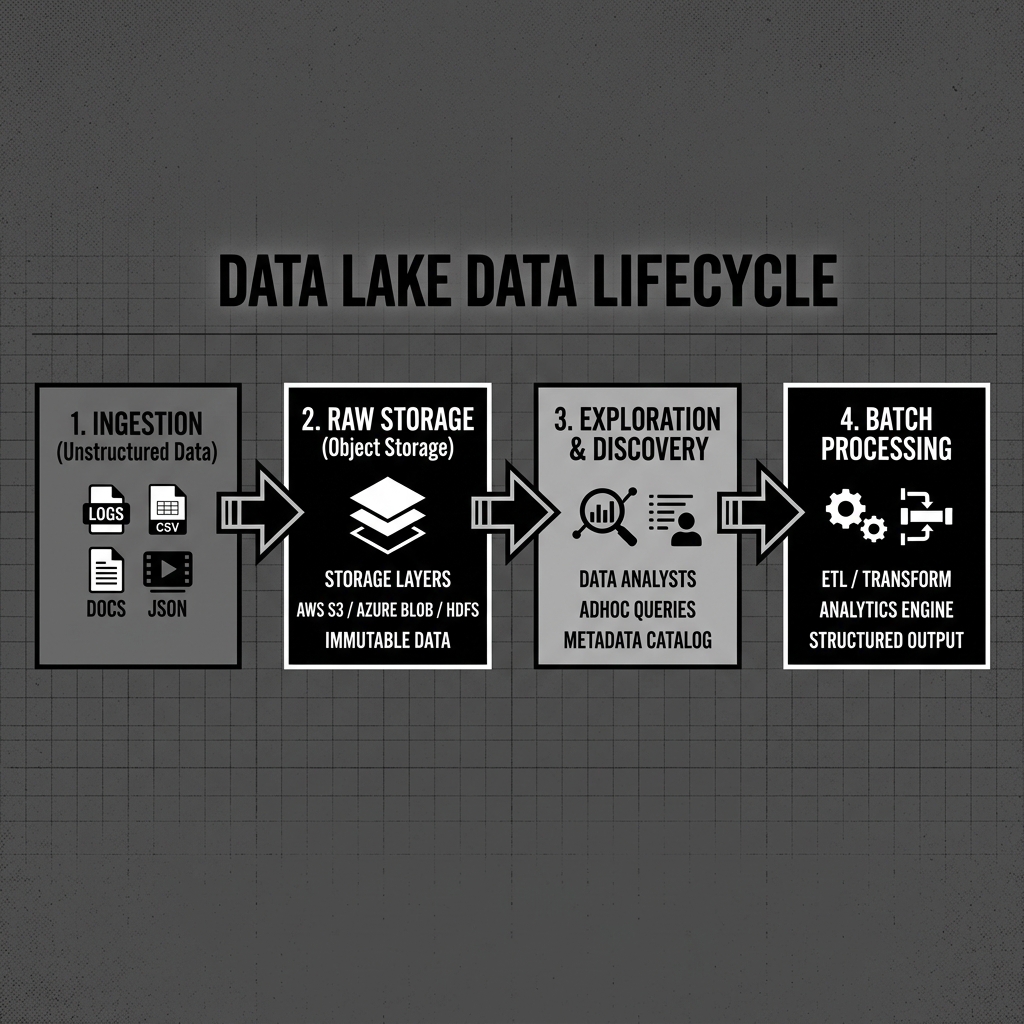
Diagram 2: Operational Flow
Managing the Data Lifecycle
To prevent a data lake from becoming a data swamp, organizations must implement a rigorous data lifecycle management strategy. This involves establishing zones or layers within the lake.
The Raw Zone is the landing area where data is ingested directly from source systems in its original format. This zone acts as an immutable historical record. Access to the Raw Zone is heavily restricted to data engineers and automated ingestion pipelines.
The Cleansed Zone contains data that has been validated, standardized, and converted into optimized columnar formats like Apache Parquet or ORC. Personally identifiable information (PII) is often masked or encrypted at this stage. Data scientists and analysts typically use this zone for exploratory analysis and model training.
The Curated Zone houses data that has been fully transformed and aggregated into business-ready data products. This data is modeled according to specific business logic and is ready for consumption by BI dashboards and reporting tools.
Implementing a metadata catalog is equally critical. Tools like AWS Glue or Apache Atlas automatically crawl the data lake, infer schemas, and catalog the available datasets. This allows data citizens to search for and discover the data they need, understanding its lineage and quality before relying on it for critical business decisions.
Ultimately, the data lake remains the bedrock of the modern data stack. By providing cheap, infinitely scalable storage for all data types, it enables organizations to retain massive historical datasets and unlock insights that would be economically impossible in a traditional data warehouse.