Data Lakehouse
Data Lakehouse
The modern data platform has evolved significantly over the last two decades. Early systems relied heavily on traditional data warehouses, which provided rigid structure, ACID transactions, and fast query performance for business intelligence workloads. As data volumes exploded and unstructured data became more prominent, organizations shifted toward data lakes. Data lakes offered cheap, scalable storage in environments like Amazon S3 or Hadoop Distributed File System (HDFS). However, data lakes suffered from a lack of reliability, poor query performance, and the inability to handle concurrent writes effectively. The concept of the data lakehouse emerged to solve this exact dichotomy.
A data lakehouse is a modern data management architecture that combines the best features of data warehouses and data lakes. It implements the data management features and structures found in data warehouses directly onto the low-cost, scalable storage used for data lakes. This unification eliminates the need for maintaining separate systems, reducing data movement, and simplifying the overall data engineering lifecycle.
Core Definition and Architecture
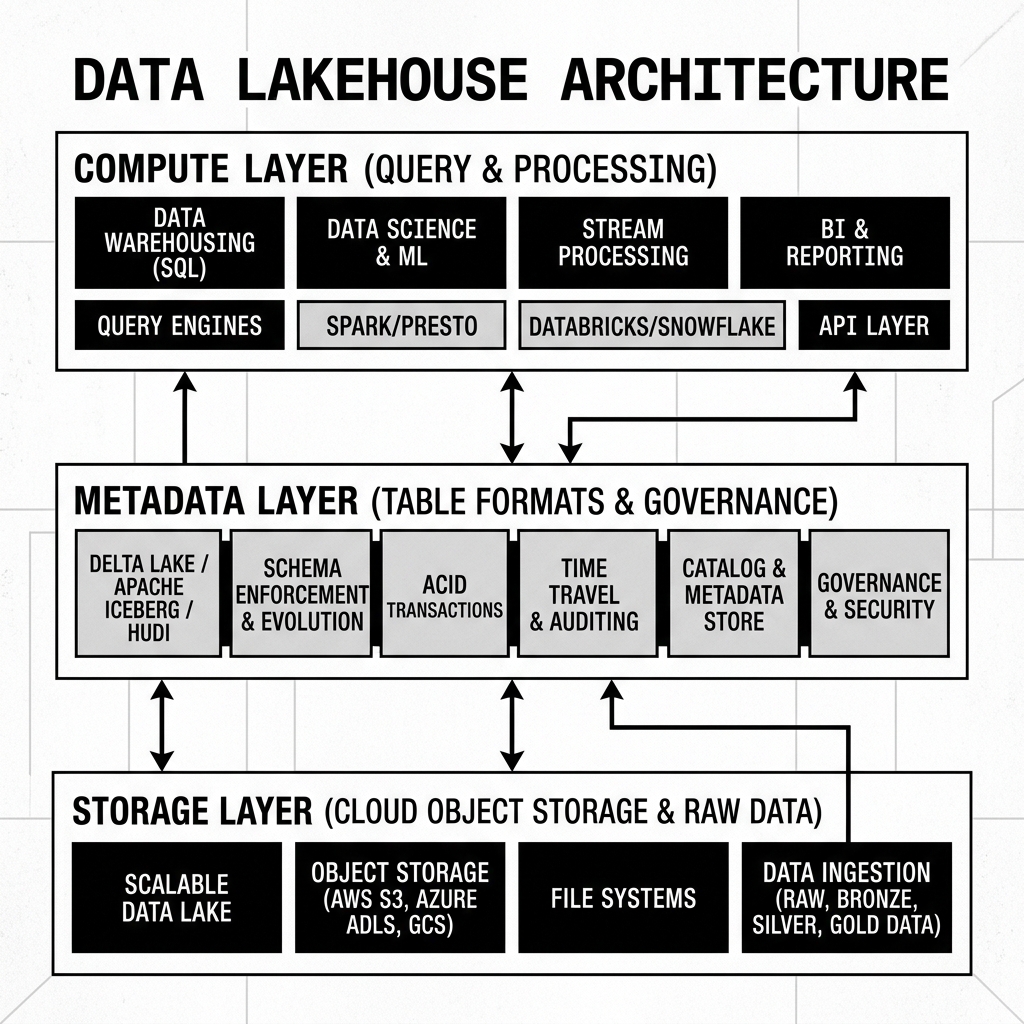
At its foundation, a data lakehouse relies on the separation of compute and storage. Storage is handled by scalable object stores like Amazon S3, Azure Blob Storage, or Google Cloud Storage. Compute is handled by elastic, distributed query engines like Apache Spark, Trino, Dremio, or Snowflake. The critical component that binds the compute and storage layers together to form a true “lakehouse” is the Open Table Format.
Open table formats, such as Apache Iceberg, Delta Lake, or Apache Hudi, act as the semantic layer that provides warehouse-like capabilities on top of raw parquet files sitting in object storage. They bring ACID transactions, schema enforcement, time travel, and hidden partitioning to the data lake. Before the advent of these table formats, updating a single row in a massive data lake required rewriting entire directories of data. With table formats, the lakehouse can track changes at the file level using metadata, allowing for fine-grained updates, deletes, and concurrent reads and writes without risking data corruption.
This architecture enables a single source of truth. Organizations no longer need to extract data from the data lake, transform it, and load it into a proprietary data warehouse just to run SQL queries. Instead, the data remains in its open format in the lake, and various specialized compute engines can query it directly in place.
Diagram 1: Conceptual Architecture
Implementation and Operations
Implementing a data lakehouse requires careful consideration of the tools and layers involved. The storage layer is generally the easiest to establish, as cloud providers offer highly durable object storage out of the box. The complexity arises when configuring the catalog and table format layer.
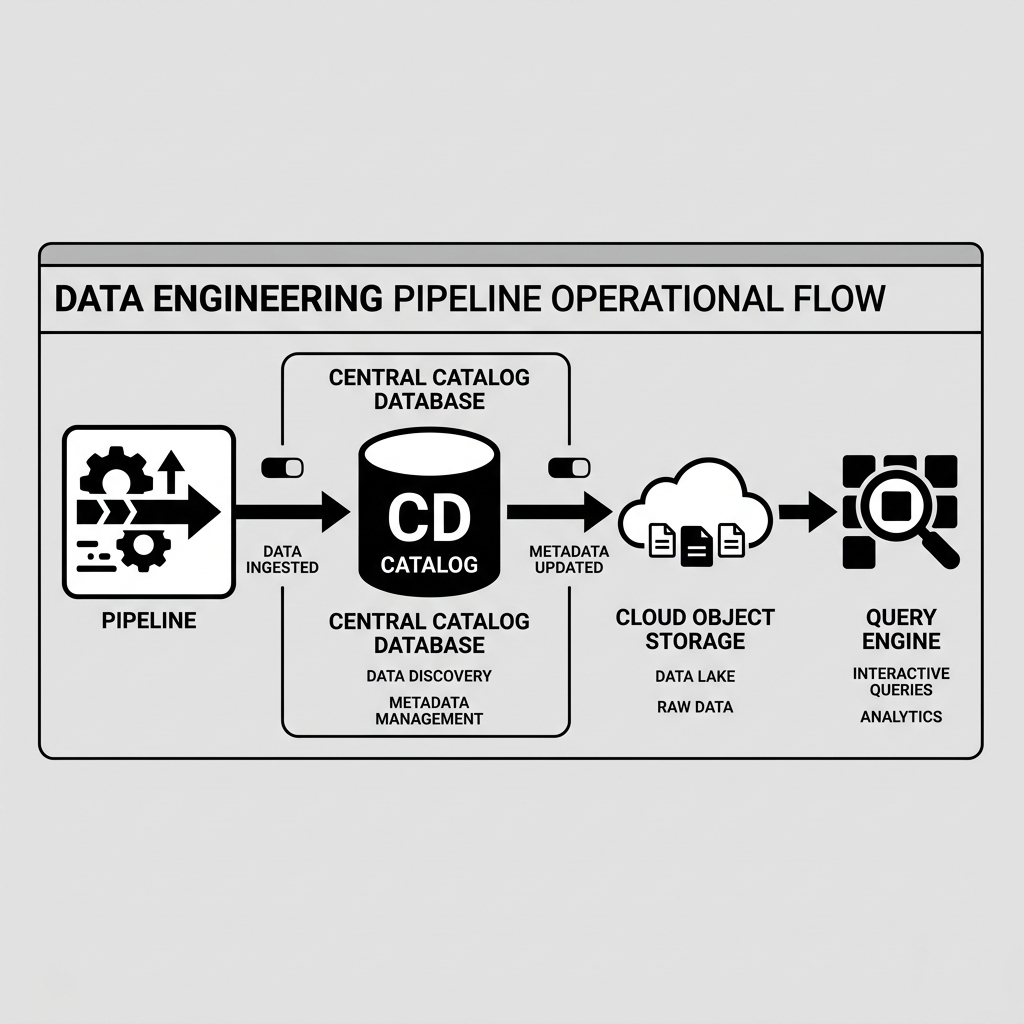
The catalog acts as the central registry for all tables in the lakehouse. When a compute engine wants to query a table, it first asks the catalog for the current state of that table. The catalog points the engine to the correct metadata file, which in turn points to the correct manifest files and data files. This process ensures that all compute engines have a consistent view of the data. Popular catalogs include the Iceberg REST Catalog, Project Nessie, AWS Glue, and Unity Catalog.
Once the catalog is established, data engineers must design the ingestion pipelines. In a lakehouse, data is typically ingested using a multi-hop or medallion architecture. Raw data is landed in a “Bronze” zone. It is then cleaned, filtered, and transformed into a “Silver” zone. Finally, business-level aggregates and high-quality data products are materialized in a “Gold” zone. Because the data lakehouse supports ACID transactions, streaming engines like Apache Flink can continuously append data to the Bronze tables while batch jobs incrementally process that data into the Silver and Gold tables simultaneously.
Maintenance operations are another critical aspect of running a data lakehouse. Because data is stored as thousands of small Parquet files, read performance can degrade over time. Data engineers must run periodic compaction jobs to merge small files into larger, more optimal file sizes. Additionally, operations like snapshot expiration and orphan file removal are necessary to prevent storage costs from ballooning over time. The open nature of the lakehouse means that these maintenance operations can be performed by any compatible compute engine.
Diagram 2: Operational Flow
Summary and Tradeoffs
The data lakehouse represents a massive leap forward in data platform architecture. It breaks down data silos by standardizing on open formats, allowing organizations to use the best compute engine for the job without being locked into a single vendor’s ecosystem. A machine learning team can use Apache Spark to train models, a business intelligence team can use Dremio to build interactive dashboards, and a data engineering team can use Apache Flink for real-time ingestion, all operating on the exact same underlying data without making copies.
However, building a data lakehouse is not without tradeoffs. Unlike a fully managed data warehouse, a data lakehouse requires an organization to assemble and maintain the various layers themselves. The engineering team must manage the catalog, configure the compute engines, and orchestrate the maintenance tasks like compaction and vacuuming. While managed lakehouse platforms exist, organizations choosing to build a pure open-source lakehouse must be prepared to invest in the necessary data engineering talent to support it.
Despite these complexities, the benefits of the data lakehouse far outweigh the costs for most modern data-driven organizations. By providing a single, open, and reliable source of truth, the data lakehouse accelerates the delivery of data products and reduces total cost of ownership.