Data Lineage
Data Lineage is the documented record of how data moves, transforms, and evolves through an analytical system — from its origination at source systems through every transformation, aggregation, and enrichment step, to its final presentation in dashboards, reports, and AI model training datasets. It answers the most operationally critical question in data governance: “Where did this number come from, and what transformations produced it?”
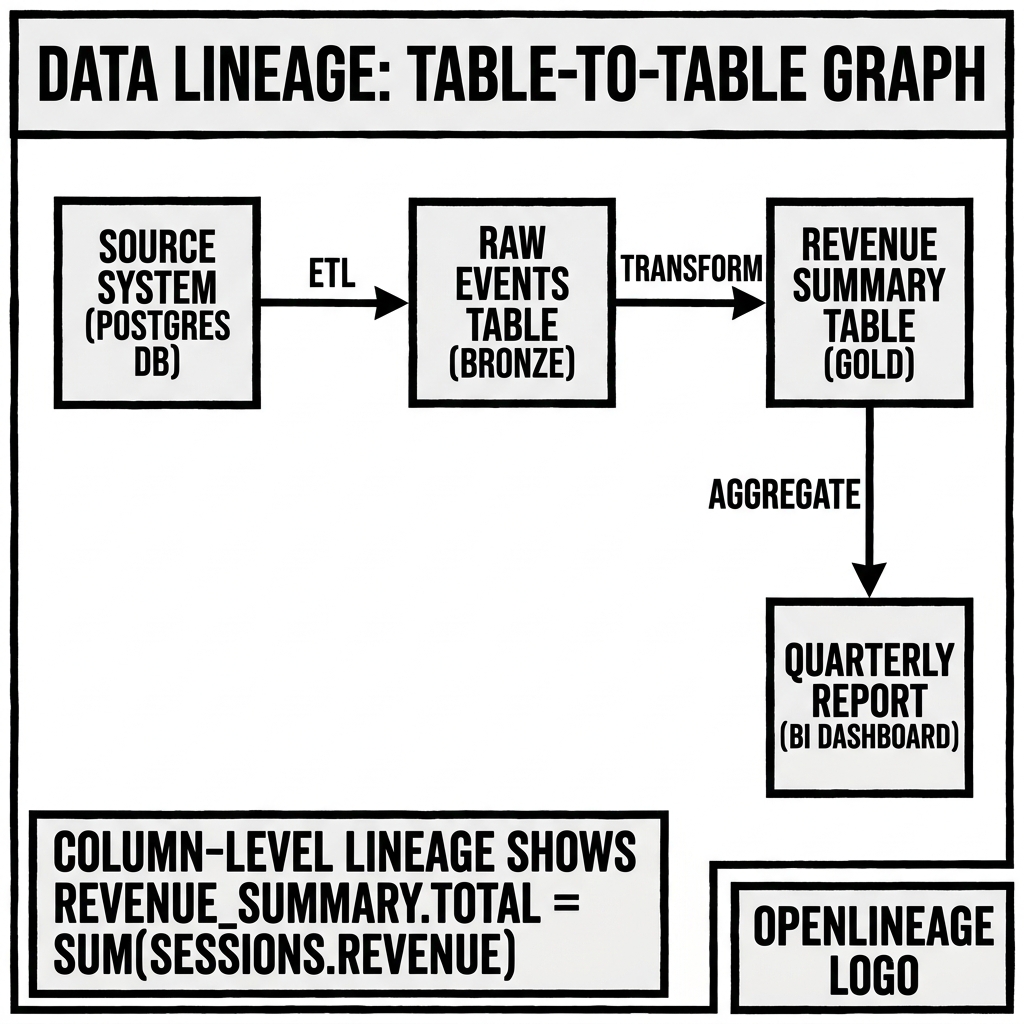
In the data lakehouse context, lineage operates at multiple granularities simultaneously. At the table level, lineage tracks which source tables were read to produce each downstream table. At the column level (fine-grained lineage), it tracks which source columns contributed to each output column — identifying not just that gold.orders_summary derives from silver.orders, but specifically that gold.orders_summary.total_revenue is computed from silver.orders.unit_price * silver.orders.quantity with a SUM() aggregation. At the snapshot level, Iceberg’s immutable snapshot history provides an intrinsic form of time-bounded lineage — a complete record of every state the table has ever existed in.
Why Data Lineage Matters
Trust and Transparency
Data lineage is foundational to building analyst trust in data products. When a business analyst questions why a KPI changed between last month and this month, lineage allows the data engineering team to trace exactly which upstream data change caused the downstream metric change — or to verify that the metric definition itself changed. Without lineage, debugging data quality issues is a manual, time-consuming investigation. With lineage, the impact chain is immediately visible.
Regulatory Compliance
GDPR’s “right to be forgotten” (Article 17) requires that organizations be able to identify and delete all data relating to a specific individual across all systems. Without column-level lineage, complying with a deletion request requires manually tracing which tables contain the individual’s data — an error-prone, labor-intensive process. With lineage, the system can automatically identify all tables that contain or derive from the individual’s data, enabling automated compliance workflows.
CCPA, HIPAA, SOX, and financial regulatory frameworks have similar data traceability requirements. The regulatory auditor’s question “show me every system that touched this customer’s financial data” is only answerable with comprehensive lineage.
Impact Analysis
When a source table’s schema changes (a column is renamed, a column type changes, a column is dropped), impact analysis answers: “which downstream tables and reports will break?” Without lineage, this analysis requires manually reviewing every ETL job, every SQL view, and every BI report to identify dependencies. With lineage, the catalog can automatically identify all downstream consumers of the changed column.
AI Model Governance
As AI models increasingly train on lakehouse data, lineage becomes the mechanism for documenting which specific table snapshots, with what schemas, at what point in time, were used as training data. This training data lineage is required for:
- Model reproducibility: Re-training with the same data to verify model behavior.
- Model auditing: Demonstrating to regulators which data influenced a model’s decisions.
- Bias tracing: Identifying whether biased training data is the source of biased model outputs.
Types of Data Lineage
Technical Lineage (Table and Column Level)
Technical lineage is captured from the actual SQL and compute job execution: parsing the SQL text of ETL jobs, views, and stored procedures to identify the tables read and written, and the column-level transformations applied.
Table-level lineage: Table A and Table B were read; Table C was written. Captured by parsing FROM and JOIN clauses (sources) and INSERT INTO / CREATE TABLE AS (targets).
Column-level lineage: The total_revenue column in Table C is derived from the expression SUM(unit_price * quantity) applied to the unit_price and quantity columns from Table A. Capturing column-level lineage requires parsing and understanding the SQL expression graph, not just the table references.
Lineage granularity vs. complexity trade-off: Column-level lineage is far more valuable than table-level lineage for impact analysis and compliance, but capturing it requires significantly more sophisticated SQL parsing infrastructure (particularly for complex SQL dialects with CTEs, subqueries, window functions, and UDFs).
Operational Lineage (Job Runs)
Operational lineage tracks specific job executions — including timestamps, parameters, output volumes, and execution status — providing an audit trail of when each transformation ran and what it produced. This is the lineage that enables “which specific job run created the current state of this table?” questions.
Snapshot-Level Lineage in Iceberg
Apache Iceberg’s snapshot history provides an inherent form of operational lineage at the table level. Each Iceberg snapshot includes:
snapshot-id: The unique identifier of this specific table state.parent-snapshot-id: The snapshot ID that this snapshot was produced from (the “parent” in the lineage chain).operation: The type of operation that produced this snapshot (append,overwrite,replace,delete).summary: Metadata about the operation, including the number of added files, deleted files, and records.timestamp-ms: When this snapshot was created.
By traversing the snapshot parent chain, any Iceberg table’s complete write history is reconstructable: snapshot N was produced by operation X at time T from snapshot N-1, which was produced by operation Y at time T-1 from snapshot N-2, and so on back to the initial snapshot.
This snapshot lineage is native to every Iceberg table and requires no additional lineage infrastructure. It is the starting point for time travel queries — “show me the table as it existed in snapshot 12345” — and for write audit trails — “who wrote to this table and when?”
What Iceberg snapshot lineage does not capture is cross-table lineage: the fact that snapshot N of Table C was produced by a job that read from Tables A and B. That cross-table relationship requires tracking at the ETL job level.
Logical Lineage
Logical lineage tracks the business-level relationships between data assets rather than the technical transformation relationships. A logical lineage graph might document:
- The
customer_lifetime_valuemetric is defined in terms of theorders,returns, andcustomer_segmentstables. - The
quarterly_revenue_reportdashboard consumes data from thefinance.revenue_summarygold-layer table. - The
churn_risk_modeltrains on theml.training_featuresfeature table, which derives from thecustomer_eventsraw events table.
Logical lineage is often managed in data catalog tools (Atlan, DataHub, Alation, Collibra) and may be partially automated (through connector integrations with BI tools and ML platforms) and partially manual (business stakeholders documenting the conceptual meaning of lineage relationships).
Lineage Capture Mechanisms
SQL Parsing at Execution Time
The most complete and accurate approach to automatic lineage capture is SQL parsing at query execution time: the query engine (or a middleware layer) parses every executed SQL statement, extracts the lineage graph (source tables and columns → target tables and columns), and records it in a lineage store.
Spark lineage is commonly captured through the SparkListener API: a custom lineage listener attaches to the Spark context and receives LogicalPlan events for every executed query, which can be analyzed for lineage by traversing the query plan tree.
Trino lineage can be captured through the Trino EventListener interface: a custom event listener receives completed query events with the parsed query plan, which can be analyzed for lineage by examining the plan’s source and target node types.
Catalog-Native Lineage
Unity Catalog automatically captures lineage for tables accessed or written through Databricks Runtime (Spark, Dremio-on-Databricks). Column-level lineage is captured for SQL, Python DataFrame, and Spark operations. The lineage data is accessible through the Unity Catalog Lineage API and visible in the Databricks UI’s table lineage graph view.
Unity Catalog’s lineage includes:
- Which notebooks or jobs wrote to each table.
- Which upstream tables each table reads from.
- Column-level lineage for SQL transformations.
- Lineage to and from BI tools (Tableau, Power BI) that query through Databricks SQL endpoints.
OpenLineage: The Open Standard
OpenLineage is an open specification (now a Linux Foundation project) for capturing and exchanging data lineage across heterogeneous systems. It defines a standard event format that any ETL framework, query engine, or data tool can emit when starting and completing data transformation jobs.
The OpenLineage event model includes:
- Job: The transformation process (a Spark job, a dbt model, an Airflow DAG).
- Run: A specific execution of the job, with a unique run ID, start time, and end time.
- Dataset: The tables read (inputs) and written (outputs) by the run.
- Facets: Extensible metadata attached to jobs, runs, and datasets — including column-level lineage facets for fine-grained transformation tracking.
Major integrations: Apache Spark (via the OpenLineage Spark integration jar), Apache Flink (via the OpenLineage Flink integration), dbt (via the dbt-openlineage integration), Airflow (via the OpenLineage Airflow provider), and Amazon Glue (via the Glue lineage integration).
Marquez is the open-source reference implementation of an OpenLineage backend — a REST API service that receives OpenLineage events and stores them in a PostgreSQL database, with a web UI for visualizing lineage graphs.
Atlan, DataHub, Alation, and other commercial data catalog tools implement OpenLineage ingestion, becoming the lineage store and visualization layer for organizations using OpenLineage-compatible tools.
Lineage Visualization and Exploration
Lineage data is most valuable when it is navigable through a visual interface that allows data engineers, analysts, and governance teams to:
Navigate upstream: From a dashboard metric, trace back through the semantic layer view → gold table → silver transformation → bronze raw data → source system. Each step shows the transformation logic and the timestamp when that step ran.
Navigate downstream (impact analysis): From a source column being changed, see all downstream tables and columns that derive from it. The impact graph shows the blast radius of a schema change before it is made.
Filter by time: See the lineage graph as it existed at a specific point in time — which tables existed and which transformation relationships were active at the time of a specific audit event.
Annotate lineage relationships: Business stakeholders can add logical annotations to technical lineage edges — explaining why a specific transformation exists, what business process it supports, and who is responsible for maintaining it.
Conclusion
Data lineage is the accountability infrastructure of the data lakehouse — the mechanism that makes data quality issues debuggable, regulatory compliance demonstrable, schema changes manageable, and AI model provenance documentable. Iceberg’s native snapshot history provides the foundational time-ordered write audit trail at the individual table level; OpenLineage and catalog-native lineage (Unity Catalog, DataHub) extend this to cross-table and column-level transformation tracking across the entire data estate. Organizations investing in comprehensive lineage capture — through OpenLineage-integrated ETL tools, catalog-native lineage APIs, and visual lineage exploration tools — gain the operational transparency and governance assurance that scale-out analytical systems require. Lineage is not a nice-to-have feature: at the scale and regulatory complexity of modern enterprise data lakehouses, it is an operational necessity.
Visual Architecture