Data Mesh
For most of the 2010s, the standard blueprint for a modern data platform involved building a centralized data lake, staffing a central data engineering team to manage it, and routing every data request through that team. This approach worked reasonably well when data volumes were manageable and the number of data consumers was limited. But as organizations scaled, the central data team became an unavoidable bottleneck. Business teams waited weeks for new datasets to be made available. Data pipelines broke and sat unrepaired because the central team was overwhelmed. The lake accumulated datasets that no one documented because the engineers who built the pipelines had no real knowledge of the underlying business domain they were serving.
Data Mesh, introduced by Zhamak Dehghani in her 2019 article “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh,” is a paradigm shift in response to these systemic failures. Rather than centralizing data ownership, Data Mesh proposes distributing it. Each business domain, such as Sales, Marketing, or Customer Support, is responsible for owning, managing, and publishing the data that originates from its own operations. The data platform team’s role shifts from being the owners of all data to being the providers of the infrastructure that enables domain teams to manage their own data.
The Four Principles of Data Mesh
Zhamak Dehghani defined Data Mesh through four interconnected principles that together constitute the full paradigm.
1. Domain Ownership: The first principle holds that data should be owned and served by the domain that generates it. The sales team knows sales data better than any central data engineering team ever could. They understand the business rules, the edge cases, the meaningful attributes, and the transformations that produce trustworthy metrics. By placing ownership with the domain, Data Mesh aligns accountability with knowledge. If the Sales team’s “Revenue” data product is wrong, the Sales team is responsible for fixing it, and they have the context to do so effectively.
2. Data as a Product: Simply owning data is not enough. The second principle requires that each domain team treat its data as a product, not as a byproduct of its operational systems. A data product must meet strict quality standards: it must be discoverable (registered in a catalog with clear documentation), addressable (accessible via a stable, versioned URI or endpoint), understandable (with a clear schema and semantic definition), trustworthy (with documented SLAs for freshness and accuracy), interoperable (following agreed-upon standards for format and access), and secure (with explicit access controls). This product thinking shifts the culture from “we dumped the data in the lake” to “we maintain a reliable data service for our consumers.”
3. Self-Serve Data Infrastructure: For domain teams to own and manage their own data products, they need tools that do not require deep data engineering expertise to operate. The third principle mandates that the central platform team build a self-serve data infrastructure platform. This platform should make it easy for a domain team to create a new data pipeline, register a new table in the catalog, define data quality checks, configure access controls, and monitor the health of their data products, all without needing to file tickets with a central data engineering team. Tools built on top of open table formats like Apache Iceberg are well-suited to this, since they provide a standardized, engine-agnostic interface for managing tables.
4. Federated Computational Governance: The fourth principle acknowledges the tension between decentralization and coordination. If every domain team makes entirely independent decisions about data formats, naming conventions, and access patterns, interoperability breaks down. Federated governance establishes a set of global standards and policies that all domain teams must adhere to, such as consistent use of a specific table format, a shared identity and access management system, and common data quality benchmarks. Critically, this governance model is enforced computationally via automated tooling rather than manual approval processes, so it scales with the organization.
Diagram 1: Conceptual Architecture
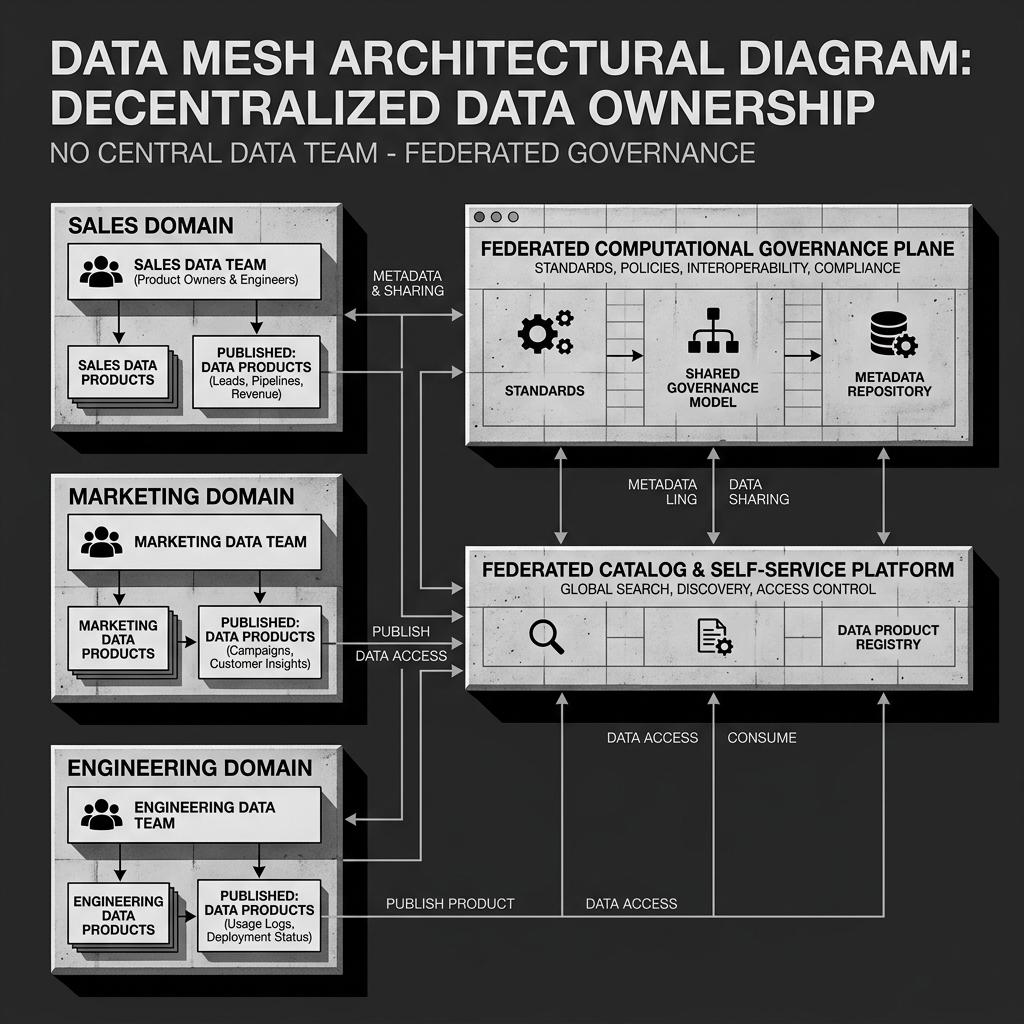
Data Mesh vs. Data Lakehouse
A common point of confusion is how Data Mesh relates to the Data Lakehouse architecture. They operate at different levels of the stack and are complementary rather than competing.
The Data Lakehouse is a storage and compute architecture. It defines how data is stored (Parquet files in object storage), how it is organized (via an open table format like Apache Iceberg), and how it is queried (via distributed compute engines like Dremio or Trino). It is a technical blueprint for a reliable, scalable data platform.
Data Mesh is an organizational and ownership architecture. It defines who is responsible for which data, how data should be treated as a product, and how governance should be federated across an enterprise. It is a sociotechnical blueprint for scaling data management across large organizations.
Many organizations implement a Data Mesh architecture that runs on top of a Data Lakehouse. Each domain team owns and manages Iceberg tables within a shared storage account, registered in a shared catalog. The Data Lakehouse provides the technical infrastructure that makes the Data Mesh operationally possible by providing a standard, interoperable table format that all domain teams use regardless of which compute engine they prefer.
Diagram 2: The Four Principles
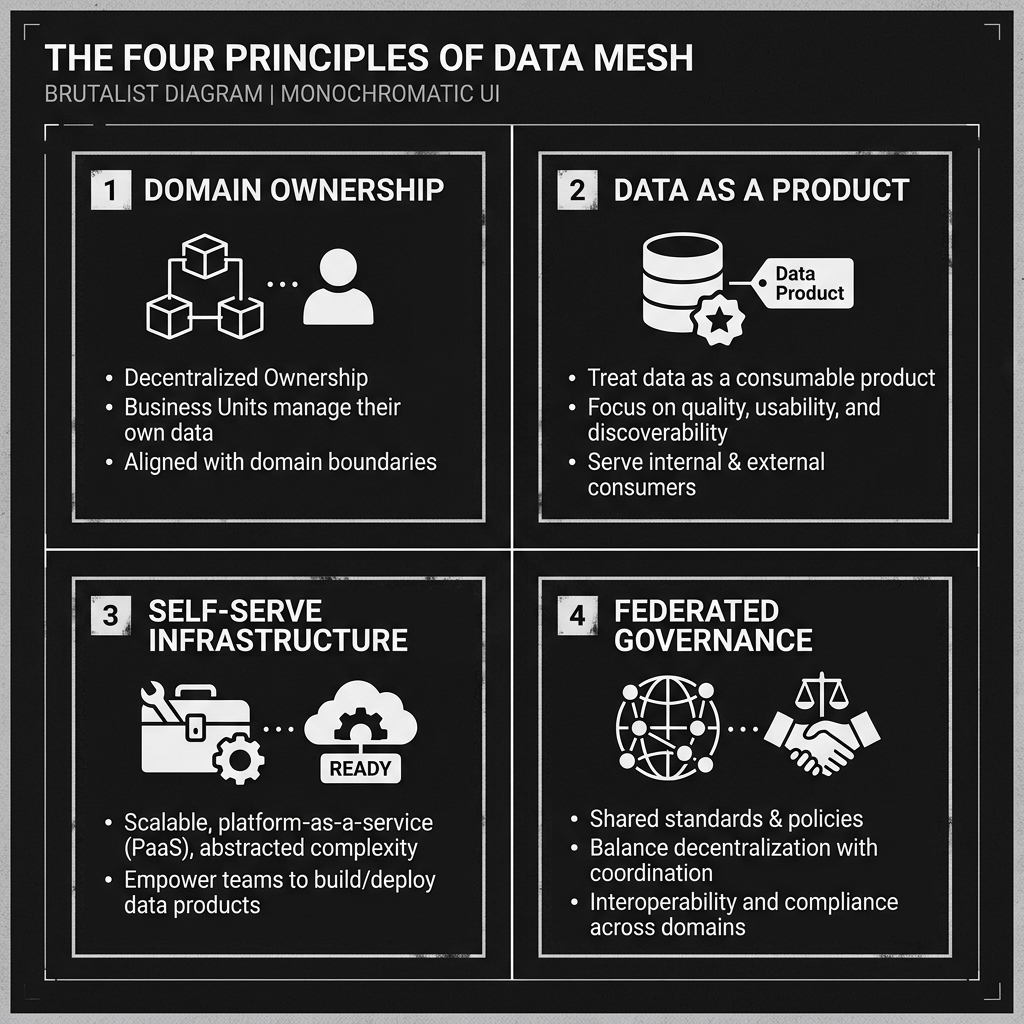
Practical Implementation Challenges
Data Mesh is an attractive philosophy, but it is genuinely difficult to implement in practice. The most common challenge is organizational. Most enterprises have built their data platforms around centralized teams, and shifting data ownership to domain teams requires significant cultural change. Business domain teams often resist taking on what they perceive as an additional burden. They are already responsible for their operational systems and cannot easily absorb the extra work of managing, documenting, and maintaining data products without adequate tooling and support.
The second challenge is standardization. Without strong federated governance and automated enforcement, decentralization quickly leads to fragmentation. Each domain team picks its preferred tools and formats, and suddenly the “interoperable data mesh” is actually fifty different incompatible data silos managed by different teams with different skill levels.
For organizations that successfully navigate these challenges, the payoff is substantial. Data products are higher quality because they are owned by teams with deep domain expertise. Time-to-insight is shorter because domain teams can update their own datasets without waiting for a central team. The overall data platform scales with the organization because data ownership distributes as the company grows, rather than piling up on a single overloaded central team.