Data Quality
Data Quality is the set of properties, practices, and enforcement mechanisms that ensure data assets in a lakehouse are fit for the purposes for which they are used. It encompasses accuracy (data reflects the real-world facts it represents), completeness (no required values are missing), consistency (the same information in different tables agrees), timeliness (data is current enough for its use case), uniqueness (records are not duplicated where uniqueness is required), and validity (values conform to expected formats and constraints).
Data quality is not a one-time remediation project — it is an ongoing operational discipline that must be integrated into the data pipeline architecture. In the data lakehouse, this means embedding quality checks at ingestion (bronze layer), enforcing schema and constraint evolution carefully, validating transformations before publishing to production, and continuously monitoring quality metrics in production data.
The Six Dimensions of Data Quality
Accuracy
Data accurately represents the real-world facts it is supposed to model. An orders table has quality issues if it contains orders with negative prices, future-dated transactions beyond the current date, or customer IDs that don’t exist in the customers table.
Accuracy validation requires domain-specific rules that go beyond schema validation — they require understanding the business constraints on what valid data looks like in a specific domain.
Completeness
Required values are present and non-null. A customers table with an email field that is NULL for 40% of rows has a completeness issue if email is required for the business process the table supports.
Completeness checks are typically the simplest to implement and the most frequently triggered quality issues in raw ingestion pipelines, where source systems may omit optional fields for some record types.
Consistency
Data tells the same story across different tables and systems. If orders.total_amount in the orders table and payments.amount_received in the payments table should sum to the same total for a given period, a consistency check verifies they do. Inconsistency between tables is a common symptom of ETL bugs, incomplete upserts, or race conditions in multi-table write pipelines.
Timeliness
Data is current enough for its use case. A real_time_inventory table should have rows updated within the last hour; if the most recent update was 24 hours ago, the data is stale and may not meet the timeliness requirement for real-time inventory management decisions.
Timeliness is measured by comparing the maximum event timestamp in the data (or the last ingestion timestamp) against the current time and the maximum acceptable lag for the use case.
Uniqueness
Records that should be unique are not duplicated. A customers table should have at most one row per customer_id; if a customer appears twice with different email addresses, there is a uniqueness violation that may cause downstream joins to fan out and produce incorrect aggregations.
Uniqueness violations are particularly damaging in star schema fact and dimension table relationships, where duplicate dimension records cause duplicated fact rows after joins.
Validity
Values conform to expected formats, ranges, and reference domains. A birth_date column should contain valid dates not in the future; a country_code column should contain valid ISO 3166-1 alpha-2 codes; a email column should match the email format regex.
Data Quality Enforcement in the Lakehouse Pipeline
Bronze Layer: Schema Enforcement at Ingestion
The bronze layer (raw data) is where the first quality enforcement should occur. Even “raw” data should pass minimal quality checks before being committed to the lakehouse:
Schema enforcement: Validate incoming records against the expected schema before writing them to the bronze Iceberg table. Records with unexpected columns, wrong column types, or missing required fields should be routed to a dedicated error/quarantine table rather than being silently dropped or corrupting the primary table.
Null checking: Flag records with null values in columns declared as NOT NULL. In Iceberg, columns can be declared as required in the schema specification, and Iceberg write operations will fail if required columns contain nulls in the written data (depending on the write mode configuration).
Format validation: Check that string columns representing structured values (dates, emails, phone numbers) match the expected format before ingesting.
Iceberg does not enforce business-level constraints at the format level (no CHECK constraints like traditional RDBMS), so format validation must be implemented in the ingestion pipeline (Spark, Flink, Kafka Streams) before writing to Iceberg.
Silver Layer: Validation Before Promotion
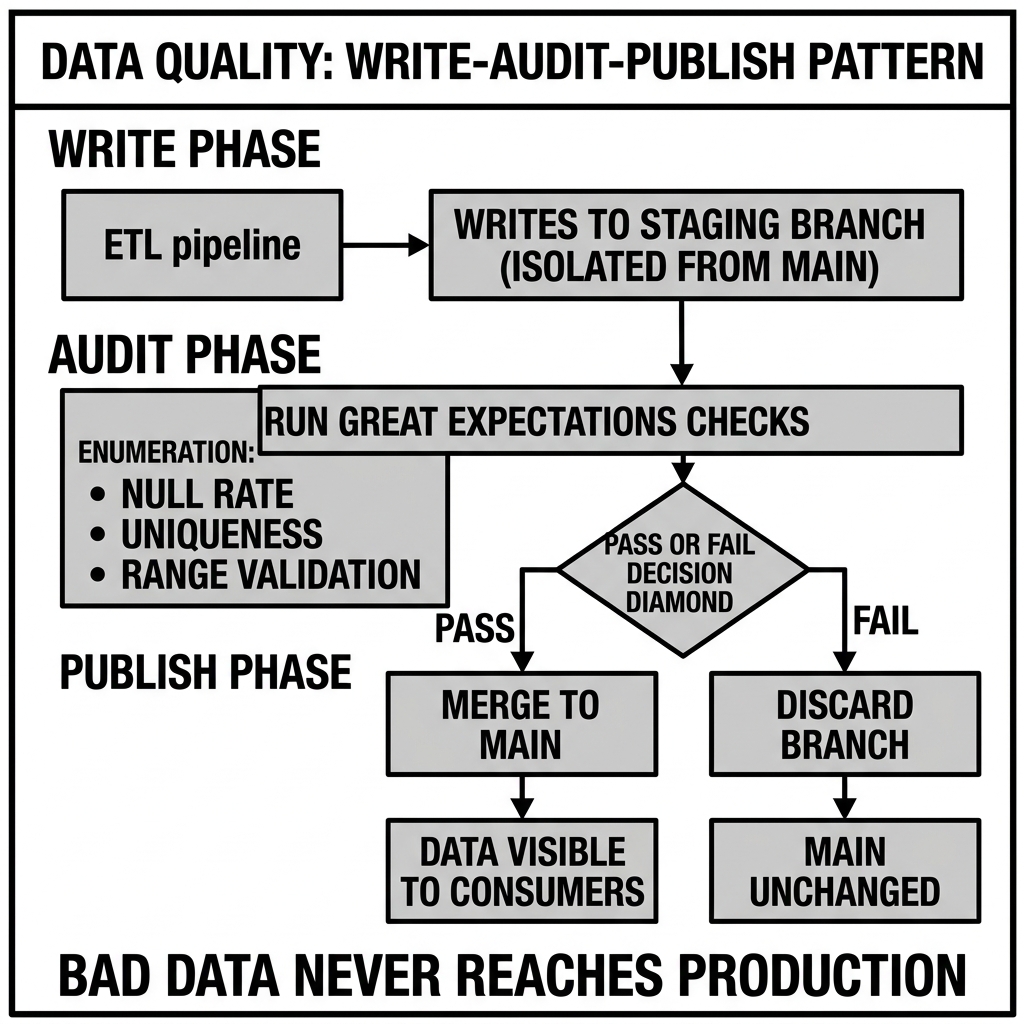
The silver layer transformation is where the most comprehensive quality validation should occur — before data is promoted to the gold layer and consumed by BI tools and AI models. The Write-Audit-Publish (WAP) pattern, described in the Project Nessie article, is the architectural framework for silver-layer quality enforcement:
Write: Transform and write the new data to a staging branch (in Nessie) or a staging table. Audit: Run the full quality check suite against the staged data. Publish: Merge to main / promote to production only if all quality checks pass.
This pattern ensures that quality failures block data from reaching production consumers — rather than the traditional “publish then fix” approach where quality issues are discovered only after they have already affected downstream reports and dashboards.
Gold Layer: Monitoring in Production
Even data that passed quality checks at the silver layer can develop quality issues in production through accumulation of new data, changes in upstream data distributions, or model drift in derived metrics. Production quality monitoring tracks quality metrics continuously and alerts when they degrade:
- Row count anomalies: Is the table growing at its expected rate? (A sharp drop may indicate a missed ingestion run; a sharp spike may indicate duplicate ingestion.)
- Null rate trends: Is the null rate in key columns increasing over time? (May indicate changes in the upstream source system.)
- Distribution drift: Are the value distributions of key columns changing significantly? (Important for ML feature stores.)
- Cross-table consistency: Do derived metrics match their source data?
Quality Tooling for the Lakehouse
Great Expectations
Great Expectations (GX) is the most widely used open-source data quality framework for the Python/Spark/Pandas data engineering ecosystem. It provides:
Expectations: Declarative assertions about data properties — “the customer_id column should have no nulls,” “the order_amount column should be between 0 and 10,000,” “the status column should only contain values from the set [‘pending’, ‘shipped’, ‘delivered’, ‘returned’].”
Expectation Suites: Named collections of Expectations that define the complete quality contract for a specific dataset.
Checkpoints: Configured validation runs that apply an Expectation Suite to a specific data batch and produce a Validation Result (pass/fail with details on each Expectation’s outcome).
Data Docs: Auto-generated HTML documentation that shows the current Expectation Suites and the results of recent validation runs — a living quality contract document accessible to all data stakeholders.
Integration with Iceberg: GX can validate Iceberg table data by reading it into a Spark or pandas DataFrame and running the Checkpoint against the DataFrame. GX does not yet provide native Iceberg snapshot-level Expectations, but the integration is functionally complete for most use cases.
dbt Tests
dbt (data build tool) embeds data quality tests directly in the transformation layer as a first-class feature. dbt tests come in two forms:
Singular tests: SQL queries that return rows when a quality condition is violated (returning zero rows means the test passes):
-- tests/order_amounts_positive.sql
SELECT *
FROM {{ ref('silver_orders') }}
WHERE order_amount <= 0Generic tests (applied via YAML configuration):
# models/silver/schema.yml
models:
- name: silver_orders
columns:
- name: order_id
tests:
- not_null
- unique
- name: customer_id
tests:
- not_null
- relationships:
to: ref('silver_customers')
field: customer_id
- name: order_amount
tests:
- not_null
- dbt_expectations.expect_column_values_to_be_between:
min_value: 0
max_value: 100000dbt’s dbt-expectations extension package provides Great-Expectations-inspired generic tests for dbt, dramatically expanding the built-in test vocabulary.
dbt tests run as part of the dbt test command, which can be integrated into CI/CD pipelines to block model promotion when quality tests fail.
dbt Data Contracts
dbt’s Data Contracts feature (available in dbt 1.5+) allows defining formal contracts on dbt models — specifying the expected schema (column names and types) and quality constraints that must be maintained. When a model’s SQL would produce output that violates its contract (e.g., a column changes from BIGINT to STRING), dbt raises an error and blocks the build.
Data contracts formalize the quality SLA for a model’s consumers: downstream teams can trust that the model will always conform to the contract’s specifications, enabling confident long-term dependency on the model’s outputs.
Iceberg Write-Time Quality Validation with Spark
For teams using Spark to write to Iceberg, quality validation can be embedded directly in the Spark write pipeline:
from pyspark.sql.functions import col, when, count
def validate_orders(df):
"""Validate the orders DataFrame before writing to Iceberg."""
issues = []
# Completeness: no null order_ids
null_order_ids = df.filter(col("order_id").isNull()).count()
if null_order_ids > 0:
issues.append(f"NULL order_id count: {null_order_ids}")
# Validity: no negative amounts
negative_amounts = df.filter(col("order_amount") < 0).count()
if negative_amounts > 0:
issues.append(f"Negative order_amount count: {negative_amounts}")
# Uniqueness: no duplicate order_ids
total = df.count()
distinct = df.select("order_id").distinct().count()
if total != distinct:
issues.append(f"Duplicate order_id count: {total - distinct}")
if issues:
raise ValueError(f"Data quality validation failed: {', '.join(issues)}")
return df
# Validate before writing
validated_df = validate_orders(transformed_df)
validated_df.writeTo("analytics.silver.orders").append()This pattern prevents any write to the Iceberg table if quality checks fail, ensuring that quality failures block data persistence rather than silently allowing bad data to be committed.
Data Observability Platforms
Monte Carlo, Bigeye, Soda, and Anomalo are commercial data observability platforms that provide continuous, automated quality monitoring for production data assets:
- Automated anomaly detection: Machine learning models learn the expected behavior (row counts, null rates, value distributions) of each table and alert when observations deviate significantly from the learned baseline.
- Schema change detection: Alerting when columns are added, dropped, or their types change.
- Freshness monitoring: Alerting when tables haven’t been updated within their expected refresh window.
- Cross-table consistency monitoring: Alerting when related metrics in different tables diverge beyond expected bounds.
These platforms typically integrate with data catalogs (Iceberg REST Catalog, Glue, Unity Catalog) and query engines (Spark, Trino, Athena) to collect the metadata and statistics needed for quality monitoring without requiring users to write custom monitoring queries.
Quality as a First-Class Lakehouse Citizen
The most mature lakehouse data quality programs treat quality as a first-class table attribute:
Quality scores: Each table in the catalog has a quality score (0–100) calculated from the outcomes of all quality checks run against the table. The quality score is visible in the data catalog browser and is used by data consumers to assess table trustworthiness before using the data.
Quality SLA contracts: Table owners publish formal quality SLAs — commitments on null rates, freshness, row count stability, and cross-table consistency — that downstream consumers can reference when building products on top of the data.
Ownership and accountability: Each table has a designated owner responsible for its quality. Quality alerts are routed to the owner, creating accountability for quality failures. Quality scores are included in data engineering team OKRs.
Conclusion
Data quality is the operational discipline that transforms a data lake from a storage repository into a trusted analytical platform. Its six dimensions — accuracy, completeness, consistency, timeliness, uniqueness, and validity — define the standards against which every table in the lakehouse must be measured. The tools (Great Expectations, dbt tests, data observability platforms) and patterns (WAP validation before promotion, write-time inline validation, continuous production monitoring) provide the implementation mechanisms for enforcing those standards throughout the data pipeline lifecycle. Organizations that treat data quality as an afterthought — a remediation exercise when analysts complain about bad data — consistently underperform those that embed quality enforcement into the pipeline architecture from day one. In the modern data lakehouse, quality is not a project; it is an infrastructure responsibility.
Visual Architecture