Data Swamp
The promise of the data lake was transformative. By accepting data in any format without requiring a predefined schema, organizations could suddenly store raw clickstream events, IoT sensor readings, server logs, PDF documents, and relational database exports all in one place, at a fraction of the cost of a traditional data warehouse. The problem, however, was that this openness required discipline. Without that discipline, the data lake quickly degenerated into something that data practitioners began calling a “Data Swamp.”
A data swamp is a data lake that has grown so disorganized, undocumented, and ungoverned that the data within it is effectively unusable. The data is there, technically. Petabytes of it. But no one knows what files contain what information, whether the data is still accurate, who owns which datasets, or whether any given file is the authoritative version or a duplicate created by a pipeline that ran twice. The data sits in the lake rotting, inaccessible to the business analysts and data scientists who need it.
Understanding what causes a data swamp is necessary before understanding how to prevent one. The causes are almost always organizational and process failures rather than purely technical ones.
How a Data Lake Becomes a Data Swamp
The first and most common path to a data swamp is the absence of a metadata catalog. When data engineering teams ingest data into the lake, they frequently focus entirely on getting the data in as quickly as possible. They create folders with names like dump_2024_03, backup_final_v2, or data_from_marketing_REVISED. Over time, hundreds of these directories accumulate. A new data analyst who joins the team six months later has absolutely no way of knowing which of these directories contains usable data, which is a duplicate, which is stale, or which belongs to a deprecated process.
Without a metadata catalog actively tracking what data exists, where it lives, who owns it, what format it is in, what its schema looks like, and what process created it, the lake is a black box. The cost of using the lake becomes higher than the cost of simply asking someone in another department to send you the data in a spreadsheet. That is the definition of a data swamp.
The second common cause is the lack of data quality enforcement at ingestion. A data lake that accepts everything without validation will inevitably accumulate large volumes of corrupted, incomplete, or simply wrong data. When downstream pipelines and machine learning models start producing incorrect results because of bad source data, users stop trusting the lake entirely. A lake that no one trusts is, functionally, a swamp.
The third cause is the lack of access controls and data ownership. In a healthy data lake, every dataset has a clear owner, an individual or team that is accountable for its quality, freshness, and documentation. When there is no ownership model, no one feels responsible for cleaning up outdated files, updating schemas, or improving documentation. The lake fills with abandoned datasets that no one dares delete because no one knows if someone downstream might still be using them.
Diagram 1: Data Swamp vs. Governed Data Lake
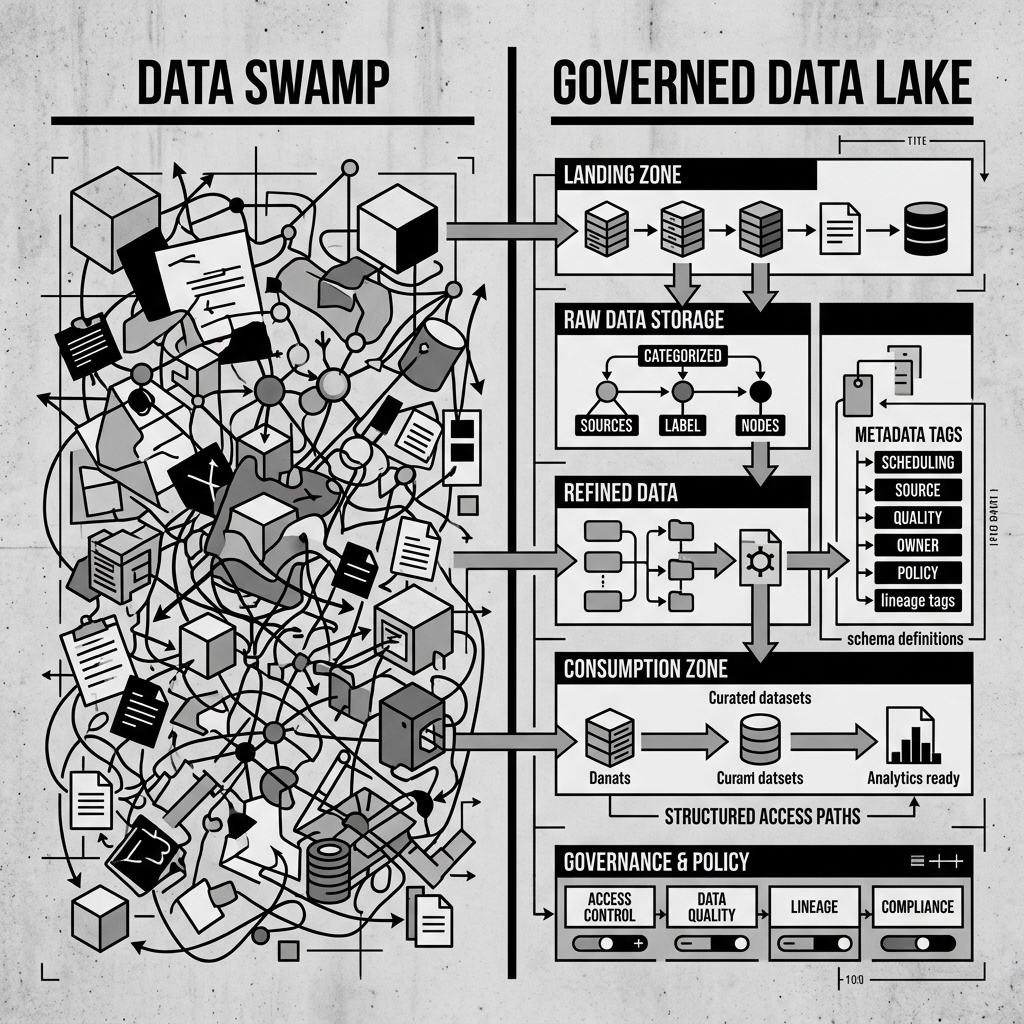
Recognizing the Warning Signs
A data lake does not become a swamp overnight. It happens gradually, usually over six to eighteen months, as the organizational structure fails to keep pace with the volume of data being ingested.
The warning signs are practical and observable. First, data analysts begin spending more time searching for data than actually analyzing it. When an analyst spends three hours trying to figure out which of twelve similarly named files contains the authoritative version of last quarter’s sales data, the lake has a discoverability problem.
Second, data pipelines begin breaking because upstream schema changes go undocumented. If an ingestion pipeline quietly changes the format of a date column from ISO 8601 to a Unix timestamp, and there is no schema registry or data contract in place to broadcast that change, every downstream job that reads that column will silently produce incorrect results or crash outright.
Third, storage costs begin escalating without a corresponding increase in business value. A data swamp tends to accumulate data that could be deleted or archived, because no one has the confidence or authority to clean up files they did not personally create.
Fourth, regulatory audits become nightmares. If your organization stores personal data in the lake and a GDPR deletion request comes in, finding every file across the entire lake that contains that specific user’s data is nearly impossible without proper data lineage tracking.
The Governance Framework Solution
Preventing a data swamp is not primarily a technology problem; it is an organizational and process problem. However, technology is the enabling layer that makes governance scalable across petabytes of data.
Data Cataloging is the foundational tool. A data catalog is a metadata management system that automatically crawls the data lake, infers schemas, and registers datasets in a searchable directory. It tracks the business description of each dataset, its technical schema, its source system, its last modified date, its owner, and ideally a sample of its data. Engineers must make registering new datasets in the catalog a mandatory step in every ingestion pipeline. Tools like Apache Atlas, AWS Glue Data Catalog, and DataHub enable organizations to build this foundation.
Data Quality Rules enforce that data meets a minimum standard before it enters the lake. These rules can be simple (the column customer_id must never be null) or complex (the ratio of orders with negative totals must not exceed 0.1% of the daily volume). Frameworks like Great Expectations and Apache Griffin allow data engineers to codify these rules as automated checks that run on every ingestion batch.
Data Lineage Tracking provides a complete, auditable map of where every piece of data originated, how it was transformed, and where it flows. When a dashboard report shows incorrect numbers, a team with proper lineage tracking can trace the anomaly backward through every transformation to find the exact ingestion step where the bad data entered the lake.
Schema Registries prevent silent breaking changes from corrupting downstream pipelines. A schema registry acts as a centralized repository for all the schemas used by data producers and consumers. Before a producer can change the schema of a dataset it writes to the lake, the registry validates that the change is backward-compatible with all registered downstream consumers.
Diagram 2: The Governance Framework
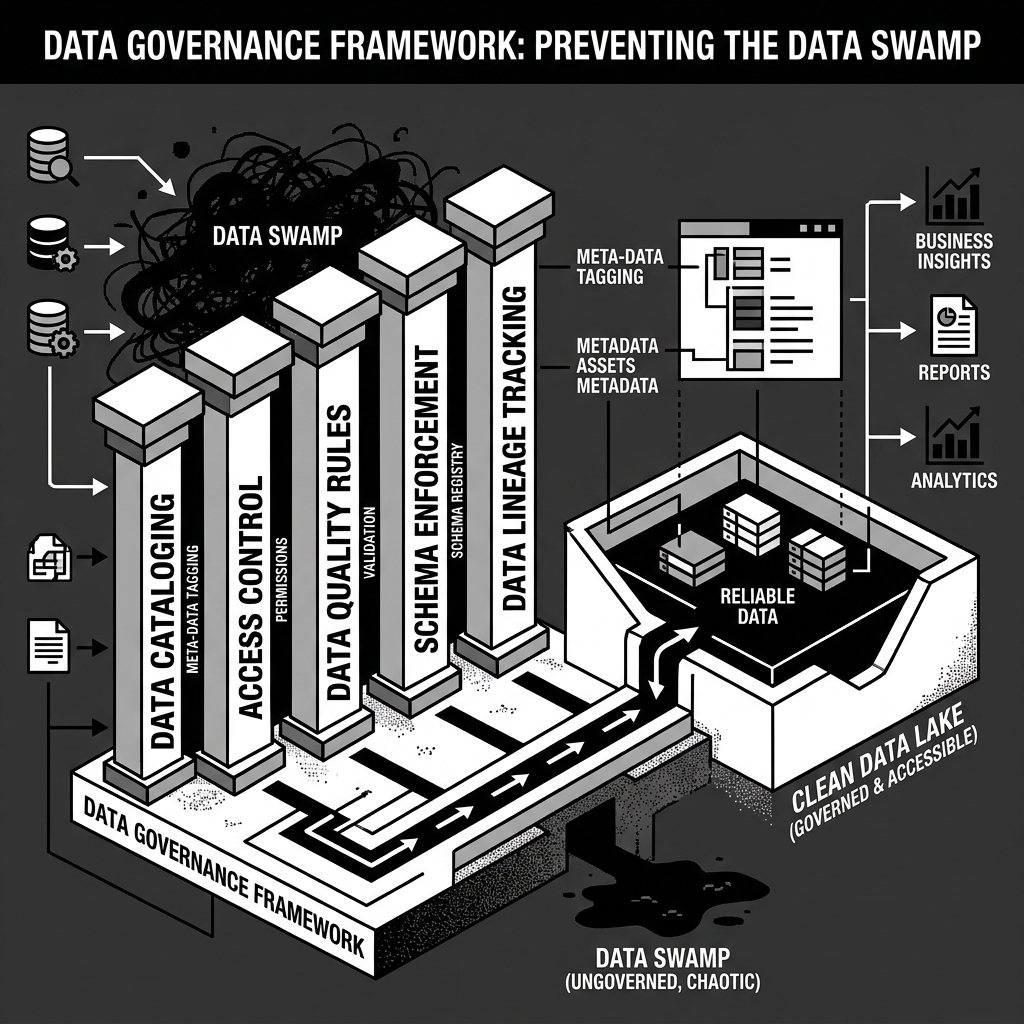
From Swamp to Lakehouse
Modern open table formats like Apache Iceberg address several of the technical root causes of data swamps by design. Iceberg tracks schemas at the individual file level, enabling schema evolution without breaking downstream readers. Its snapshot-based architecture maintains a complete history of every change to the table, providing built-in data lineage. Its ACID transaction guarantees prevent partial writes from corrupting the lake.
However, even Apache Iceberg cannot fix the organizational failures that lead to data swamps. A well-implemented Iceberg table with no catalog registration, no owner, and no quality checks is still a potential swamp. The path from data swamp to a well-functioning data lakehouse requires the combination of technical table format governance with organizational data ownership models, active metadata management, and enforced data quality standards at every layer of the ingestion pipeline.