Data Warehouse
Data Warehouse
A data warehouse is a centralized repository engineered specifically to store highly structured, historical data. Its primary purpose is to support business intelligence activities, generating reliable reports, and enabling complex analytical queries across an entire enterprise. Unlike operational databases that are optimized for rapid, high-volume transactional processing, data warehouses are optimized for reading massive volumes of data to uncover historical trends and business metrics.
The concept of the data warehouse originated in the 1980s as companies realized their operational databases could not handle the heavy load of analytical queries. Running a complex aggregation across millions of rows on a database that was simultaneously trying to process live customer orders would cause the entire system to crash. The solution was to copy the data into a separate, dedicated system built explicitly for analytics.
Core Architectural Principles
The fundamental principle governing a data warehouse is Schema-on-Write. This means that before any data can be inserted into the warehouse, the structure of that data must be explicitly defined. The engineering team must create strict tables with predefined columns, data types, and relationships. If a new piece of data arrives that does not match the predefined schema, the system will reject it.
This strict adherence to schema ensures data quality and consistency. When a business analyst runs a query against a data warehouse, they can trust that the data has already been cleaned, validated, and conformed to the company’s business rules. This high level of trust is why data warehouses remain the gold standard for financial reporting and regulatory compliance.
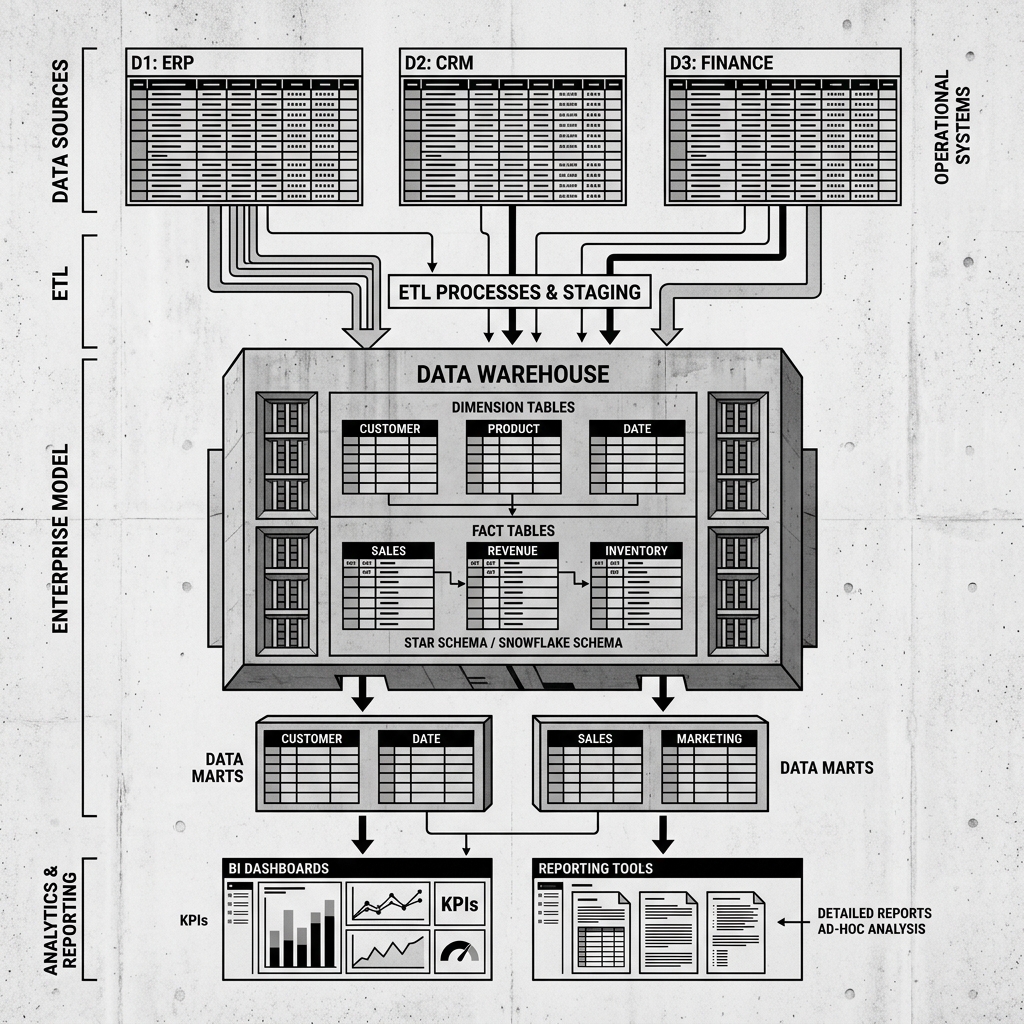
Data within a warehouse is typically modeled using dimensional modeling techniques. The most common approach is the Star Schema, which separates data into two distinct types of tables: Fact tables and Dimension tables. Fact tables contain the measurable, quantitative data about a business event, such as the total revenue of a sale or the quantity of items purchased. Dimension tables contain the descriptive attributes related to those facts, such as the customer’s name, the store location, or the product category. This separation makes it incredibly efficient for SQL engines to join tables and aggregate data rapidly.
Diagram 1: Conceptual Architecture
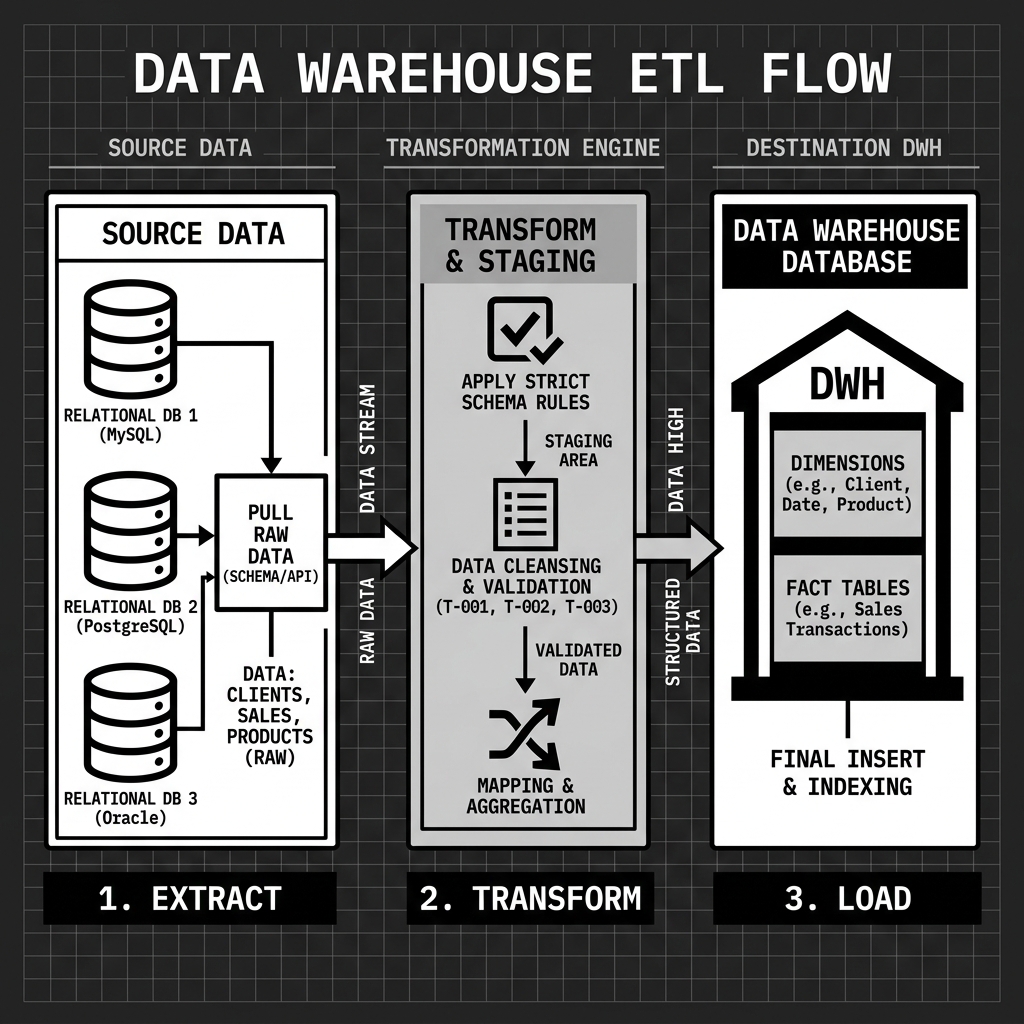
The ETL Pipeline
Populating a data warehouse is a rigorous, highly orchestrated process known as Extract, Transform, Load (ETL). Because the warehouse enforces a strict schema, the data must be heavily processed before it can be stored.
The Extract phase involves connecting to various source systems across the enterprise. These sources might include relational databases like PostgreSQL, Customer Relationship Management (CRM) tools like Salesforce, or Enterprise Resource Planning (ERP) systems. The raw data is extracted from these systems and moved into a temporary staging area.
The Transform phase is the most complex and resource-intensive step. In the staging area, the raw data is subjected to a series of business rules. Dates are standardized into a single format. Null values are handled. Duplicate records are merged or discarded. Data from different systems is joined together to create a single, unified view of a business entity. For example, a customer’s billing address from the ERP system might be merged with their email address from the CRM system.
Finally, the Load phase inserts the cleaned, transformed data into the highly structured tables of the data warehouse. Because this process is so computationally expensive, it is traditionally run in batches during off-peak hours, such as overnight. This batch-oriented approach means that data in a traditional warehouse is rarely real-time; it is usually at least 24 hours old.
Diagram 2: Operational Flow
Modern Data Warehouses and Tradeoffs
The architecture of data warehouses has evolved significantly with the advent of cloud computing. Modern cloud data warehouses, such as Snowflake, Google BigQuery, and Amazon Redshift, offer massive improvements over traditional on-premises systems. They provide elastic scalability, allowing organizations to separate compute resources from storage resources. This elasticity means a company can spin up a massive compute cluster to run a heavy end-of-month financial report and then scale it back down to save costs.
Despite these advancements, the inherent limitations of the data warehouse architecture remain. The rigid Schema-on-Write requirement makes them inflexible. Adding a new data source or changing an existing schema requires significant engineering effort and can take weeks or months to implement. Furthermore, data warehouses are fundamentally designed for structured, relational data. They struggle to efficiently store and process unstructured data like text documents, images, or raw server logs.
These limitations ultimately drove the industry to adopt Data Lakes for raw storage and Data Lakehouses for unified analytics. However, for organizations that require absolute data integrity, strict governance, and blazing-fast performance for structured SQL queries, the data warehouse remains an indispensable component of the data architecture.