Databricks
Databricks is a unified data analytics platform and the company originally founded by the creators of Apache Spark. More than just a managed Spark provider, Databricks is the organization that coined and popularized the term “Data Lakehouse.” By developing open-source technologies like Delta Lake and MLflow, and integrating them into a massive, fully managed cloud platform, Databricks has established itself as the premier ecosystem for large-scale data engineering, data science, and artificial intelligence.
Core Definition
The origins of Databricks are deeply intertwined with the limitations of early data lakes. In the mid-2010s, organizations were dumping massive amounts of raw data into Amazon S3 or Hadoop clusters. While Apache Spark provided the computational power to process this data, managing the underlying files was a nightmare. Data lakes suffered from corrupted data during failed writes, no ability to perform ACID transactions, and excruciatingly slow performance when dealing with millions of small files.
To solve this, the founders of Databricks developed Delta Lake—an open-source storage layer that brings reliability to data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing.
Databricks the platform is the commercialization of this ecosystem. It is a cloud-based environment (available on AWS, Azure, and GCP) that provides a fully managed, optimized version of Apache Spark, tightly integrated with Delta Lake. The platform abstracts away the immense complexity of deploying, securing, and scaling distributed computing clusters. It provides a collaborative workspace where data engineers can write Scala or Python pipelines, data analysts can write SQL queries, and data scientists can train machine learning models—all on the exact same underlying data.
This unified approach is the defining characteristic of the Databricks Lakehouse. It eliminates the need to maintain a separate, expensive data warehouse for business intelligence and a messy data lake for machine learning. Instead, all data lives in cheap object storage, and Databricks provides the diverse compute engines required to serve all workloads.
Architecture and Components
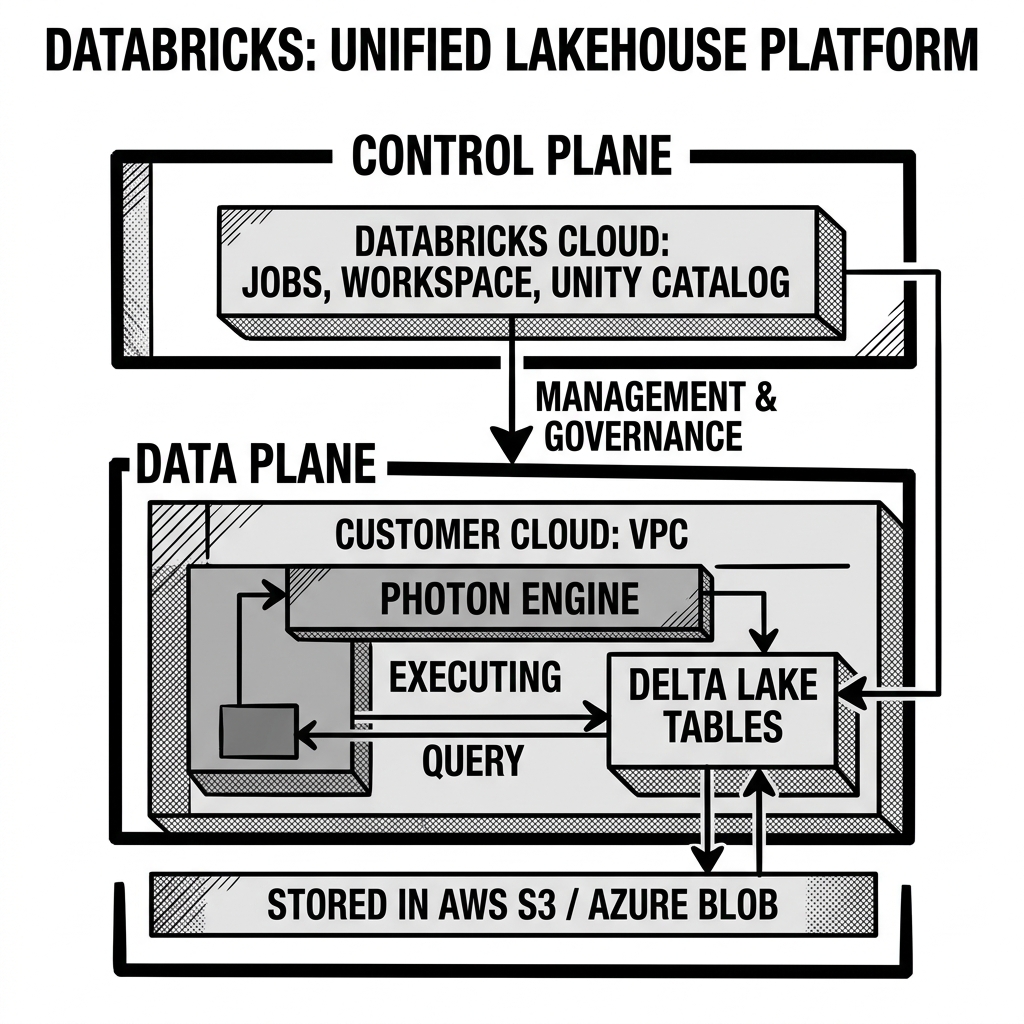
The architecture of the Databricks platform is divided into two primary components: the Control Plane and the Data Plane.
The Control Plane is managed entirely by Databricks. It resides in the Databricks cloud account and handles all the management and orchestration tasks. This includes user authentication, workspace UI, cluster management, job scheduling, and the execution of serverless compute services.
The Data Plane resides within the customer’s own cloud account (e.g., the customer’s AWS VPC). This is where the actual data processing happens. When a user in the Control Plane requests a compute cluster, Databricks spins up the necessary Virtual Machines (like EC2 instances) directly inside the customer’s Data Plane. These instances process the data residing in the customer’s object storage. This architecture ensures that raw data never leaves the customer’s cloud environment, maintaining strict security and compliance.
At the core of the Databricks compute engine is Photon. Photon is a highly optimized, native vectorized query engine written in C++. It was built specifically to accelerate SQL workloads on the lakehouse. When a user executes a SQL query or DataFrame operation, Databricks automatically routes the execution to Photon (when compatible) rather than the standard Java-based Spark engine. Photon provides massive performance improvements, allowing Databricks to compete directly with traditional data warehouses in raw query speed.
The Lakehouse Platform Ecosystem
Databricks has evolved far beyond a simple execution engine. It provides a comprehensive suite of tools designed to govern and manage the entire data lifecycle.
The cornerstone of their governance strategy is the Unity Catalog. Unity Catalog provides centralized access control, auditing, and data lineage for all data and AI assets across the entire Databricks ecosystem. Instead of managing permissions at the file or folder level on S3, administrators use standard SQL grants in Unity Catalog to secure tables, rows, and columns. Unity Catalog also provides seamless integration with Delta Sharing, an open protocol for securely sharing live data across organizations without requiring the recipient to be on the Databricks platform.
For data engineering, Databricks provides Delta Live Tables (DLT). DLT is a declarative framework for building reliable data pipelines. Instead of writing complex imperative Spark code to manage dependencies and retries, engineers simply define the transformations in SQL or Python. DLT automatically manages the infrastructure, infers dependencies, handles data quality checks (expectations), and ensures data flows correctly from Bronze to Silver to Gold layers in the Medallion Architecture.
For data science and AI, Databricks integrates MLflow, an open-source platform for managing the machine learning lifecycle. It allows data scientists to track experiments, package code into reproducible runs, and share and deploy models. Recently, Databricks has heavily expanded its AI capabilities, offering MosaicML for training custom Large Language Models (LLMs) securely on corporate data, and specialized vector databases to power Retrieval-Augmented Generation (RAG) architectures natively within the lakehouse.
Openness and Interoperability
Databricks heavily emphasizes its commitment to open source. The foundation of their platform—Apache Spark, Delta Lake, and MLflow—are all open-source projects hosted by the Linux Foundation or Apache Software Foundation.
This openness provides organizations with a significant degree of vendor neutrality. Because data is stored in the open Delta Lake format on the customer’s own cloud storage, it is not locked into the Databricks ecosystem. If an organization decides to leave Databricks, they can immediately query their existing data files using Amazon Athena, Trino, or open-source Apache Spark without any data migration or conversion.
Furthermore, Databricks has actively participated in the convergence of open table formats. With the release of Delta UniForm (Universal Format), Databricks tables automatically generate metadata for Apache Iceberg and Apache Hudi alongside the Delta Lake transaction log. This allows an Iceberg-native engine (like Snowflake) to seamlessly query a table that was written by Databricks, breaking down silos across the entire modern data stack.
Summary and Tradeoffs
Databricks is the definitive pioneer of the Data Lakehouse. By combining the cheap, scalable storage of data lakes with the reliability and performance of data warehouses, they have created a unified platform capable of serving every data persona in an organization. The combination of optimized Spark, the Photon engine, Unity Catalog, and native AI tooling makes it one of the most powerful platforms available.
The primary tradeoff with Databricks is its inherent complexity. While Databricks abstracts away infrastructure management, understanding the underlying distributed computing concepts of Apache Spark is still crucial for optimizing complex pipelines and debugging performance bottlenecks.
Additionally, like Snowflake, cost management requires vigilance. Databricks charges based on Compute Units (DBUs) consumed. If massive clusters are left running idly, or if developers write highly inefficient, unoptimized Spark code that shuffles unnecessary data, cloud bills can escalate rapidly. However, for organizations dealing with massive scale, complex data engineering, and advanced machine learning workloads, the unified capabilities of the Databricks Lakehouse platform are generally considered well worth the investment.
Visual Architecture