Delta Lake
Delta Lake is one of the three dominant Open Table Formats that define the modern data lakehouse. Created at Databricks in 2017 and open-sourced under the Linux Foundation in 2019, Delta Lake was built from the ground up to solve the reliability and consistency problems that plagued Apache Spark users working against cloud object storage. While Apache Iceberg was born at Netflix with a focus on extreme metadata scalability, and Apache Hudi emerged from Uber’s need for real-time upserts, Delta Lake’s primary design goal was elegant simplicity: it needed to make an ordinary Apache Spark job against an S3 bucket behave exactly like a write operation against a reliable relational database.
Understanding Delta Lake requires a precise, technical grasp of its central innovation — the Transaction Log — and the full suite of mechanisms it enables, including checkpointing, log compaction, optimistic concurrency control, Copy-on-Write DML, and the more recently introduced Deletion Vectors.
The Origin: Why Spark Needed Delta Lake
When Databricks began enabling enterprises to run massive Apache Spark workloads against Amazon S3, a fundamental problem emerged almost immediately. S3 is an object store, not a file system. It does not support file-level locking, partial file overwrites, or atomic multi-file transactions. A standard Spark job writing 500 Parquet files to S3 does so by uploading each file sequentially. If the Spark cluster is preempted or crashes after uploading 250 files, the remaining 250 files sit in a half-written state. There is no automatic rollback. The next query will read partial, corrupted data.
Furthermore, coordinating multiple simultaneous writers was essentially impossible. If two Spark clusters started writing to the same table at the same time, their files would interleave chaotically. There was no serialization mechanism. Files from Job A might conflict with files from Job B, producing logically nonsensical results.
Before Delta Lake, the practical solution was to write to a staging directory, complete the job, and then use a move or rename operation to swap the directories. However, S3 does not support atomic directory renames. A rename is internally a copy followed by a delete, which is itself not atomic and introduces the same failure modes.
Delta Lake solved all of these problems by introducing a single, authoritative metadata structure: the Transaction Log.
The Transaction Log: The Absolute Source of Truth
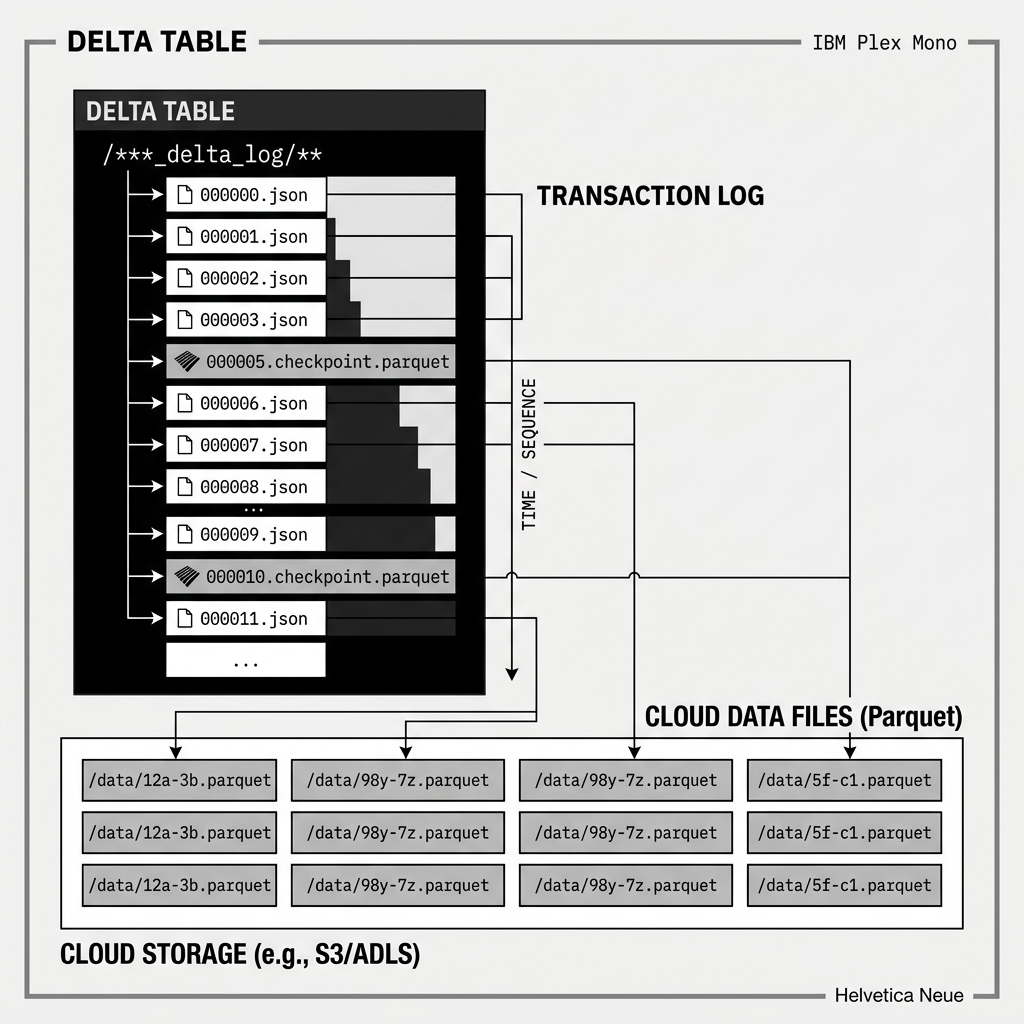
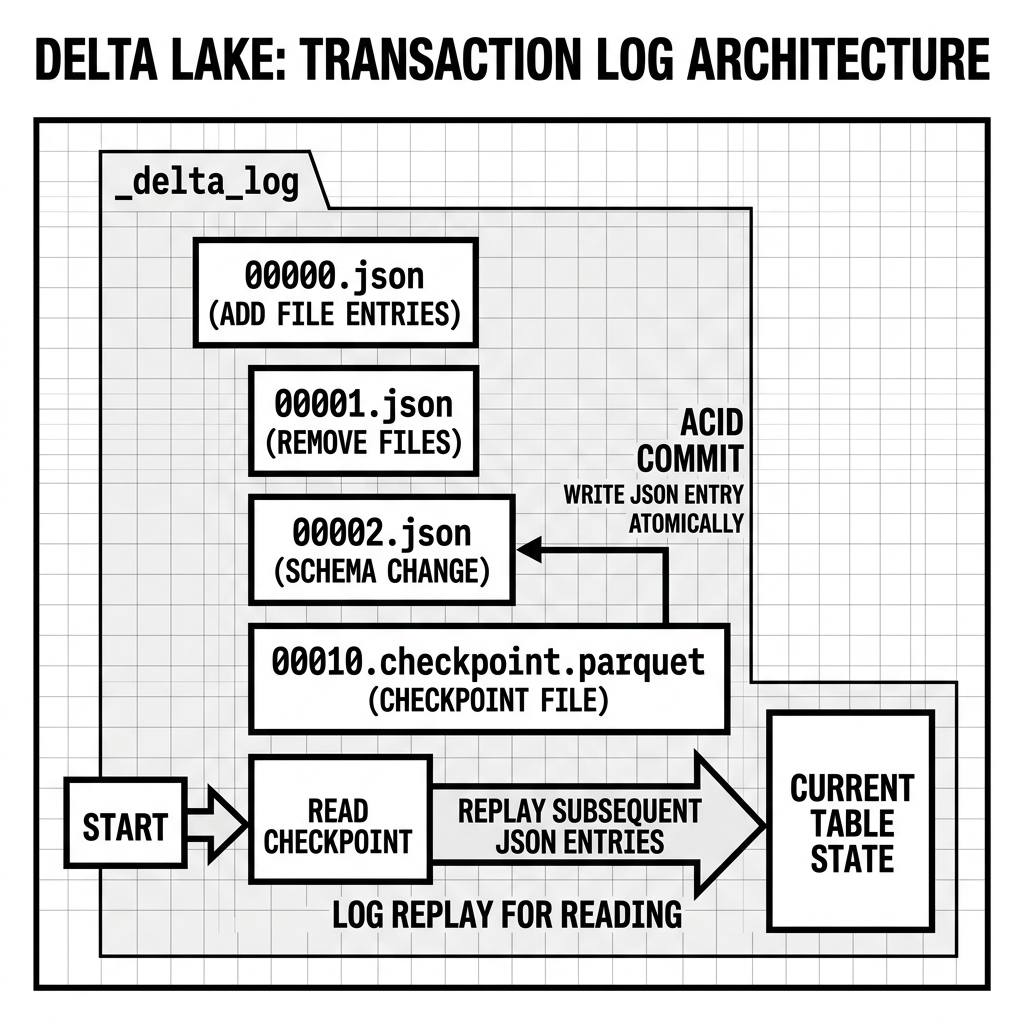
The Transaction Log, stored in a directory named _delta_log at the root of every Delta table, is the core of the entire architecture. It is a strictly ordered, append-only sequence of JSON files. Each JSON file, named sequentially (e.g., 00000000000000000000.json, 00000000000000000001.json), represents exactly one atomic commit.
The Structure of a Commit File
Each JSON commit file is a compact document that records a precise set of actions performed during that transaction. The key action types are:
add: This action records the addition of a new Parquet data file to the table. The entry includes the file’s path, its size in bytes, the number of rows it contains, partition values, and critical column-level statistics such as minimum values, maximum values, and null counts for each column. These statistics are the foundation of data skipping during query planning.
remove: This action records the logical removal of a Parquet file from the table. The file is not immediately physically deleted from object storage — it is simply marked as no longer part of the table’s active state as of this commit version. Physical deletion is handled later by the VACUUM command.
metaData: This action records changes to the table’s schema, partitioning configuration, or table properties. When a column is added or the partition scheme is changed, the new schema is written directly into the commit JSON.
protocol: This action records changes to the Delta Lake protocol version, indicating which reader and writer features are required to correctly interact with this table. This is the mechanism that controls feature rollouts (like Deletion Vectors) in a backward-compatible way.
commitInfo: This action provides metadata about the commit itself — which engine performed the write (Spark, Trino, Flink, etc.), what operation type it was (WRITE, UPDATE, DELETE, MERGE), and a timestamp.
When a query engine needs to read the current state of a Delta table, it reads the _delta_log directory, reconstructs the full list of active files by replaying all add and remove actions in strict chronological order, and then filters that list based on any partition pruning predicates in the user’s query. Because the column-level statistics (min/max/null counts) are embedded directly into the add action JSON, the engine can also perform fine-grained data skipping without ever opening a single Parquet file, eliminating irrelevant files purely at the metadata level.
Checkpointing: Managing Log Performance at Scale
If a high-throughput Delta table receives thousands of commits per day, the _delta_log directory will quickly accumulate thousands of JSON files. Replaying all of them to reconstruct the current table state for every query would result in unacceptably slow query planning times.
Delta Lake solves this with Checkpointing. By default, every 10 commits, Delta automatically creates a Parquet checkpoint file. Unlike the incremental JSON commit files, a checkpoint file is a complete, self-contained snapshot of the table’s entire active state at that specific version. It contains the full list of all active add entries, including all their statistics, at the point of the checkpoint.
When a query engine needs to read the table, it first locates the most recent checkpoint file and reads it to get the bulk of the table’s state. It then only needs to replay the small number of JSON commit files that were created after that checkpoint. This dramatically bounds the amount of log-replay work required, regardless of how old or how active the table is.
Log Compaction
Delta Lake 3.0 introduced a further optimization called Log Compaction. In extremely write-intensive scenarios, even the 10-commit checkpointing frequency is insufficient — a cluster processing thousands of micro-batches per hour might generate so many JSON files that checkpoint creation itself becomes a bottleneck. Log compaction files (with the naming convention x.y.compact.json) aggregate multiple JSON commit records into a single, larger file, reducing I/O overhead during log replay without requiring a full Parquet checkpoint. This provides a flexible, middle-ground option between individual JSON commits and heavyweight full checkpoints.
Optimistic Concurrency Control in Delta Lake
Delta Lake implements Optimistic Concurrency Control (OCC) to safely coordinate multiple concurrent writers against the same table.
When a Spark job begins a write operation, it reads the current state of the _delta_log to identify the highest committed version (e.g., version 120). It performs all its computation and writes its output Parquet files to object storage. Then, when ready to commit, it attempts to write a new JSON file at version 121.
The critical safety mechanism is a conditional write on the JSON file name. The writer only succeeds if no other commit has already claimed version 121. Because S3, GCS, and Azure Blob Storage all support atomic “put if absent” semantics, this write is inherently race-free. Only one writer can successfully create 00000000000000000121.json.
If a second concurrent writer also tried to commit version 121, its conditional write fails. Delta Lake then triggers a conflict resolution process. The rejected writer re-reads the log from version 121 onwards to see what changed and determines if the concurrent write conflicts logically with its own changes. If the two write operations targeted completely different partitions or files — a very common scenario in distributed pipelines — Delta can determine there is no logical conflict and automatically retry the commit at the next available version. If the operations genuinely conflict (e.g., both updated the same rows), Delta raises a ConcurrentModificationException, requiring the application logic to handle the retry or resolution.
DML Operations: UPDATE, DELETE, and MERGE
Delta Lake inherits the immutability of Parquet files. To execute DML operations (UPDATE, DELETE, MERGE) without the ability to overwrite bytes in-place, Delta Lake historically relied exclusively on the Copy-on-Write strategy.
Copy-on-Write DML
When a DELETE FROM orders WHERE status = 'cancelled' is executed, Delta Lake uses the column statistics in the _delta_log to identify only the Parquet files that might contain rows where status = 'cancelled'. For each identified file, it reads the entire Parquet file into Spark’s memory, applies the filter retaining all rows where status != 'cancelled', writes a new Parquet file containing only the retained rows, and records a remove action for the old file and an add action for the new file in a new commit JSON.
The MERGE INTO operation is significantly more complex. It joins the target Delta table against a source DataFrame, applies conditional logic (WHEN MATCHED THEN UPDATE, WHEN NOT MATCHED THEN INSERT), and must identify all matching files, rewrite them with updates applied, and insert any new rows for unmatched records. Delta Lake’s statistics-driven file pruning is essential here to avoid scanning the entire table to find matching rows.
Deletion Vectors: The MoR Revolution
The fundamental limitation of Copy-on-Write DML is write amplification. Rewriting an entire 512MB Parquet file to delete a handful of rows is computationally expensive. For tables with extremely high update or delete frequencies, the CoW cost can dominate the compute budget.
Starting with Delta Lake 2.3, the project introduced Deletion Vectors, which implement a Merge-on-Read approach without modifying existing data files. A Deletion Vector is a compact binary file implementing a Roaring Bitmap data structure that records the row indices within a specific Parquet data file that should be considered deleted or outdated.
When a DELETE command is executed with Deletion Vectors enabled, Delta Lake does not rewrite the Parquet file at all. Instead, it identifies the relevant files using column statistics, identifies the exact row indices within those files that match the delete predicate, writes a tiny Deletion Vector file (often just a few kilobytes) encoding those row indices as a compressed bitmap, and records the Deletion Vector file path alongside the add action for the original data file in the new commit JSON.
At read time, the query engine reads both the data file and the associated Deletion Vector. It applies the bitmap as a row-level filter, completely skipping any row whose index appears in the Deletion Vector. Deletion Vectors dramatically reduce write amplification for delete-heavy workloads, making Delta Lake significantly more competitive with Apache Hudi’s Merge-on-Read capabilities for streaming CDC pipelines.
The OPTIMIZE and VACUUM Maintenance Operations
Like all lakehouse table formats, Delta Lake requires periodic maintenance to sustain long-term performance.
OPTIMIZE
The OPTIMIZE command compacts small Parquet files into larger, optimally-sized files. In streaming environments where micro-batches write small files every few seconds, this is critical. OPTIMIZE reads multiple small files, merges them in memory, and writes new larger files (typically targeting 128MB to 256MB). The old small files are recorded as remove actions in the new commit.
OPTIMIZE also supports the ZORDER BY clause. Z-Ordering rewrites and physically co-locates rows within the Parquet files based on one or more specified columns. By clustering rows with similar values of the query predicate column together within the same file, min/max statistics become much tighter. This allows the Delta engine’s data skipping to eliminate far more files, drastically reducing the amount of data that needs to be read during query execution.
VACUUM
The VACUUM command is Delta Lake’s garbage collector. It physically deletes from object storage the Parquet files that have been recorded as remove actions in the transaction log and are older than the retention threshold (default: 7 days). Without VACUUM, the raw storage on S3 or GCS would grow unboundedly, even though the logical table remains stable. The retention window ensures that any in-progress time-travel queries or concurrent read jobs that started before the last VACUUM have enough time to complete before their underlying files are physically deleted.
Schema Enforcement and Evolution
Delta Lake enforces strict schema-on-write by default. If a Spark job attempts to append a DataFrame with a column of an incompatible type (e.g., writing a STRING column to a table that expects an INTEGER), the write is rejected with a clear schema mismatch error. This prevents silent data corruption caused by upstream schema changes in ETL pipelines.
For intentional schema changes (adding a new column, widening an existing column’s data type), Delta Lake supports MERGE SCHEMA options that allow the schema to be safely evolved. Each schema change is recorded as a metaData action in a new transaction log entry, ensuring the complete history of the schema’s evolution is preserved and auditable.
Time Travel and Data Versioning
Every commit in the Delta transaction log is permanently versioned. Delta Lake provides two syntaxes for Time Travel:
Version-based: SELECT * FROM orders VERSION AS OF 150 reads the table exactly as it existed at commit version 150.
Timestamp-based: SELECT * FROM orders TIMESTAMP AS OF '2026-05-01' reads the table as it existed at the closest committed version before that timestamp, using the commitInfo timestamps stored in each JSON commit file.
The historical data files referenced by old versions remain physically present on object storage until the VACUUM command removes them. Time Travel is therefore bounded by the VACUUM retention window.
Delta UniForm: Delta as an Iceberg-Compatible Format
One of the most significant recent developments in Delta Lake is Delta UniForm (Universal Format), introduced in Delta Lake 3.0. UniForm directly addresses the interoperability gap between the major Open Table Formats.
When UniForm is enabled on a Delta table, every time a Delta commit is made, Iceberg metadata (Manifest Lists, Manifest Files, and a metadata JSON file) is automatically generated and written to the object storage, pointing to the exact same underlying Parquet data files. The Parquet files are not duplicated — only the metadata layer is generated in both formats.
This allows engines that have native Iceberg support (like Trino, Flink, or Snowflake’s Iceberg reader) to query the exact same Delta table without any data copying or conversion. Delta becomes the write format of record, and Iceberg compatibility is provided transparently as an automatically-maintained side-effect. This is a decisive strategic move: Delta Lake no longer requires that every downstream query engine have a Delta reader; it can now interoperate with the broad Iceberg ecosystem natively.
The Ecosystem Position of Delta Lake
Delta Lake’s greatest competitive advantage is its depth of integration with the Apache Spark and Databricks ecosystem. Databricks Runtime includes Delta Lake as a first-class feature with proprietary performance optimizations, including Photon-accelerated DML operations and predictive I/O. For organizations fully invested in Databricks as their primary compute platform, Delta Lake provides the tightest, most optimized, and most fully-featured experience available in any Open Table Format.
However, its historical tight coupling to Spark made it less attractive for organizations seeking a format that could serve as a neutral foundation for a multi-engine ecosystem. While connectors for Trino, Presto, Flink, and others exist and are continually improving, the breadth and depth of the Iceberg ecosystem’s engine support remains broader. The introduction of UniForm is Delta Lake’s direct response to this competitive weakness.
For organizations that primarily use Apache Spark, that run on Databricks, and that want the simplest possible reliable lakehouse architecture without the complexity of Iceberg’s hierarchical metadata tree, Delta Lake remains the most mature, battle-tested, and developer-friendly Open Table Format available.
Conclusion
Delta Lake’s log-structured architecture is a masterclass in applied distributed systems thinking. By reducing the complex problem of atomic transactions on object storage to the simple, reliable primitive of a sequentially-numbered, conditionally-written JSON append-only log, Databricks delivered a robust and widely-adopted solution to the reliability crisis of early cloud data lakes. Its layered evolution — from basic JSON commits, to Parquet checkpoints, to Deletion Vectors, to UniForm interoperability — demonstrates a clear engineering philosophy of solving the hardest problems incrementally, without breaking existing users. Understanding the Transaction Log is understanding Delta Lake: everything else is a consequence of that foundational architectural decision.
Visual Architecture