Delta UniForm
Delta UniForm — short for Universal Format — is a feature introduced in Delta Lake 3.0 that allows a Delta Lake table to be simultaneously readable as an Apache Iceberg table, without any data copying, format conversion, or secondary ETL pipeline. It is Delta Lake’s direct architectural response to the growing dominance of Apache Iceberg as the preferred read format for multi-engine lakehouse environments, and it represents one of the most strategically significant product decisions in the history of the Open Table Format ecosystem.
Understanding UniForm requires understanding both the competitive pressures that motivated its creation and the precise technical mechanisms through which it achieves cross-format metadata co-existence. The details matter: UniForm is not simply a wrapper or a compatibility shim. It is a carefully engineered asynchronous metadata generation system that maintains complete read-consistency for Iceberg consumers while preserving the full performance and reliability of Delta Lake’s primary write path.
The Strategic Problem UniForm Solves
By 2022, Apache Iceberg had emerged as the de facto standard read format for the broader lakehouse ecosystem. Trino, Presto, Flink, Snowflake, BigQuery, Athena, and Dremio all natively read Iceberg. Every major cloud vendor had added first-class Iceberg support. Iceberg’s hierarchical metadata tree, its rigorous specification, and its engine-agnostic design had made it the format of choice for organizations seeking to avoid vendor lock-in.
Delta Lake, despite being the most mature and widely deployed Open Table Format, faced a critical market positioning problem: data written by Databricks Spark jobs to Delta tables was largely stranded within the Databricks and Spark ecosystem. While Delta connectors existed for Trino, Presto, and Flink, they were often slower, less feature-complete, and less actively maintained than the native Iceberg connectors for the same engines. Organizations that were Databricks-primary for their write pipelines were finding it increasingly difficult to serve data to the growing number of Iceberg-native query engines being adopted across the enterprise.
The conventional solution would have been to migrate from Delta to Iceberg. However, migrating petabytes of existing Delta Lake tables to Iceberg involves either running expensive and time-consuming data conversion jobs, or using asynchronous metadata translation tools like Apache XTable, which inherently introduce data staleness.
Delta UniForm provided a third option: keep Delta Lake as the write format, but make every Delta commit automatically readable as Iceberg. No migration required. No data duplication. No separate tool to operate.
The Technical Architecture of UniForm
Enabling UniForm on a Delta Table
UniForm is enabled by setting a Delta table property:
ALTER TABLE my_table SET TBLPROPERTIES (
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
);Once enabled, UniForm becomes active for all subsequent commits to the table. The feature does not retroactively generate Iceberg metadata for historical Delta commits — it begins generating Iceberg metadata only from the point of enablement forward.
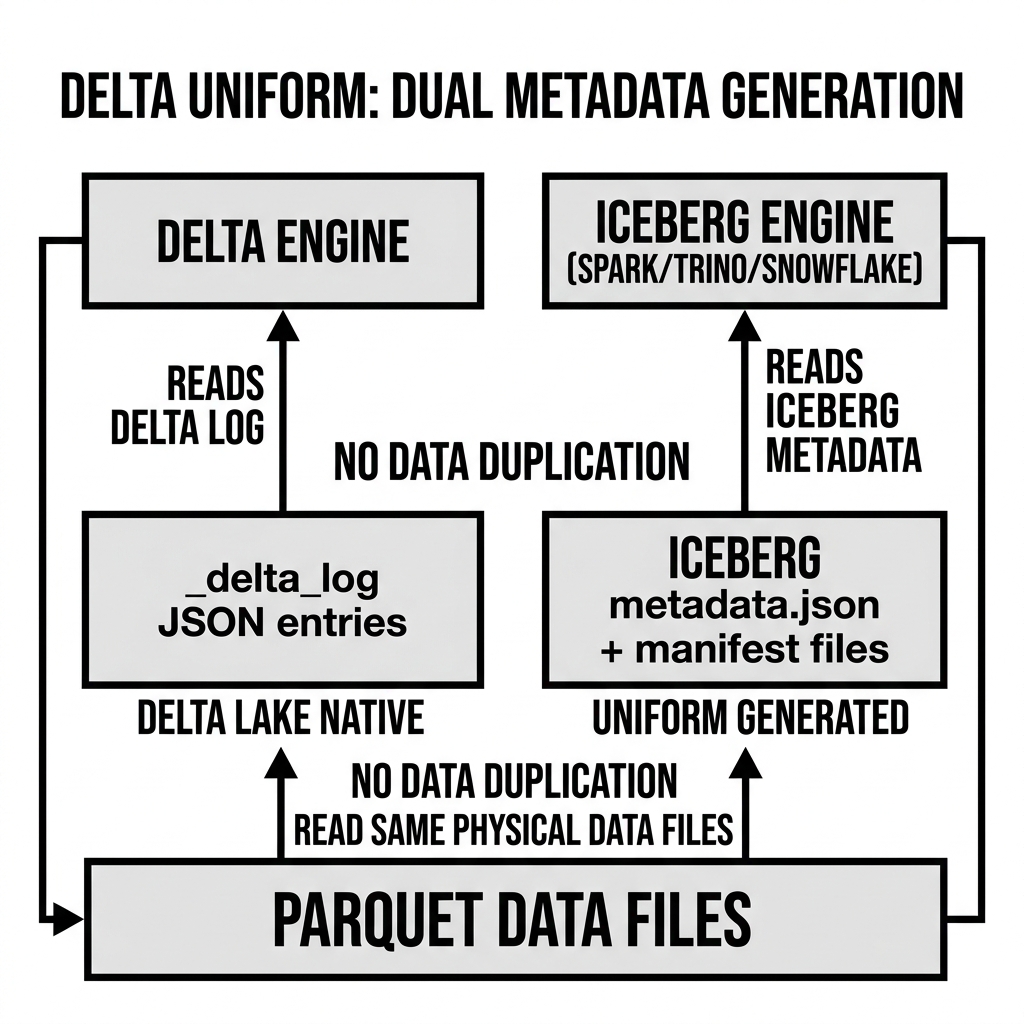
The Two-Phase Write Architecture
UniForm implements a fundamentally two-phase write process for every transaction:
Phase 1: The Primary Delta Transaction
Every write to a UniForm-enabled table is executed as a completely standard Delta Lake transaction. The write engine (a Databricks Spark cluster, a Delta Rust writer, etc.) writes Parquet data files to object storage, generates the corresponding JSON commit entry for the _delta_log/, and atomically commits the Delta transaction using Delta’s standard optimistic concurrency control mechanism.
This phase is entirely unchanged from a non-UniForm Delta write. There is no Iceberg-specific code in the hot write path, no additional latency incurred by Iceberg metadata generation, and no risk of a Delta commit failing due to an Iceberg-related error. The Delta write path remains pristine.
Phase 2: Asynchronous Iceberg Metadata Generation
Immediately after the Delta transaction commits successfully, UniForm triggers an asynchronous background process that generates the corresponding Iceberg metadata. This background process runs on the same compute resource that performed the original Delta write (e.g., the Databricks Spark driver).
The Iceberg metadata generation process reads the newly committed Delta entries from the _delta_log/, extracts the list of added and removed Parquet files, maps the Delta schema representation to its Iceberg equivalent, and writes new Iceberg metadata files — specifically, Iceberg Manifest Files, an Iceberg Manifest List, and a new metadata.json file — to a metadata/ directory within the table’s object storage path.
These Iceberg metadata files point to the same physical Parquet data files that the Delta commit just wrote. No data is read, transformed, or re-encoded. Only metadata is written.
Concurrency Control for the Background Process
A critical operational concern for UniForm is preventing the Iceberg metadata generation background process from competing with the next incoming Delta write transaction for compute resources. If the write pipeline is extremely high-frequency (e.g., a micro-batch streaming job committing every 5 seconds), and Iceberg metadata generation takes 3 seconds per commit, a naive implementation could spawn dozens of concurrent Iceberg generation processes, overwhelming the driver.
UniForm addresses this with an explicit concurrency limit: at most one Iceberg metadata generation process runs at any given time on a given compute resource. If a new Delta commit occurs while the previous Iceberg metadata generation is still running, the system does not start a second concurrent process. Instead, it defers the Iceberg metadata generation for the new commit until the previous one completes. When the deferred generation runs, it batches all Delta commits that occurred since the last Iceberg metadata update into a single Iceberg snapshot, preventing a backlog of individual generation tasks.
This batching behavior is an important characteristic: for very high-frequency commit workloads, a single Iceberg snapshot may correspond to multiple Delta Lake versions. Iceberg consumers will see the data from all those Delta commits appear atomically when the batched Iceberg snapshot is written, rather than seeing each Delta commit’s data appear incrementally.
The Iceberg Catalog Integration
For an Iceberg query engine (like Trino, Flink, or Snowflake’s Iceberg connector) to read a UniForm Delta table, it needs to locate the Iceberg metadata. This requires configuring an Iceberg Catalog to point to the table.
UniForm tables are most commonly registered in a Hive Metastore (HMS) or a Unity Catalog as an Iceberg table. The catalog entry points the Iceberg reader to the metadata/ directory within the Delta table’s object storage path. The Iceberg reader then loads the latest metadata.json in that directory — the most recent one generated by UniForm’s background process — and uses it to enumerate and read the underlying Parquet files.
This catalog configuration is a one-time setup operation. Once the Iceberg catalog entry is registered, every subsequent read by an Iceberg engine will automatically find the latest UniForm-generated Iceberg metadata without any further administrative action.
The Iceberg Schema Mapping
One of the more technically nuanced aspects of UniForm is the schema mapping between Delta Lake and Apache Iceberg. The two formats have largely compatible but not identical type systems. UniForm performs explicit type translation as part of the metadata generation process.
Key translations include:
Data types: Delta Lake’s BYTE, SHORT, and INT types all map to Iceberg’s int type. Delta’s LONG maps to Iceberg’s long. Delta’s DECIMAL(precision, scale) maps directly to Iceberg’s decimal(precision, scale). Delta’s TIMESTAMP (which represents a timestamp without explicit timezone) maps to Iceberg’s timestamp with microsecond precision.
Complex types: Delta’s STRUCT, ARRAY, and MAP types have direct Iceberg equivalents. UniForm translates these faithfully, preserving the full nested structure of complex schemas.
Column IDs: Iceberg requires every column to have a unique, immutable column ID. Because Delta Lake does not natively track column IDs in the same way, UniForm assigns Iceberg column IDs based on the column’s position in the schema at the time UniForm is first enabled on the table. If columns are subsequently added via Schema Evolution, UniForm assigns new, unique Iceberg column IDs to the new columns. If columns are dropped or renamed, UniForm updates the Iceberg schema accordingly, preserving column ID assignments for unchanged columns.
This column ID management is essential for ensuring that the generated Iceberg metadata correctly maps Parquet column data to schema columns when the schema has evolved over time.
Read Consistency and Staleness Characteristics
Because Iceberg metadata generation is asynchronous, there is an inherent lag between when a Delta commit is made and when the corresponding Iceberg snapshot becomes available for Iceberg readers. This lag is typically very short — often just a few seconds on Databricks Runtime with adequate driver resources — but it is non-zero.
This staleness has concrete implications:
Iceberg readers see slightly older data: A Trino query executed immediately after a Delta write may read the Iceberg metadata from the previous snapshot, not the current one. The current Delta data will appear in the Iceberg view only after the background metadata generation completes.
Delta readers always see current data: Any query engine using the Delta Lake reader (including Databricks SQL, Spark, and Delta-native connectors) will always see the latest committed Delta state, with no delay.
Eventual consistency between formats: UniForm provides eventual consistency for Iceberg readers relative to Delta Lake’s committed state. For most analytical workloads (dashboards, BI reports, data science notebooks), this is entirely acceptable. For operational applications requiring strict read-after-write consistency for the Iceberg interface, this constraint must be explicitly acknowledged in the application design.
The Read-Only Iceberg Interface
A crucial operational rule for UniForm is that the Iceberg interface is strictly read-only. Iceberg-native engines can read the table through the Iceberg metadata, but they cannot write to it through the Iceberg interface. Writes must always go through the Delta Lake writer.
If a Trino job attempts to execute an INSERT INTO or CREATE TABLE AS SELECT against a UniForm table through the Iceberg catalog, the operation must be blocked or will result in corruption. The Trino Iceberg connector can insert an Iceberg snapshot pointing to new Parquet files, completely bypassing Delta’s transaction log. The next time the Delta writer commits, it will have no awareness of those Iceberg-written files, and subsequent Iceberg metadata generation by UniForm will overwrite the rogue Iceberg snapshot. The data written by the Trino job may become permanently inaccessible.
This read-write asymmetry is the most important governance constraint to communicate to all teams consuming a UniForm-enabled table.
UniForm vs. Apache XTable: Choosing the Right Tool
UniForm and Apache XTable both solve the cross-format interoperability problem, but they do so from fundamentally different positions:
| Dimension | Delta UniForm | Apache XTable |
|---|---|---|
| Source Format | Delta Lake only | Any format (Hudi, Iceberg, Delta) |
| Target Format | Iceberg only (Hive Metastore to follow) | Any format (bidirectional) |
| Sync Mechanism | Built into the Delta write path | External, separately-deployed process |
| Latency | Very low (seconds) | Configurable (minutes) |
| Write Engine Required | Databricks / Delta writers | Any engine that writes source format |
| Operational Overhead | Zero (transparent to writer) | Requires a dedicated sync process |
UniForm is the clear choice for Databricks-primary organizations that need to expose Delta tables to Iceberg-native engines with minimal operational overhead and very low staleness. XTable is the appropriate choice when the source format is Hudi or when full bidirectionality across all three major formats is required.
The Broader Industry Significance
Delta UniForm represents a significant concession by Databricks: the implicit acknowledgment that Iceberg has won the cross-format compatibility battle. By building Iceberg interoperability directly into Delta Lake’s write path, Databricks has signaled that an organization no longer needs to choose between Delta Lake’s write-path maturity and Iceberg’s read-path ubiquity. They can have both.
This move is strategically brilliant for Databricks: it eliminates the primary competitive objection to Delta Lake (“our query engines only support Iceberg”) while keeping customers within the Delta Lake write ecosystem. It also demonstrates that the Open Table Format ecosystem is maturing toward interoperability, rather than winner-take-all consolidation.
Conclusion
Delta UniForm is a precisely engineered solution to the single most consequential limitation of Delta Lake in a multi-engine lakehouse: its historical inability to serve as a native Iceberg table for non-Spark query engines. Its asynchronous two-phase architecture makes the Delta write path entirely pristine while generating eventually-consistent Iceberg metadata as a lightweight side effect. For Databricks users who have invested heavily in Delta Lake’s write infrastructure and now need to serve that data to Iceberg-native engines — Trino, Flink, Snowflake, Dremio, or Athena — UniForm provides the most operationally simple, lowest-latency, and lowest-cost path to cross-format compatibility available in the market.
Visual Architecture