Dictionary Encoding
Core Definition
Dictionary Encoding is a highly effective data compression technique predominantly used in columnar storage formats like Apache Parquet and Apache ORC. It is designed to significantly reduce the storage footprint of columns that contain a limited number of unique values (low cardinality data) by replacing long, repetitive data strings with small, compact integer references.
Consider a database table containing a hundred million rows of customer data, including a column for “State”. The words “California”, “New York”, and “Texas” might appear millions of times each. Storing the literal string “California” (which consumes 10 bytes) ten million times requires 100 megabytes of storage just for that single word.
Diagram 1: Conceptual Architecture
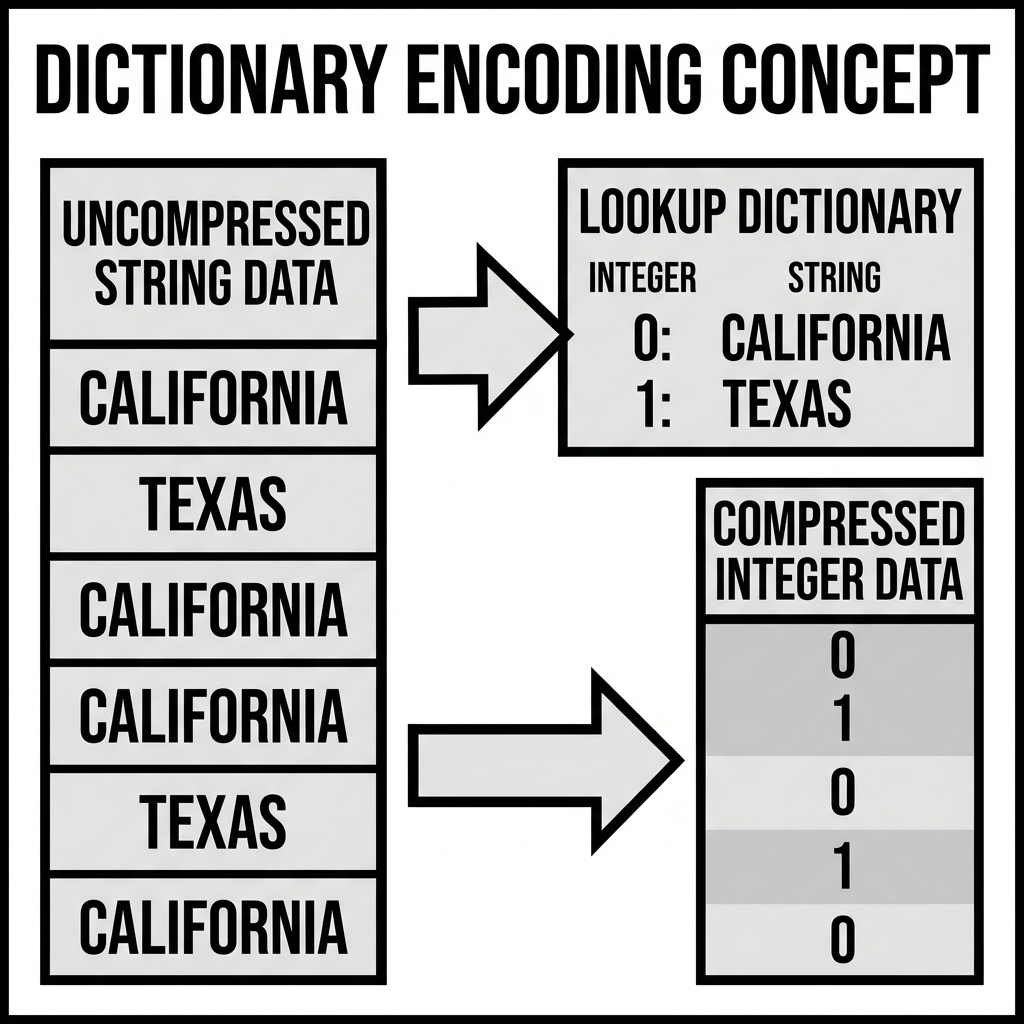
Implementation and Operations
Dictionary encoding solves this inefficiency by creating a lookup table (the “dictionary”) for the column block. The dictionary assigns a unique, small integer to each distinct value. For example:
- 0 = “California”
- 1 = “New York”
- 2 = “Texas”
Instead of writing the full string to the main data stream, the storage engine simply writes the corresponding integer (0, 1, or 2). Because these integers can be stored using just a few bits (e.g., a 2-bit integer can represent 4 unique states), the storage requirement drops astronomically.
The physical block of data now consists of two parts: the small Dictionary Page (containing the mapping) and the Data Page (containing millions of highly compressed integers).
This encoding not only saves massive amounts of disk space and network bandwidth, but it also accelerates query processing. Query engines like Trino can evaluate predicates directly on the dictionary. If the query is WHERE State = 'California', the engine checks the dictionary, finds that ‘California’ is 0, and then simply scans the highly compressed integer stream for 0 using rapid vectorized CPU instructions, rather than performing millions of slow string comparisons.
Diagram 2: Operational Flow
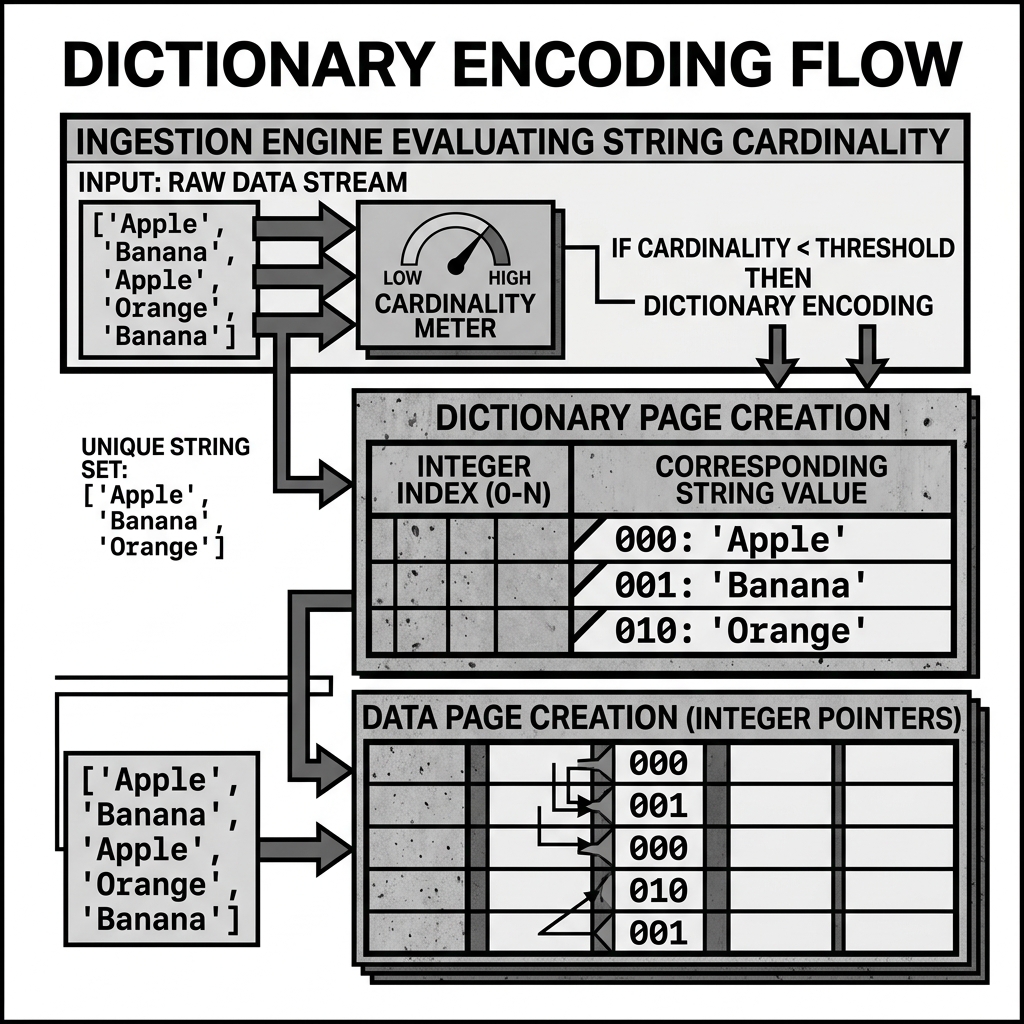
Summary and Tradeoffs
Dictionary encoding is the secret weapon of columnar formats, turning massive, repetitive datasets into tiny, fast-to-scan byte arrays. The primary tradeoff occurs when the cardinality (the number of unique values) of a column is very high (e.g., a column of unique User IDs). In such cases, the dictionary becomes so massive that it consumes more memory than it saves, and the encoding process slows down write performance. Modern formats like Parquet handle this by dynamically monitoring the dictionary size during ingestion and automatically falling back to plain encoding if the cardinality threshold is exceeded.
Extended Deep Dive: The Data Engineering Ecosystem
To truly understand this concept, it must be placed within the broader context of the modern data engineering ecosystem. The evolution from traditional, monolithic on-premises data warehouses to decoupled, cloud-native open data lakehouses represents one of the most significant paradigm shifts in software architecture over the last two decades.
The Problem with Legacy Data Warehouses
Historically, organizations relied on proprietary appliances from vendors like Teradata, Oracle, or IBM. These systems were characterized by a tight coupling of compute and storage. The data physically resided on the hard drives of the specific servers that executed the SQL queries. While incredibly fast for structured, relational data, this architecture suffered from fatal scalability flaws. If an organization needed more storage for historical logs, they were forced to purchase expensive, proprietary servers that included compute power they did not actually need. Furthermore, these systems struggled to ingest unstructured data (like raw JSON, images, or massive IoT streams), creating impenetrable data silos.
The Rise and Fall of the Data Lake (Hadoop)
To solve the volume and variety problem, the industry pivoted to the Data Lake, pioneered by Apache Hadoop. Organizations began dumping all raw data—structured, semi-structured, and unstructured—into the Hadoop Distributed File System (HDFS). Because HDFS ran on cheap commodity hardware, storage became essentially free. However, the data lake lacked the basic governance, transactional guarantees, and performance optimization of the data warehouse. Without ACID (Atomicity, Consistency, Isolation, Durability) transactions, concurrent reads and writes frequently corrupted data. Without schema enforcement, the data lake quickly devolved into an unmanageable, unqueryable “data swamp.”
The Open Data Lakehouse Paradigm
The open data lakehouse merges the best of both worlds. It utilizes the infinitely scalable, low-cost storage of the cloud (like Amazon S3 or Google Cloud Storage) but overlays the management and performance features of a traditional data warehouse.
This is achieved through a multi-layered architecture:
- The Storage Layer: Cloud object storage provides the infinite hard drive.
- The File Format Layer: Open columnar formats like Apache Parquet and ORC provide extreme compression and analytical read efficiency.
- The Table Format Layer: Technologies like Apache Iceberg, Delta Lake, and Apache Hudi sit on top of the physical files. They provide the metadata layer that enables ACID transactions, schema evolution, and time travel, bringing warehouse-level reliability to the raw object storage.
- The Compute Layer: Decoupled, highly elastic engines like Trino, Dremio, Apache Spark, and Snowflake sit at the top. They can be scaled up or down independently of the storage, providing massive parallel processing power only when queries are actively running.
Performance Optimization Strategies
In this decoupled architecture, network bandwidth between the compute engine and the object storage is the primary bottleneck. Data engineers employ a variety of advanced strategies to minimize this I/O:
- Partitioning: Organizing data into distinct directories based on a frequently queried column (e.g., separating data by
year/month/day). When an analyst queries a specific date, the engine simply ignores all directories that do not match, massively reducing data reads. - Z-Ordering and Space-Filling Curves: Advanced sorting techniques that cluster multi-dimensional data physically close together on the disk. This dramatically improves the effectiveness of file-skipping statistics (Min/Max filtering) in formats like Iceberg, allowing engines to read highly targeted, microscopic subsets of massive tables.
- Compaction: Over time, streaming ingestions create millions of tiny, inefficient files. Data engineers run scheduled compaction jobs (often utilizing bin-packing algorithms) to merge these tiny files into optimally sized, large columnar blocks (typically 128MB to 512MB), restoring query performance and reducing S3 API overhead.
Security and Governance
As data is democratized across the enterprise, governance becomes paramount. The open lakehouse relies on centralized metadata catalogs (like AWS Glue, Apache Polaris, or Unity Catalog) to manage access. Fine-Grained Access Control (FGAC) allows administrators to mask specific columns (like Social Security Numbers) or restrict specific rows based on the user’s role, ensuring that a single, unified dataset can be securely queried by marketing, finance, and engineering teams simultaneously without violating compliance regulations like GDPR or CCPA.
Conclusion
The architecture described above is not static. The industry is rapidly moving toward real-time streaming ingestion, automated “agentic” data modeling, and universal cross-engine compatibility via projects like Apache XTable. Understanding the foundational layers—how data is serialized, compressed, stored, and transported—is the absolute prerequisite for architecting systems that can handle the exabyte-scale analytics demands of the future.
Extended Deep Dive: The Data Engineering Ecosystem
To truly understand this concept, it must be placed within the broader context of the modern data engineering ecosystem. The evolution from traditional, monolithic on-premises data warehouses to decoupled, cloud-native open data lakehouses represents one of the most significant paradigm shifts in software architecture over the last two decades.
The Problem with Legacy Data Warehouses
Historically, organizations relied on proprietary appliances from vendors like Teradata, Oracle, or IBM. These systems were characterized by a tight coupling of compute and storage. The data physically resided on the hard drives of the specific servers that executed the SQL queries. While incredibly fast for structured, relational data, this architecture suffered from fatal scalability flaws. If an organization needed more storage for historical logs, they were forced to purchase expensive, proprietary servers that included compute power they did not actually need. Furthermore, these systems struggled to ingest unstructured data (like raw JSON, images, or massive IoT streams), creating impenetrable data silos.
The Rise and Fall of the Data Lake (Hadoop)
To solve the volume and variety problem, the industry pivoted to the Data Lake, pioneered by Apache Hadoop. Organizations began dumping all raw data—structured, semi-structured, and unstructured—into the Hadoop Distributed File System (HDFS). Because HDFS ran on cheap commodity hardware, storage became essentially free. However, the data lake lacked the basic governance, transactional guarantees, and performance optimization of the data warehouse. Without ACID (Atomicity, Consistency, Isolation, Durability) transactions, concurrent reads and writes frequently corrupted data. Without schema enforcement, the data lake quickly devolved into an unmanageable, unqueryable “data swamp.”
The Open Data Lakehouse Paradigm
The open data lakehouse merges the best of both worlds. It utilizes the infinitely scalable, low-cost storage of the cloud (like Amazon S3 or Google Cloud Storage) but overlays the management and performance features of a traditional data warehouse.
This is achieved through a multi-layered architecture:
- The Storage Layer: Cloud object storage provides the infinite hard drive.
- The File Format Layer: Open columnar formats like Apache Parquet and ORC provide extreme compression and analytical read efficiency.
- The Table Format Layer: Technologies like Apache Iceberg, Delta Lake, and Apache Hudi sit on top of the physical files. They provide the metadata layer that enables ACID transactions, schema evolution, and time travel, bringing warehouse-level reliability to the raw object storage.
- The Compute Layer: Decoupled, highly elastic engines like Trino, Dremio, Apache Spark, and Snowflake sit at the top. They can be scaled up or down independently of the storage, providing massive parallel processing power only when queries are actively running.
Performance Optimization Strategies
In this decoupled architecture, network bandwidth between the compute engine and the object storage is the primary bottleneck. Data engineers employ a variety of advanced strategies to minimize this I/O:
- Partitioning: Organizing data into distinct directories based on a frequently queried column (e.g., separating data by
year/month/day). When an analyst queries a specific date, the engine simply ignores all directories that do not match, massively reducing data reads. - Z-Ordering and Space-Filling Curves: Advanced sorting techniques that cluster multi-dimensional data physically close together on the disk. This dramatically improves the effectiveness of file-skipping statistics (Min/Max filtering) in formats like Iceberg, allowing engines to read highly targeted, microscopic subsets of massive tables.
- Compaction: Over time, streaming ingestions create millions of tiny, inefficient files. Data engineers run scheduled compaction jobs (often utilizing bin-packing algorithms) to merge these tiny files into optimally sized, large columnar blocks (typically 128MB to 512MB), restoring query performance and reducing S3 API overhead.
Security and Governance
As data is democratized across the enterprise, governance becomes paramount. The open lakehouse relies on centralized metadata catalogs (like AWS Glue, Apache Polaris, or Unity Catalog) to manage access. Fine-Grained Access Control (FGAC) allows administrators to mask specific columns (like Social Security Numbers) or restrict specific rows based on the user’s role, ensuring that a single, unified dataset can be securely queried by marketing, finance, and engineering teams simultaneously without violating compliance regulations like GDPR or CCPA.
Conclusion
The architecture described above is not static. The industry is rapidly moving toward real-time streaming ingestion, automated “agentic” data modeling, and universal cross-engine compatibility via projects like Apache XTable. Understanding the foundational layers—how data is serialized, compressed, stored, and transported—is the absolute prerequisite for architecting systems that can handle the exabyte-scale analytics demands of the future.
Extended Deep Dive: The Data Engineering Ecosystem
To truly understand this concept, it must be placed within the broader context of the modern data engineering ecosystem. The evolution from traditional, monolithic on-premises data warehouses to decoupled, cloud-native open data lakehouses represents one of the most significant paradigm shifts in software architecture over the last two decades.
The Problem with Legacy Data Warehouses
Historically, organizations relied on proprietary appliances from vendors like Teradata, Oracle, or IBM. These systems were characterized by a tight coupling of compute and storage. The data physically resided on the hard drives of the specific servers that executed the SQL queries. While incredibly fast for structured, relational data, this architecture suffered from fatal scalability flaws. If an organization needed more storage for historical logs, they were forced to purchase expensive, proprietary servers that included compute power they did not actually need. Furthermore, these systems struggled to ingest unstructured data (like raw JSON, images, or massive IoT streams), creating impenetrable data silos.
The Rise and Fall of the Data Lake (Hadoop)
To solve the volume and variety problem, the industry pivoted to the Data Lake, pioneered by Apache Hadoop. Organizations began dumping all raw data—structured, semi-structured, and unstructured—into the Hadoop Distributed File System (HDFS). Because HDFS ran on cheap commodity hardware, storage became essentially free. However, the data lake lacked the basic governance, transactional guarantees, and performance optimization of the data warehouse. Without ACID (Atomicity, Consistency, Isolation, Durability) transactions, concurrent reads and writes frequently corrupted data. Without schema enforcement, the data lake quickly devolved into an unmanageable, unqueryable “data swamp.”
The Open Data Lakehouse Paradigm
The open data lakehouse merges the best of both worlds. It utilizes the infinitely scalable, low-cost storage of the cloud (like Amazon S3 or Google Cloud Storage) but overlays the management and performance features of a traditional data warehouse.
This is achieved through a multi-layered architecture:
- The Storage Layer: Cloud object storage provides the infinite hard drive.
- The File Format Layer: Open columnar formats like Apache Parquet and ORC provide extreme compression and analytical read efficiency.
- The Table Format Layer: Technologies like Apache Iceberg, Delta Lake, and Apache Hudi sit on top of the physical files. They provide the metadata layer that enables ACID transactions, schema evolution, and time travel, bringing warehouse-level reliability to the raw object storage.
- The Compute Layer: Decoupled, highly elastic engines like Trino, Dremio, Apache Spark, and Snowflake sit at the top. They can be scaled up or down independently of the storage, providing massive parallel processing power only when queries are actively running.
Performance Optimization Strategies
In this decoupled architecture, network bandwidth between the compute engine and the object storage is the primary bottleneck. Data engineers employ a variety of advanced strategies to minimize this I/O:
- Partitioning: Organizing data into distinct directories based on a frequently queried column (e.g., separating data by
year/month/day). When an analyst queries a specific date, the engine simply ignores all directories that do not match, massively reducing data reads. - Z-Ordering and Space-Filling Curves: Advanced sorting techniques that cluster multi-dimensional data physically close together on the disk. This dramatically improves the effectiveness of file-skipping statistics (Min/Max filtering) in formats like Iceberg, allowing engines to read highly targeted, microscopic subsets of massive tables.
- Compaction: Over time, streaming ingestions create millions of tiny, inefficient files. Data engineers run scheduled compaction jobs (often utilizing bin-packing algorithms) to merge these tiny files into optimally sized, large columnar blocks (typically 128MB to 512MB), restoring query performance and reducing S3 API overhead.
Security and Governance
As data is democratized across the enterprise, governance becomes paramount. The open lakehouse relies on centralized metadata catalogs (like AWS Glue, Apache Polaris, or Unity Catalog) to manage access. Fine-Grained Access Control (FGAC) allows administrators to mask specific columns (like Social Security Numbers) or restrict specific rows based on the user’s role, ensuring that a single, unified dataset can be securely queried by marketing, finance, and engineering teams simultaneously without violating compliance regulations like GDPR or CCPA.
Conclusion
The architecture described above is not static. The industry is rapidly moving toward real-time streaming ingestion, automated “agentic” data modeling, and universal cross-engine compatibility via projects like Apache XTable. Understanding the foundational layers—how data is serialized, compressed, stored, and transported—is the absolute prerequisite for architecting systems that can handle the exabyte-scale analytics demands of the future.
Extended Deep Dive: The Data Engineering Ecosystem
To truly understand this concept, it must be placed within the broader context of the modern data engineering ecosystem. The evolution from traditional, monolithic on-premises data warehouses to decoupled, cloud-native open data lakehouses represents one of the most significant paradigm shifts in software architecture over the last two decades.
The Problem with Legacy Data Warehouses
Historically, organizations relied on proprietary appliances from vendors like Teradata, Oracle, or IBM. These systems were characterized by a tight coupling of compute and storage. The data physically resided on the hard drives of the specific servers that executed the SQL queries. While incredibly fast for structured, relational data, this architecture suffered from fatal scalability flaws. If an organization needed more storage for historical logs, they were forced to purchase expensive, proprietary servers that included compute power they did not actually need. Furthermore, these systems struggled to ingest unstructured data (like raw JSON, images, or massive IoT streams), creating impenetrable data silos.
The Rise and Fall of the Data Lake (Hadoop)
To solve the volume and variety problem, the industry pivoted to the Data Lake, pioneered by Apache Hadoop. Organizations began dumping all raw data—structured, semi-structured, and unstructured—into the Hadoop Distributed File System (HDFS). Because HDFS ran on cheap commodity hardware, storage became essentially free. However, the data lake lacked the basic governance, transactional guarantees, and performance optimization of the data warehouse. Without ACID (Atomicity, Consistency, Isolation, Durability) transactions, concurrent reads and writes frequently corrupted data. Without schema enforcement, the data lake quickly devolved into an unmanageable, unqueryable “data swamp.”
The Open Data Lakehouse Paradigm
The open data lakehouse merges the best of both worlds. It utilizes the infinitely scalable, low-cost storage of the cloud (like Amazon S3 or Google Cloud Storage) but overlays the management and performance features of a traditional data warehouse.
This is achieved through a multi-layered architecture:
- The Storage Layer: Cloud object storage provides the infinite hard drive.
- The File Format Layer: Open columnar formats like Apache Parquet and ORC provide extreme compression and analytical read efficiency.
- The Table Format Layer: Technologies like Apache Iceberg, Delta Lake, and Apache Hudi sit on top of the physical files. They provide the metadata layer that enables ACID transactions, schema evolution, and time travel, bringing warehouse-level reliability to the raw object storage.
- The Compute Layer: Decoupled, highly elastic engines like Trino, Dremio, Apache Spark, and Snowflake sit at the top. They can be scaled up or down independently of the storage, providing massive parallel processing power only when queries are actively running.
Performance Optimization Strategies
In this decoupled architecture, network bandwidth between the compute engine and the object storage is the primary bottleneck. Data engineers employ a variety of advanced strategies to minimize this I/O:
- Partitioning: Organizing data into distinct directories based on a frequently queried column (e.g., separating data by
year/month/day). When an analyst queries a specific date, the engine simply ignores all directories that do not match, massively reducing data reads. - Z-Ordering and Space-Filling Curves: Advanced sorting techniques that cluster multi-dimensional data physically close together on the disk. This dramatically improves the effectiveness of file-skipping statistics (Min/Max filtering) in formats like Iceberg, allowing engines to read highly targeted, microscopic subsets of massive tables.
- Compaction: Over time, streaming ingestions create millions of tiny, inefficient files. Data engineers run scheduled compaction jobs (often utilizing bin-packing algorithms) to merge these tiny files into optimally sized, large columnar blocks (typically 128MB to 512MB), restoring query performance and reducing S3 API overhead.
Security and Governance
As data is democratized across the enterprise, governance becomes paramount. The open lakehouse relies on centralized metadata catalogs (like AWS Glue, Apache Polaris, or Unity Catalog) to manage access. Fine-Grained Access Control (FGAC) allows administrators to mask specific columns (like Social Security Numbers) or restrict specific rows based on the user’s role, ensuring that a single, unified dataset can be securely queried by marketing, finance, and engineering teams simultaneously without violating compliance regulations like GDPR or CCPA.
Conclusion
The architecture described above is not static. The industry is rapidly moving toward real-time streaming ingestion, automated “agentic” data modeling, and universal cross-engine compatibility via projects like Apache XTable. Understanding the foundational layers—how data is serialized, compressed, stored, and transported—is the absolute prerequisite for architecting systems that can handle the exabyte-scale analytics demands of the future.
Visual Architecture