Distributed Compute
Distributed compute is a foundational paradigm in computer science where a massive computational task is divided into smaller, independent sub-tasks and executed simultaneously across multiple networked computers (often referred to as nodes). In the context of big data and the open data lakehouse, distributed compute is the mechanism that allows organizations to process petabytes of data in minutes—a feat that is physically impossible on any single monolithic server, regardless of its size.
Core Definition
Historically, databases were designed to run on a single machine (scale-up architecture). If a database became too slow, the solution was to buy a larger, more expensive server with more CPU cores and RAM. Eventually, data volumes outpaced the physical limitations of single machines.
Distributed compute introduced a scale-out architecture. Instead of buying one massive supercomputer, organizations could link together hundreds or thousands of cheap, commodity servers. A distributed compute engine coordinates these servers to act as a single logical entity.
The core principle behind distributed compute in data processing is data locality and parallelization. Instead of bringing all the data to one processor, the engine partitions the data into thousands of chunks and sends the processing instructions (the code) to the nodes where the data resides. Each node processes its assigned chunk of data simultaneously. The results are then aggregated and returned to the user. This is the underlying philosophy behind frameworks like Apache Hadoop, Apache Spark, and Trino.
Master-Worker Topology
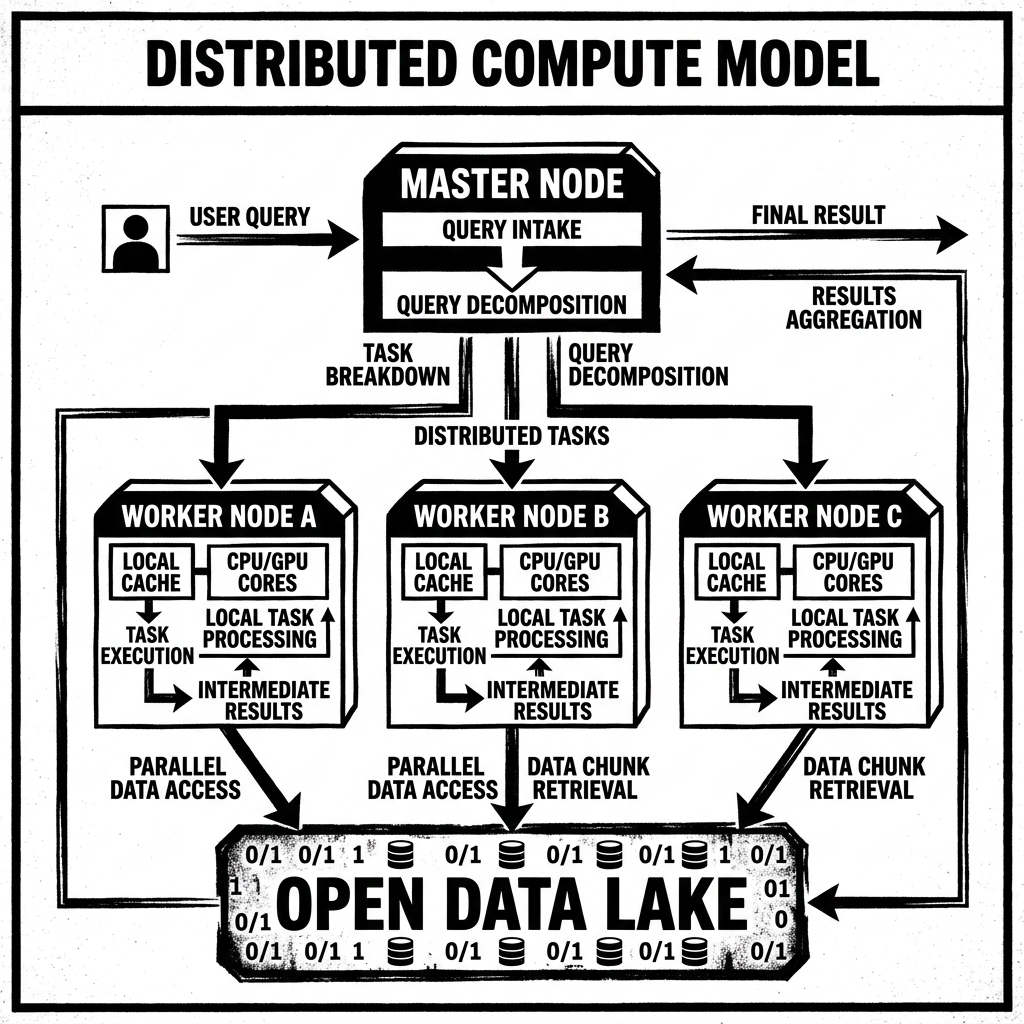
Most distributed compute engines utilized in the data lakehouse rely on a Master-Worker topology (sometimes called a Coordinator-Worker or Driver-Executor topology).
The Master Node acts as the brain of the cluster. It does not process the raw data itself. When a user submits a SQL query or a Python script, the Master Node parses the request, optimizes the execution plan, and breaks the query down into a Directed Acyclic Graph (DAG) of discrete tasks. It is responsible for monitoring the cluster, knowing which Worker Nodes are available, assigning tasks to them, and tracking their progress.
The Worker Nodes (or Executors) are the muscle of the cluster. They receive instructions from the Master Node. They read their assigned partitions of data from the storage layer (e.g., S3 or HDFS), execute the required computations (filtering, mapping, aggregations) in memory or on disk, and return the final results or status to the Master Node.
By adding more Worker Nodes to the cluster, the system can partition the data into smaller chunks, process them faster, and drastically reduce the overall execution time of the query.
Shuffling and Data Exchange
While parallel execution is simple when tasks are completely independent (e.g., filtering a log file), it becomes incredibly complex when data needs to be aggregated across the entire dataset (e.g., a massive GROUP BY operation or joining two billion-row tables). This requires a process called Shuffling.
A shuffle occurs when data needs to be redistributed across the Worker Nodes based on a specific key. For example, to calculate total sales by city, all records belonging to ‘New York’ must physically end up on the same Worker Node to be summed together, regardless of which node originally read those records from disk.
Shuffling is the most expensive and resource-intensive operation in distributed compute. It requires massive amounts of disk I/O to write intermediate data, high CPU utilization for data serialization, and intense network bandwidth to transmit the data between nodes. The primary goal of query optimizers and data engineers is to minimize shuffle operations. Techniques like broadcast joins (where a small table is simply copied to every node to avoid shuffling a massive table) are explicitly designed to circumvent the performance penalty of distributed shuffles.
Fault Tolerance and Resilience
Operating thousands of networked machines guarantees that hardware failures will occur. Hard drives will die, network switches will drop packets, and virtual machines will be preempted. A robust distributed compute engine must be fault-tolerant; it must survive node failures without failing the entire query.
Different engines handle fault tolerance differently based on their architectural goals.
Apache Spark is highly fault-tolerant. It tracks the lineage of all data partitions (RDDs). If a Worker Node dies mid-computation, the Spark Master Node simply looks at the lineage, spins up a new task on a different Worker Node, and recomputes only the missing partition from the original source data. Furthermore, during massive shuffles, Spark writes intermediate data to local disks. If a subsequent stage fails, Spark can recover by reading the intermediate files rather than restarting the entire multi-hour pipeline.
Engines like Trino or Presto prioritize extreme speed over fault tolerance. They execute queries entirely in memory and pipeline data directly between workers. If a Worker Node fails during a Trino query, the entire query typically fails and must be restarted from the beginning by the user. While recent versions of Trino have introduced fault-tolerant execution modes that write intermediate data to disk, it trades the blazing speed of in-memory pipelining for the reliability required by long-running ETL jobs.
Summary and Tradeoffs
Distributed compute is the engine of the big data revolution. By harnessing the collective power of thousands of interconnected machines, frameworks like Spark, Flink, and Trino enable the processing of unimaginable data volumes, forming the computational backbone of the open data lakehouse.
The primary tradeoff of distributed compute is inherent complexity. Designing, deploying, and tuning a distributed system is exponentially more difficult than managing a single server. Engineers must contend with network latency, data skew (where one node receives disproportionately more data than others, bottlenecking the entire cluster), and complex memory management tuning (like preventing out-of-memory errors during massive shuffles).
While modern serverless platforms like Databricks or Amazon Athena abstract away the hardware management, understanding the principles of data partitioning, shuffling, and master-worker coordination remains essential for any data professional looking to build performant, cost-effective data platforms.
Visual Architecture