Dremio
Dremio is an open lakehouse platform purpose-built for Apache Iceberg, providing a high-performance query engine, a semantic layer, an integrated Apache Polaris-based catalog, and AI-native capabilities that together constitute what Dremio calls the Agentic Lakehouse — an architecture designed to make governed, semantically enriched data accessible to both human analysts and AI agents simultaneously. As of May 2026, SAP announced a definitive agreement to acquire Dremio, with the intention of integrating Dremio’s technology into the SAP Business Data Cloud to create an Iceberg-native enterprise lakehouse that eliminates data silos between SAP and non-SAP systems.
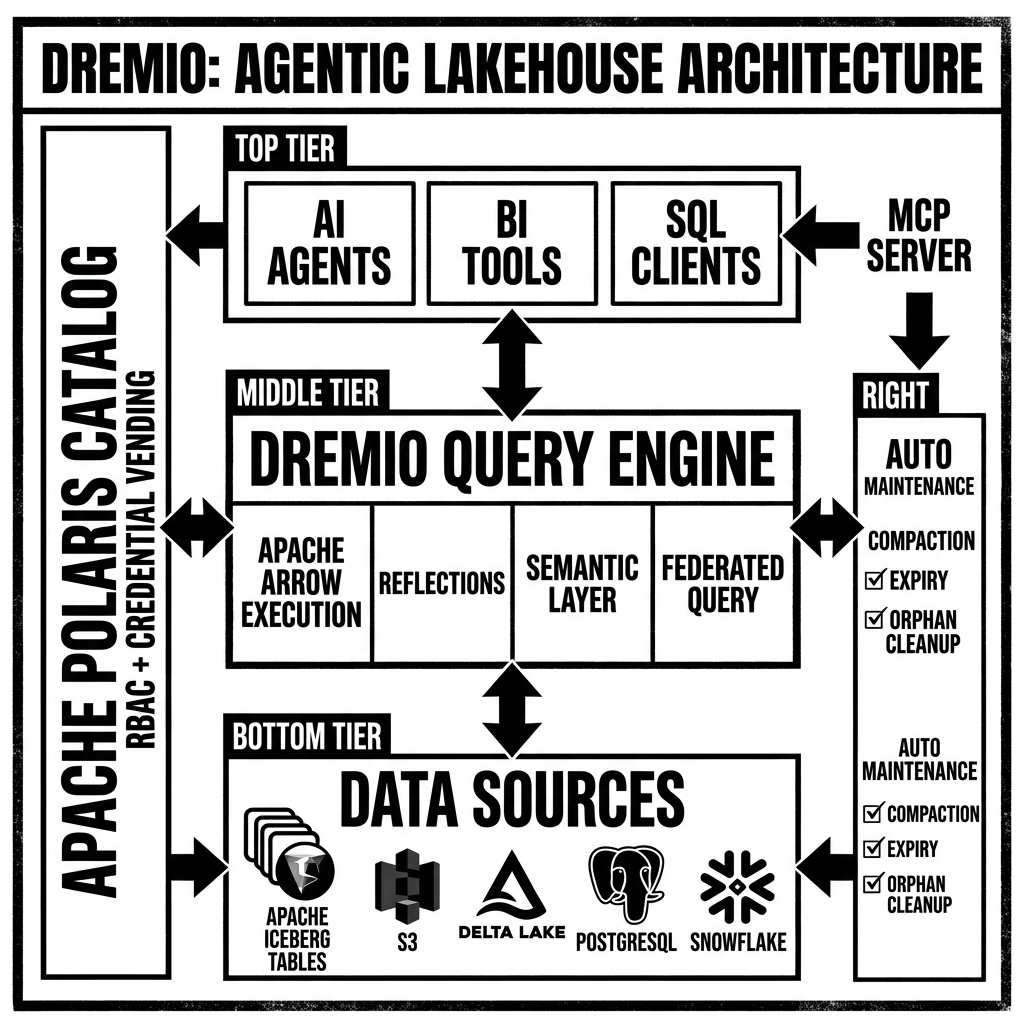
Dremio’s architecture is built entirely on open standards: Apache Iceberg for the table format, Apache Arrow for in-memory columnar data processing, and Apache Polaris for the catalog. This open foundation enables multi-engine interoperability — any engine that speaks Iceberg REST Catalog can access the same tables governed by the same policies — while Dremio’s proprietary differentiation lives in the semantic layer, the query optimization engine, and the AI-native capabilities layered on top.
The Core Architecture
Apache Iceberg as the Native Foundation
Dremio is engineered from the ground up for Apache Iceberg, not adapted to it as an afterthought. The platform supports the complete Iceberg feature set:
Full ACID Write Semantics: Dremio’s DML capabilities include INSERT INTO, MERGE INTO, UPDATE, and DELETE — all implemented through Iceberg’s atomic snapshot-based commit protocol. Every write operation produces a new immutable Iceberg snapshot; no partial write is ever visible to concurrent readers.
Iceberg V3 Specification Support: Dremio supports the Iceberg V3 format specification, including deletion vectors (a more efficient physical representation of row-level deletes), variant data types for semi-structured data, and the updated Puffin statistics file format.
Time Travel: Dremio SQL supports Iceberg snapshot time travel:
SELECT * FROM orders FOR VERSION AS OF 12345;
SELECT * FROM orders FOR TIMESTAMP AS OF '2026-05-01 00:00:00';This enables point-in-time queries for audit, debugging, and reproducible reporting against any Iceberg table in the catalog.
Schema Evolution: Dremio handles all five Iceberg schema evolution operations — add column, drop column, rename column, update column type (safe widening only), and reorder columns — as atomic metadata-only operations that take effect immediately without rewriting data.
Partition Evolution and Hidden Partitioning: Dremio’s query planner is aware of Iceberg’s hidden partitioning and partition evolution. It translates SQL predicates on source columns into the correct partition filter for each data file’s partition spec, regardless of how many times the partition scheme has evolved since the table was created.
Apache Arrow: The In-Memory Execution Engine
Dremio’s query execution engine is built on Apache Arrow — the columnar in-memory format that has become the universal standard for analytical data processing. Arrow’s columnar memory layout enables SIMD vectorized execution across entire columns of values simultaneously, producing dramatically higher CPU throughput than row-at-a-time processing models.
Dremio’s Arrow-based execution pipeline:
Arrow Flight: Dremio uses Apache Arrow Flight as its primary data transport protocol for result set transfer between the query coordinator and downstream consumers (BI tools, Python clients, JDBC clients). Arrow Flight delivers result sets as columnar Arrow record batches over gRPC, eliminating the row serialization overhead of traditional JDBC/ODBC transfers. Arrow Flight SQL extends this with standard SQL query submission capabilities, making it the recommended high-performance connection protocol for Dremio.
C++ Execution Kernels: Dremio’s execution engine uses native C++ Gandiva kernels (the Apache Arrow LLVM expression compiler) for expression evaluation, enabling just-in-time compilation of query expressions into machine code optimized for the host CPU’s instruction set (AVX-512, AVX-2, etc.).
Columnar Aggregation and Hash Joins: All aggregation, join, and sort operations in Dremio process data in columnar batches, maintaining the Arrow columnar format throughout the execution pipeline without row-by-row deserialization.
The Integrated Apache Polaris Catalog
Dremio’s integrated catalog is built on Apache Polaris — the open-source Iceberg REST Catalog implementation that Dremio co-created and donated to the Apache Software Foundation. The catalog provides:
REST Catalog API: Full implementation of the Apache Iceberg REST Catalog specification, enabling any Iceberg REST Catalog-compatible engine (Spark, Flink, Trino, PyIceberg, Snowflake) to discover and access Dremio-managed Iceberg tables through the standard REST protocol.
Hierarchical RBAC: Dremio’s catalog enforces role-based access control at the catalog, namespace, and table level. Principal roles are assigned to service accounts and user identities; catalog roles define the specific privileges (read, write, DDL) granted on specific catalog resources; role-grant bindings connect principals to catalog roles.
Credential Vending: When external engines (Spark, Flink, Trino) access Dremio-managed Iceberg tables through the REST Catalog API, Dremio’s credential vending engine generates short-lived, scoped cloud storage credentials (AWS STS tokens for S3, SAS tokens for ADLS, access tokens for GCS) valid only for the specific table’s storage paths. External engines have no standing cloud storage permissions — all storage access is mediated through the catalog’s credential vending.
Multi-Engine Interoperability: Because Dremio’s catalog implements the open Polaris/REST Catalog API, the same Iceberg tables can be accessed by Dremio for high-performance BI and analytics, Spark for heavy ETL transformations, Flink for streaming ingestion, and PyIceberg for data science workflows — all governed by the same RBAC policies, all receiving scoped credentials from the same catalog service.
The Semantic Layer: Dremio’s Most Important Differentiator
Dremio’s semantic layer is the architectural capability that most clearly distinguishes it from raw query engines. It is a managed layer of virtual datasets — SQL views, computed columns, relationships, and business metric definitions — that sits between the physical data in Iceberg tables and the queries submitted by analysts, BI tools, and AI agents.
What the Semantic Layer Provides
Business Logic Centralization: Instead of embedding business logic (revenue calculations, customer segmentation rules, fiscal calendar transformations) in individual BI tool reports, dbt models, or Spark jobs, Dremio’s semantic layer captures this logic once, in SQL views, and makes it universally accessible. Every consumer — a Tableau dashboard, a Python notebook, an AI agent — executes the same business logic when they query the semantic layer’s virtual datasets.
Virtual Datasets: Virtual datasets are SQL views registered in Dremio’s semantic layer. They can join multiple physical Iceberg tables, apply filter conditions, compute derived columns, and define aggregation logic. From the consumer’s perspective, a virtual dataset looks identical to a physical table: it has a schema, it’s discoverable in the catalog, and it’s queryable with standard SQL.
Physical Dataset Promotion: Physical Iceberg tables can be promoted directly into the semantic layer with reflections (discussed below), making their data directly queryable through the semantic layer without any view transformation.
Semantic Context for AI: When AI agents query data through Dremio’s Model Context Protocol (MCP) server or through AI-native SQL functions, they operate against the semantic layer’s virtual datasets. This ensures AI agents interpret data using the same business definitions as human analysts — “revenue” means the same thing to an AI agent’s SQL query as it does to a Tableau report, because both query the same semantic layer view that defines it.
Reflections: Transparent Query Acceleration
Dremio’s Reflections system is the mechanism that makes semantic layer queries fast without requiring users to manage pre-aggregated summary tables or materialized views manually.
A Reflection is a pre-computed, Iceberg-format materialized result set that Dremio’s query planner can transparently substitute for portions of a query plan when it would produce identical results faster than reading from the source. Reflections come in two types:
Aggregation Reflections: Pre-computed aggregations (GROUP BY results with SUM, COUNT, AVG, etc.) stored as Iceberg Parquet files. When a query requests a compatible aggregation, the planner uses the reflection instead of the source table.
Raw Reflections: Pre-copied and pre-sorted subsets of source data, stored as Iceberg Parquet files with Hilbert-based clustering. When a query filters and reads from a compatible subset of the source, the planner reads from the smaller, pre-sorted reflection.
Reflections are transparently substituted — users and BI tools don’t know they exist. They submit a query against the source table or virtual dataset; Dremio’s planner transparently routes to the matching reflection. Reflections refresh automatically when source data changes and are managed entirely by Dremio without user intervention.
Federated Query: Data in Place
Dremio’s federated query engine allows queries to span multiple data sources without requiring data to be copied into a central repository. Sources include:
- Object storage: AWS S3, Azure ADLS, Google Cloud Storage — reading Iceberg, Delta Lake, Hudi, Parquet, ORC, JSON, and CSV files directly.
- Relational databases: PostgreSQL, MySQL, SQL Server, Oracle — querying live OLTP data in place.
- Data warehouses: Snowflake, BigQuery, Redshift — federating across cloud DW systems.
- NoSQL / document stores: MongoDB, Elasticsearch — querying non-relational sources with SQL.
Dremio’s query planner applies predicate pushdown to each source — pushing WHERE conditions as deep as possible into each source’s native execution layer — and performs cross-source joins by pulling results into Arrow memory and executing the join in Dremio’s execution engine.
For organizations with heterogeneous data environments (operational databases + data lakes + cloud DWs), Dremio’s federation capability enables unified analytics without mandatory ETL-to-centralize pipelines.
Automatic Table Optimization
Dremio provides fully automated Iceberg table maintenance — compaction, snapshot expiry, and orphan file cleanup — that runs continuously in the background without requiring user-scheduled maintenance jobs:
Automatic Compaction: Dremio monitors each Iceberg table’s file size distribution and triggers compaction automatically when small-file accumulation reaches a configurable threshold. Compaction uses Hilbert curve clustering to produce optimally sized, well-clustered output files that maximize data skipping effectiveness for subsequent queries.
Snapshot Expiry: Dremio enforces configurable snapshot retention policies, automatically expiring old Iceberg snapshots beyond the retention window while preserving the snapshots needed for active time-travel queries.
Orphan File Cleanup: Dremio identifies and removes orphan data files — Parquet files left by failed write operations that are not referenced by any Iceberg snapshot.
Manifest Compaction: As tables accumulate many small Manifest Files (from streaming ingestion or frequent small writes), Dremio’s optimizer periodically rewrites them into fewer, larger Manifests, keeping query planning metadata reads fast.
AI-Native Capabilities: The Agentic Lakehouse
Dremio’s AI capabilities are natively integrated into the platform rather than bolted on as external tools:
Built-in AI SQL Functions
Dremio provides AI SQL functions that allow LLM capabilities to be invoked directly within SQL queries:
-- Classify customer feedback into sentiment categories
SELECT
customer_id,
feedback_text,
AI_CLASSIFY(feedback_text, ARRAY['positive', 'negative', 'neutral']) AS sentiment
FROM customer_feedback;
-- Generate structured summaries of unstructured support tickets
SELECT
ticket_id,
AI_COMPLETE('gpt-4o', 'Summarize this support ticket: ' || ticket_text) AS summary
FROM support_tickets;
-- Extract entities from unstructured text
SELECT
document_id,
AI_GENERATE('Extract the company name and contract value from: ' || contract_text) AS entities
FROM contracts;These functions execute AI inference calls as part of the SQL execution pipeline, enabling AI-powered data transformations without separate Python infrastructure.
Model Context Protocol (MCP) Server
Dremio’s MCP server exposes the lakehouse’s semantic layer to AI agents and assistants (Claude, ChatGPT, custom agents) through the open Model Context Protocol standard. AI agents connect to the Dremio MCP server and gain:
- Semantic layer awareness: The agent can discover virtual datasets, understand their schemas and business metric definitions, and formulate accurate SQL queries against the semantic layer.
- Natural language to SQL: The MCP server handles the translation of natural language data questions into SQL queries against the semantic layer, ensuring AI-generated queries respect the same business logic as human-authored queries.
- Governed access: The MCP server enforces the same RBAC policies as the REST Catalog — AI agents can only access data that their configured service account is authorized to read.
AI Assistants in the Dremio UI
Dremio’s web UI includes integrated AI assistants that help users:
- Generate SQL queries from natural language descriptions
- Explain query plans and identify performance bottlenecks
- Recommend Reflections based on observed query patterns
- Describe dataset schemas and their business context
The SAP Acquisition: Strategic Context
In May 2026, SAP announced its acquisition of Dremio with a stated goal of transforming the SAP Business Data Cloud into an Apache Iceberg-native enterprise lakehouse. The integration targets several specific capabilities:
Zero-ETL SAP Data Access: Dremio’s federated query engine will enable direct, live querying of SAP data (SAP S/4HANA, SAP BW, SAP HANA) alongside non-SAP data lakes — eliminating the traditional requirement to ETL SAP data into a separate analytics platform.
SAP Knowledge Graph + Polaris Catalog: The Polaris-based catalog’s metadata management capabilities will be extended to include the SAP Knowledge Graph — a semantic model of SAP business entities, relationships, and lineage that provides AI agents with business context for understanding SAP data.
Semantic Layer for SAP Business Metrics: Dremio’s semantic layer will serve as the governance layer for standardized SAP business metrics (order-to-cash KPIs, financial planning metrics, supply chain analytics), ensuring that AI agents querying SAP data interpret business concepts through the same governed definitions as human analysts.
Dremio Cloud vs. Dremio Software
Dremio is available in two deployment models:
Dremio Cloud: A fully managed SaaS platform hosted by Dremio (on AWS). Users provision a Dremio Cloud project and connect their existing object storage (S3, ADLS, GCS) as data sources. Dremio Cloud includes the integrated Polaris-based catalog, automatic table optimization, the semantic layer, AI capabilities, and the MCP server — all managed by Dremio’s infrastructure team.
Dremio Software: A self-hosted version of the Dremio platform that can be deployed on Kubernetes (using Helm charts) on any cloud or on-premises infrastructure. Dremio Software provides the same query engine and semantic layer capabilities as Dremio Cloud, with customers responsible for operating the infrastructure.
Conclusion
Dremio represents the most architecturally complete implementation of the “open lakehouse” vision: a platform that combines the openness of Apache Iceberg (format), Apache Polaris (catalog), and Apache Arrow (execution) with the enterprise capabilities — semantic layer governance, AI-native SQL functions, automatic table optimization, federated query, and MCP server integration — that make the open lakehouse usable at enterprise scale for both human analysts and AI agents. Its acquisition by SAP extends this architecture into the SAP ecosystem, creating the potential for a genuinely unified enterprise lakehouse that spans SAP transactional systems and open data lakes under a single governance model. For organizations building Iceberg-based lakehouses who need more than a raw query engine — who need semantic governance, AI integration, and automated operational management — Dremio provides the most functionally complete open lakehouse platform available.
Visual Architecture