DuckDB
DuckDB is an open-source, in-process SQL OLAP database management system. Often described as the “SQLite for analytics,” DuckDB has fundamentally transformed how data engineers and scientists approach local data processing. Rather than running as a standalone server process that clients connect to over a network, DuckDB is embedded directly into a host process. By combining a highly optimized, vectorized execution engine with zero-copy integration into languages like Python and R, DuckDB enables blistering fast analytical queries on massive datasets directly on a developer’s laptop or an edge device.
Core Definition
The creators of DuckDB recognized a glaring gap in the database ecosystem. While systems like PostgreSQL and SQLite excelled at transactional (OLTP) workloads, they were notoriously slow for analytical aggregations. Conversely, powerful analytical engines like Apache Spark or Trino were complex distributed systems that required significant infrastructure to deploy and manage. There was no simple, high-performance analytical database designed for local, embedded use.
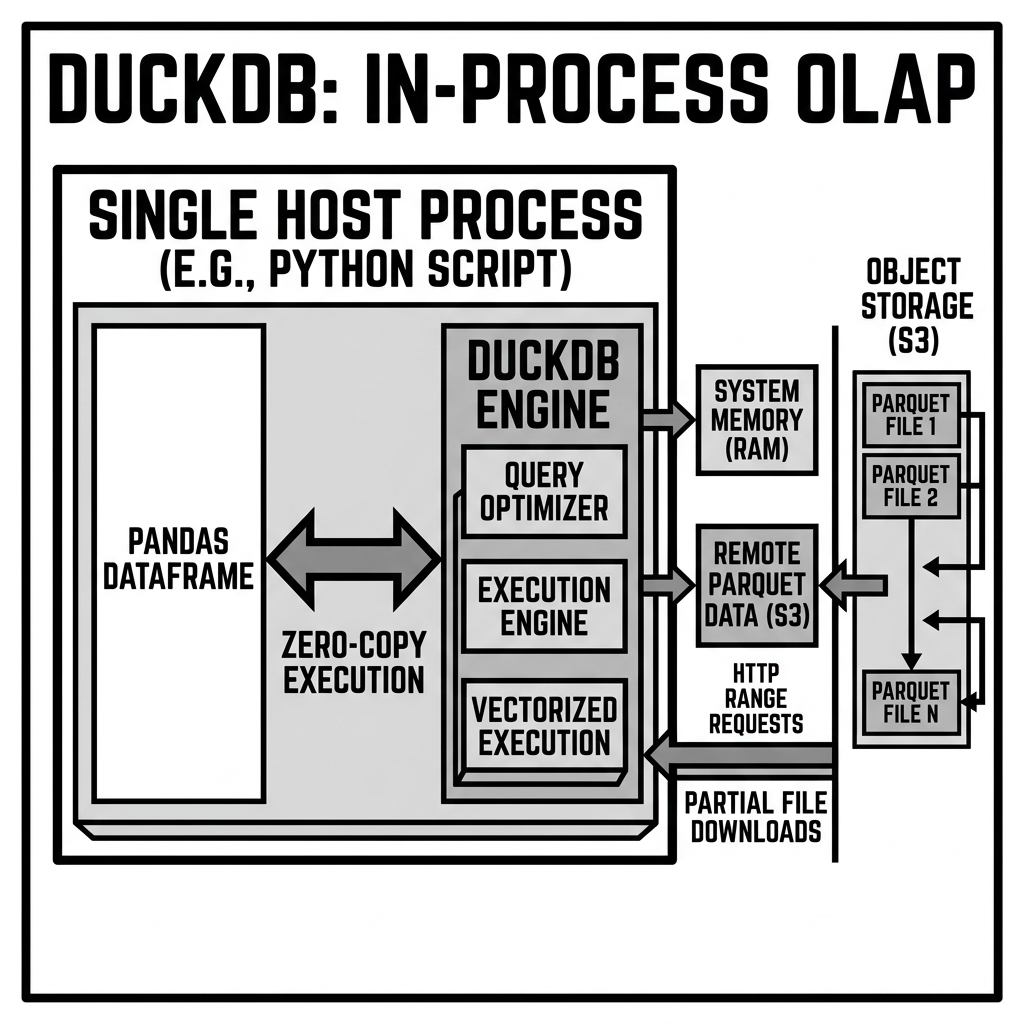
DuckDB was developed in 2018 at the Centrum Wiskunde & Informatica (CWI) in the Netherlands to fill this void. Because DuckDB is an in-process database, it eliminates the client-server overhead entirely. When a Python script queries DuckDB, there is no network serialization, no socket communication, and no inter-process context switching. The database engine runs in the same memory space as the application.
This architectural decision has profound performance implications, particularly when interacting with popular data science tools like Pandas or Apache Arrow. Because they share the same memory space, DuckDB can execute a SQL query on a Pandas DataFrame or an Arrow table without copying the data into its own internal format. This zero-copy execution allows users to query gigabytes of data on a standard laptop in milliseconds.
Architecture and Components
DuckDB is built around a columnar storage architecture and a vectorized query execution engine.
In a traditional row-based database, a query that sums a single column must load every entire row into the CPU cache, wasting enormous amounts of memory bandwidth on irrelevant data. DuckDB’s columnar layout ensures that only the data strictly required for the query is loaded from disk or memory.
Furthermore, DuckDB processes data in vectors (batches of data, typically 1024 or 2048 values) rather than one row at a time. This vectorized processing model allows DuckDB to leverage SIMD (Single Instruction, Multiple Data) instructions on modern processors. A single CPU instruction can execute an operation (like an addition or a filter) across an entire vector of values simultaneously, maximizing cache locality and minimizing branch mispredictions.
DuckDB also incorporates a highly capable Cost-Based Optimizer (CBO). Despite being an embedded database, it features advanced query optimization techniques, including join order optimization, predicate pushdown, and subquery decorrelation. This ensures that even complex analytical queries are executed efficiently.
Integration with the Data Lakehouse
While DuckDB shines at local, in-memory processing, its role in the broader data lakehouse ecosystem has expanded significantly. DuckDB is no longer just a tool for local CSV files; it has become a powerful engine for interacting with cloud-based object storage and open table formats.
Through its extension ecosystem, DuckDB can read directly from Amazon S3, Google Cloud Storage, and Azure Blob Storage. When executing a query like SELECT SUM(revenue) FROM 's3://bucket/data.parquet', DuckDB does not download the entire file. It uses HTTP Range Requests to read only the specific Parquet file footers, extracts the required column chunks, and streams the data into its execution engine.
Furthermore, DuckDB has developed robust integrations with Apache Iceberg. Using the official Iceberg extension, DuckDB can connect to a REST catalog, retrieve the Iceberg metadata tree, apply partition pruning, and query the underlying data files directly. This capability has led to the rise of “headless” data architecture patterns, where serverless functions or local applications use DuckDB to execute fast, ad-hoc analytics directly against the production data lake without spinning up expensive Spark or Trino clusters.
Beyond Local Processing: MotherDuck
The massive popularity of DuckDB has spawned commercial ecosystems, most notably MotherDuck. MotherDuck is a managed cloud service built around DuckDB that introduces a hybrid execution model.
In a hybrid execution model, the DuckDB engine running locally on a user’s machine collaborates intelligently with a DuckDB engine running in the MotherDuck cloud. If a user queries a small, local CSV file, the query executes entirely on the local machine. If the user queries a massive, petabyte-scale dataset, the query executes in the cloud. Most impressively, if a user writes a SQL query that joins a local CSV file with a massive cloud table, DuckDB will automatically route the processing to minimize data transfer, seamlessly blending local and remote execution.
Summary and Tradeoffs
DuckDB has democratized high-performance analytics. By bringing vectorized execution and columnar processing directly into the host process, it has become the undisputed king of local data engineering and data science workflows. Its tight integration with Apache Arrow and its ability to query remote object storage have cemented its place in the modern data stack.
The primary tradeoff with DuckDB is inherent to its design: it is not a distributed system. DuckDB is designed to scale up on a single machine, utilizing all available CPU cores and memory. It cannot distribute a single query across multiple machines in a cluster like Apache Spark or Trino. Consequently, if a dataset is truly massive (tens of terabytes or larger) and requires complex shuffle operations that exceed the capacity of a single high-end server, DuckDB is not the appropriate tool.
However, as single machines become increasingly powerful (with servers now supporting hundreds of cores and terabytes of RAM), the boundary of what DuckDB can handle continues to expand. For a vast majority of exploratory analytics, localized transformations, and data science workloads, DuckDB provides an unmatched combination of simplicity and extreme speed.
Visual Architecture