Dynamic Catalogs
Dynamic Catalogs refers to the architectural pattern of configuring query engines and data platforms to connect with multiple Iceberg catalog instances simultaneously — switching between them dynamically based on session context, query routing rules, user identity, or environmental configuration — rather than operating against a single, monolithic catalog. It is the catalog-layer architecture that enables data mesh domain separation, multi-environment management (dev/staging/production), multi-cloud lakehouse federation, and multi-tenant data isolation within a unified analytical platform.
The concept of dynamic catalogs emerged directly from the Apache Iceberg REST Catalog specification’s standardization of the catalog API. Before the REST Catalog protocol, each query engine required engine-specific connectors for each catalog type — a Spark + Glue connector, a Trino + HMS connector, a Flink + Nessie connector. Adding a new catalog meant writing and maintaining a new connector. Dynamic catalog registration was impossible because there was no universal catalog protocol for engines to speak.
The REST Catalog specification changed this fundamentally. Because every conformant catalog speaks the same HTTP API, any query engine with a REST Catalog client can dynamically add, switch, and query multiple catalog instances through the same client code. The result is a catalog architecture where engines are catalog-agnostic — they connect to any compliant catalog through the REST API — and where organizations can design their catalog topology to match their organizational and operational requirements rather than being constrained by the catalog choices their query engine supports.
The Multi-Catalog Topology
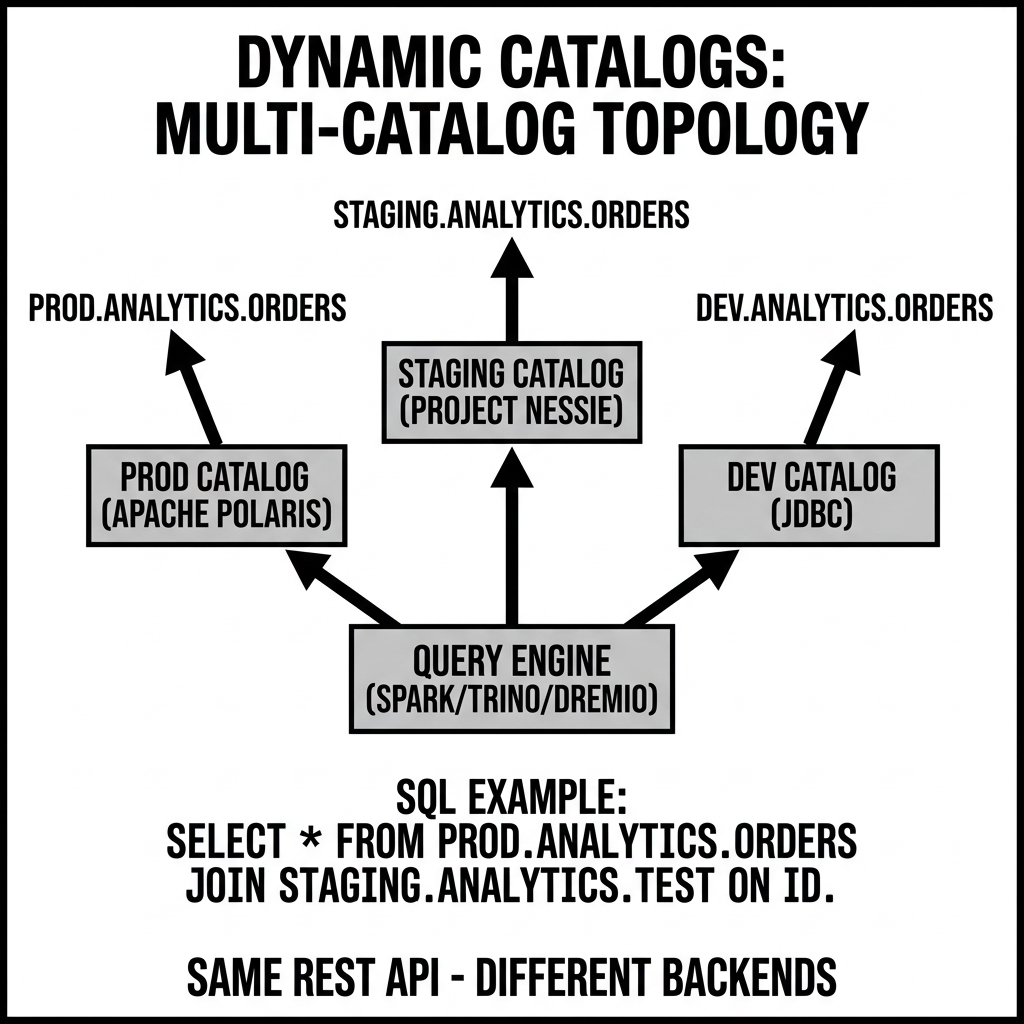
In a dynamic catalog architecture, a query engine (Spark, Trino, Dremio, Flink) maintains multiple simultaneous catalog connections, each identified by a unique catalog name prefix. SQL queries reference tables using the three-part dotted notation <catalog>.<namespace>.<table>, where the catalog name directs the query engine to the appropriate catalog connection.
Example: Multi-Catalog Spark Configuration
spark = SparkSession.builder \
# Production catalog - Apache Polaris
.config("spark.sql.catalog.prod", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.prod.catalog-impl", "org.apache.iceberg.rest.RESTCatalog") \
.config("spark.sql.catalog.prod.uri", "https://polaris-prod.example.com/") \
.config("spark.sql.catalog.prod.credential", "${PROD_TOKEN}") \
# Staging catalog - Project Nessie (staging branch)
.config("spark.sql.catalog.staging", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.staging.catalog-impl", "org.apache.iceberg.rest.RESTCatalog") \
.config("spark.sql.catalog.staging.uri", "https://nessie.example.com/api/v1") \
.config("spark.sql.catalog.staging.prefix", "staging-branch") \
# Development catalog - local JDBC
.config("spark.sql.catalog.dev", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.dev.catalog-impl", "org.apache.iceberg.jdbc.JdbcCatalog") \
.config("spark.sql.catalog.dev.uri", "jdbc:postgresql://dev-db:5432/iceberg") \
.getOrCreate()
# Cross-catalog JOIN across production and staging
spark.sql("""
SELECT p.customer_id, p.revenue, s.test_flag
FROM prod.analytics.orders p
JOIN staging.analytics.orders_test s ON p.customer_id = s.customer_id
""")This configuration registers three catalogs simultaneously. SQL queries can reference any of them using the catalog prefix, and cross-catalog joins execute in Spark’s in-memory execution engine by reading from both sources independently.
Use Case Categories for Dynamic Catalogs
1. Environment Isolation: Dev/Staging/Production
The most universal dynamic catalog pattern is environment separation. Each environment (development, staging, production) has its own catalog instance and its own storage location. Data engineers work on development catalog tables, validate changes on staging, and deploy to production.
The critical advantage of multi-catalog environment separation over Nessie-style branching is the complete infrastructure isolation it provides: development writes go to a different S3 bucket with different IAM policies than production writes. Even a catastrophically wrong development job that corrupts its catalog’s metadata cannot affect production data, because the production catalog and production storage are entirely separate.
When environment separation uses the same catalog technology (three Polaris instances, or three Glue catalogs, or three Nessie instances), the dynamic catalog architecture allows developers to write ETL code that references dev.analytics.orders in development and switch to prod.analytics.orders in production by changing only the catalog prefix — the table name, namespace, and SQL logic remain identical.
2. Data Mesh: Domain-Separated Catalogs
In a data mesh architecture, each domain (marketing, finance, engineering, supply chain) owns its own data products — including its own catalog. The marketing team’s catalog contains the tables that the marketing team owns and governs. The finance team’s catalog is independently administered by the finance team.
A centralized query engine (Dremio, Trino) with dynamic catalog support can connect to all domain catalogs simultaneously, enabling cross-domain analytical queries:
-- Cross-domain analytics: marketing + finance data
SELECT
m.campaign_id,
m.impressions,
f.revenue_attributed
FROM marketing.campaigns.display_ads m
JOIN finance.attribution.campaign_revenue f ON m.campaign_id = f.campaign_id;Each domain retains independent governance of its catalog (its own RBAC policies, its own table schema management, its own maintenance schedules) while cross-domain queries are possible through the federation layer.
3. Multi-Cloud Federation
Organizations with data in multiple cloud providers (AWS S3 + Azure ADLS, or AWS East + AWS West for regional data residency) can register one catalog per cloud location as separate catalog connections in their query engine.
The REST Catalog specification’s credential vending mechanism is essential for multi-cloud federation: when the query engine loads a table from the AWS Glue catalog, it receives STS credentials scoped to S3 paths; when it loads a table from an Azure-backed Polaris catalog, it receives SAS tokens scoped to ADLS paths. The engine manages multiple simultaneous credential sets, one per catalog.
4. Multi-Tenant Isolation
SaaS platforms that serve multiple customers (tenants) on shared infrastructure can provide per-tenant catalog isolation by registering one catalog per tenant. Each tenant’s catalog contains only their tables; the tenant’s service account is granted access only to their catalog. The query engine routes tenant queries to the tenant-specific catalog based on the authenticated user’s tenant identity, enforcing complete metadata isolation between tenants without requiring separate query engine deployments per tenant.
5. Catalog-of-Catalogs: Metadata Federation
The most sophisticated multi-catalog pattern is the “catalog of catalogs” — a single catalog service (like Apache Polaris’s federated catalog feature, or Apache Gravitino) that acts as a unified metadata gateway over multiple underlying catalog backends.
In this pattern, the query engine connects to a single REST Catalog endpoint. The federated catalog service maintains registrations of underlying catalogs (a Glue catalog for AWS data, an HMS for on-premises data, a Nessie catalog for experimental branches). When the query engine requests table metadata, the federated catalog proxies the request to the appropriate underlying catalog based on the namespace routing configuration.
Apache Gravitino is an open-source project (from Datastrato, donated to Apache) that implements this catalog-of-catalogs pattern. It registers multiple backend catalogs (Hive, Iceberg, Delta, Delta, JDBC) under a unified namespace and exposes a single REST-compatible API to query engines. From the query engine’s perspective, there is one catalog; from the governance perspective, the federated catalog manages and routes to multiple backends.
Dynamic Catalog Registration at Runtime
The static multi-catalog configuration (specified at engine startup) works for fixed catalog topologies but is insufficient for environments where catalogs are dynamically provisioned (tenant onboarding, environment creation). Query engines that support runtime catalog registration can add new catalog connections without restarting the engine:
Trino dynamic catalog: Trino supports a CREATE CATALOG command that registers a new catalog at runtime, making it immediately available to sessions:
CREATE CATALOG new_tenant_catalog USING iceberg
WITH (
"iceberg.catalog.type" = 'rest',
"iceberg.rest-catalog.uri" = 'https://polaris.example.com/',
"iceberg.rest-catalog.security" = 'OAUTH2',
"iceberg.rest-catalog.oauth2.token" = '<token>'
);Spark dynamic catalog loading: Spark 3.x supports runtime addition of catalog configurations through SparkConf updates, though this is more complex than Trino’s declarative approach.
Dremio source management: Dremio’s UI and REST API allow new data sources (including Iceberg REST Catalog sources) to be added at runtime, immediately making them available to SQL queries without engine restart.
Cross-Catalog Query Performance Considerations
Cross-catalog queries are powerful but not cost-free. Performance characteristics to understand:
Network I/O: A join between tables in catalog A (on S3 us-east-1) and catalog B (on GCS us-central1) requires reading data from both cloud regions. Cross-region data transfer is both slow (latency) and expensive (egress charges). Cross-catalog architectures should minimize cross-region joins where possible, or cache frequently joined cross-region data using Reflections (Dremio) or materialized views.
Credential management overhead: Each catalog connection maintains its own set of short-lived storage credentials. The query engine must track credential expiry for each catalog and refresh them independently, adding coordination overhead for long-running cross-catalog queries.
Planning complexity: Query planners must optimize across multiple catalog statistics when generating cross-catalog join plans. Statistics quality differences between catalogs (one catalog with column-level statistics, another with only row counts) can lead to suboptimal join order selections.
Metadata latency: Each catalog read (loading table metadata) adds a network round-trip to the catalog’s REST endpoint. Queries spanning many tables across multiple catalogs accumulate planning latency from multiple catalog reads. Metadata caching at the engine level is essential for maintaining acceptable planning latency in high-frequency multi-catalog environments.
Security in Multi-Catalog Environments
The security model for dynamic catalogs must address several distinct challenges:
Per-catalog authentication: Each catalog enforces its own authentication and authorization. An engine credential (OAuth token, IAM role) that is valid for catalog A may have no privileges in catalog B. Multi-catalog environments require managing distinct credentials per catalog, with appropriate secret management for each.
Credential scope isolation: Even within a single query that spans multiple catalogs, the storage credentials vended by catalog A must not be usable to access catalog B’s storage, and vice versa. This isolation is enforced through the credential vending mechanism’s scoping to specific S3 prefixes — credentials from catalog A are scoped to catalog A’s warehouse prefix and cannot access catalog B’s warehouse prefix even if both are in the same S3 bucket.
Cross-catalog data exfiltration prevention: In multi-tenant environments, preventing a tenant’s query from accidentally or maliciously accessing another tenant’s catalog data requires that the query engine enforce catalog prefix isolation — ensuring that queries submitted in the context of tenant A’s session can only reference tenant A’s catalog prefix.
Conclusion
Dynamic Catalogs are the architectural pattern that bridges the abstract interoperability promise of the Iceberg REST Catalog specification and the practical reality of multi-environment, multi-domain, multi-cloud enterprise data lakehouse operations. By enabling query engines to simultaneously connect to and query multiple Iceberg catalog instances through the uniform REST protocol, dynamic catalogs enable domain-separated data mesh architectures, complete environment isolation, multi-cloud analytics federation, and scalable multi-tenant data platforms. The catalog-of-catalogs pattern (Gravitino, Polaris federation) takes this further, providing a unified metadata gateway over heterogeneous catalog backends. Engineers designing lakehouse catalog topologies for organizations with complex organizational, geographic, or operational requirements will find dynamic catalog patterns an essential tool for achieving both governance separation and analytical unification.
Visual Architecture