ELT (Extract, Load, Transform)
ELT (Extract, Load, Transform)
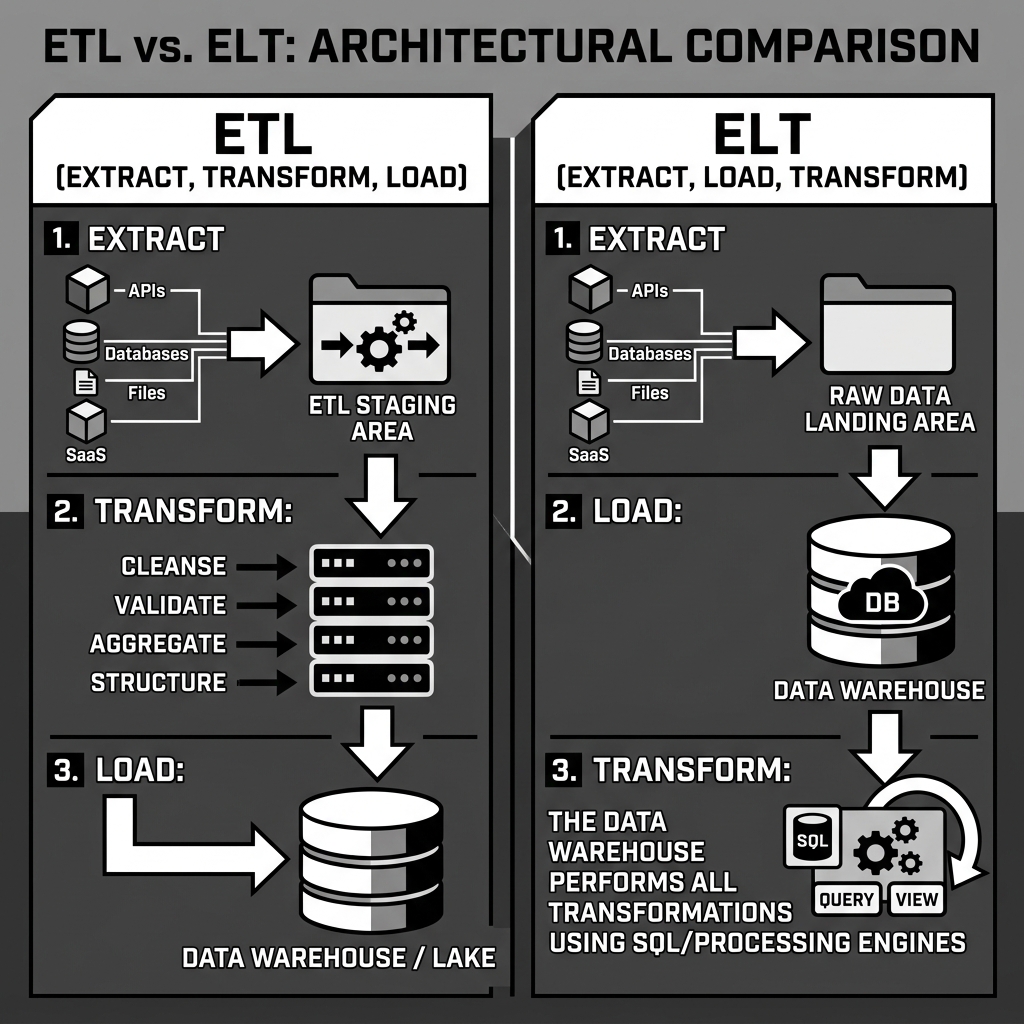
For decades, the dominant pattern for moving data from source systems into analytical databases was ETL: Extract, Transform, Load. In this sequence, data was pulled from source systems, processed and cleaned in a dedicated intermediary staging environment, and only then loaded into the data warehouse in its final, structured form. This approach made sense in an era when storage in the data warehouse was expensive and compute power was limited. You did not want to fill your expensive warehouse with raw, unprocessed garbage.
The economics of modern cloud computing have fundamentally changed this calculus. Cloud data warehouses like BigQuery, Snowflake, and Redshift, and cloud data lakehouses built on Parquet and Apache Iceberg, offer virtually unlimited storage at commodity prices and near-infinite elastic compute. The constraint is no longer how much you can store. The constraint is now how quickly you can make data available for analysis.
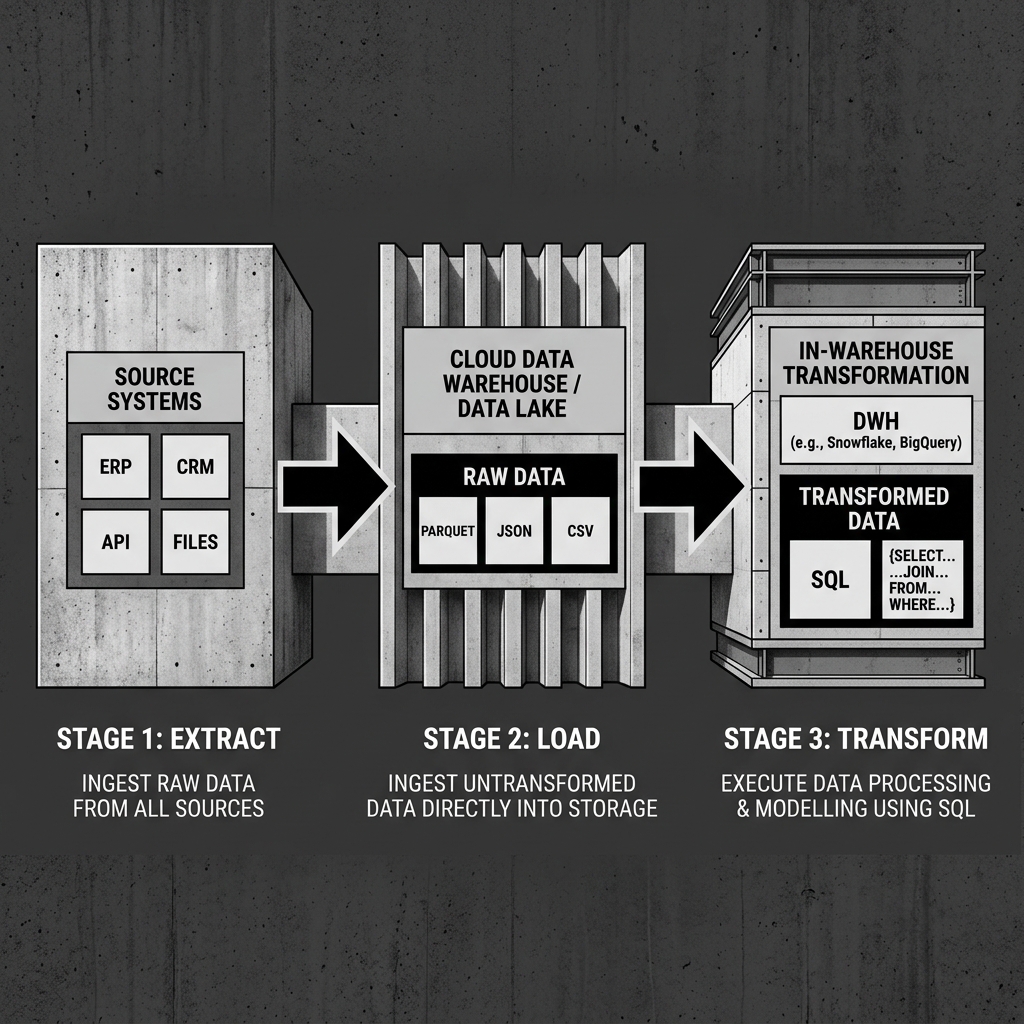
This shift gave rise to ELT: Extract, Load, Transform. In ELT, data is extracted from source systems in its raw form, loaded directly into the target system without any prior transformation, and then transformed inside that target system using its native, massively parallel SQL compute engine. The transformation step happens after the data has been safely stored, not before.
How ELT Works
The first stage, Extract, is functionally identical to the corresponding step in traditional ETL. Connectors or ingestion tools pull data from source systems. These sources might include relational databases (via change data capture or full table exports), REST APIs, webhooks, cloud SaaS platforms, or streaming event systems. Popular ingestion tools that handle this extraction stage include Fivetran, Airbyte, dlt (data load tool), and custom-built Python scripts.
The second stage, Load, is where ELT diverges dramatically from ETL. Rather than routing the extracted data through a transformation engine, ELT pipelines write the raw data directly into the target system, typically into a “Raw” or “Bronze” schema. The data is stored in exactly the format it arrived in: messy column names, inconsistent date formats, duplicates, nulls, and all. The key insight is that modern cloud warehouses and lakehouses are powerful enough that storing and querying raw data is not a problem. The cost of storing an extra copy of unprocessed data is trivial compared to the cost of delaying access to it.
The third stage, Transform, is where the real work of data modeling and business logic application happens. Now that all the raw data is safely stored in the target system, data engineers use the warehouse’s own SQL compute engine to run transformations. This is almost always done using dbt (data build tool), which allows engineers to write transformation logic as version-controlled SQL SELECT statements. dbt compiles these statements into the appropriate DDL and DML commands and executes them against the warehouse, materializing the results as tables or views.
Diagram 1: ELT Architecture
The dbt Transformation Layer
dbt has become so synonymous with ELT that the two are often discussed together. Understanding ELT in a modern data stack context requires understanding what dbt enables.
In dbt, each transformation is defined as a SQL SELECT statement in a .sql file. The result of that SELECT is materialized as either a view, a table, or an incremental table in the warehouse. Data engineers organize these models in a dependency graph: a “customers” model might depend on a raw “orders” model, and a “monthly_revenue” model might depend on both the “customers” and “orders” models. dbt automatically resolves these dependencies and executes the models in the correct order.
This approach has several major advantages over traditional ETL. First, all transformation logic is in SQL, which is readable by both data engineers and data analysts. Second, all models are version-controlled in Git, providing a full audit trail of every transformation change. Third, dbt includes native support for automated testing, allowing engineers to assert that specific columns must not be null, that specific values must be unique, or that the results of a transformation must match expected row counts. Fourth, dbt generates automatic documentation, including a lineage graph that shows exactly how every model in the warehouse relates to its upstream sources and downstream dependents.
Diagram 2: ETL vs ELT Comparison
ELT and the Data Lakehouse
The ELT pattern maps directly onto the Medallion Architecture used in data lakehouses. In a lakehouse context:
The Extract and Load stages correspond to raw data landing in the Bronze layer. Ingestion tools write raw data into Bronze Iceberg tables, preserving the original format and structure. Because Apache Iceberg provides ACID transactions, these writes are safe and atomic even if the source system sends partial batches.
The Transform stages correspond to the Bronze-to-Silver and Silver-to-Gold transformations. SQL-based transformation frameworks like dbt, along with distributed compute engines like Apache Spark or Dremio, read from the Bronze tables and write refined, modeled data into Silver and Gold Iceberg tables. Because the transformations run inside the lakehouse itself against data that is already stored locally, the query engines can take advantage of Iceberg’s partition pruning, file-level statistics, and columnar formats to make these transformations highly efficient.
The ELT pattern also enables a feedback loop that traditional ETL systems struggle to provide: the ability to re-derive transformations from the raw data. Because the raw Bronze data is preserved indefinitely, engineers can fix a broken transformation logic and reprocess the entire historical dataset from scratch without needing to re-ingest from the source system. This historical reprocessing capability is one of the most operationally valuable properties of the ELT pattern in a modern lakehouse.
When ELT is Not Appropriate
Despite its advantages, ELT is not always the right choice. There are scenarios where traditional ETL remains preferable. If the source data is so sensitive that it must be anonymized or encrypted before it is stored anywhere, ELT is problematic: loading raw PII into the lakehouse before transforming it creates a compliance exposure. In these cases, an ETL approach that removes or masks sensitive fields in the extraction stage before loading provides a stronger compliance posture.
Similarly, if the source system generates extremely high volumes of data that are heavily filtered before analysis, such as high-frequency IoT telemetry where only anomalous readings matter, it may be more cost-effective to filter aggressively at the extraction stage rather than landing everything in the lakehouse and filtering later.
For the vast majority of modern analytical use cases, however, ELT’s combination of fast time-to-data, SQL-native transformations, and historical reprocessing capability makes it the preferred data integration pattern for the modern data lakehouse.