ETL (Extract, Transform, Load)
Before a business analyst can run a query against a data warehouse, someone has to get the data there. For most of the history of enterprise data management, that job belonged to a process called ETL: Extract, Transform, Load. It is one of the oldest and most battle-tested patterns in data engineering, and despite the rise of more modern alternatives like ELT, it remains relevant in specific architectural contexts.
ETL describes a three-stage pipeline. First, data is extracted from one or more source systems. Second, it is processed in a dedicated transformation engine that applies business rules, cleans it, and shapes it into the required format. Third, only after this transformation is complete is the data loaded into the target system, typically a data warehouse. The key distinction is that the data is structured and cleaned before it lands in the target, not after.
This sequence was not arbitrary. It emerged from the hardware realities of the 1990s and early 2000s. Data warehouse storage was extraordinarily expensive, often running hundreds of dollars per gigabyte. Compute inside the warehouse was limited and shared across all users. Loading raw, unprocessed data directly into the warehouse was not just wasteful; it was actively harmful. It wasted expensive storage on garbage data and consumed shared compute resources to process it. ETL solved this by doing all the expensive processing work in a cheaper, dedicated staging environment before placing only the clean, final data into the warehouse.
Stage 1: Extract
The extraction stage is responsible for connecting to source systems and pulling the data that needs to be moved. These sources are typically heterogeneous: a mix of relational databases running Oracle or PostgreSQL, ERP systems, CRM platforms, mainframe flat files, and legacy XML feeds from third-party partners.
Two primary extraction strategies exist. Full extraction pulls the entire dataset from the source system on every run. This is simple to implement but extremely expensive at scale. If the source table has one billion rows and only ten thousand changed since yesterday, a full extraction wastes enormous resources reading and processing 999,990,000 rows of unchanged data.
Incremental extraction addresses this by pulling only the data that has changed since the last extraction run. To identify changed records, ETL tools rely on one of several mechanisms. Timestamp-based extraction queries for records where an updated_at column is newer than the last run’s timestamp. Log-based Change Data Capture (CDC) reads the database’s transaction log to identify exactly which rows were inserted, updated, or deleted without querying the source tables at all, which has minimal impact on source system performance.
Stage 2: Transform
The transformation stage is the intellectual heart of an ETL pipeline. This is where raw data becomes trustworthy, business-ready information. Transformations are executed in a dedicated compute environment, historically a standalone ETL server running software like Informatica PowerCenter, IBM DataStage, or Microsoft SSIS. Modern cloud-based ETL platforms include AWS Glue, Azure Data Factory, and Google Dataflow.
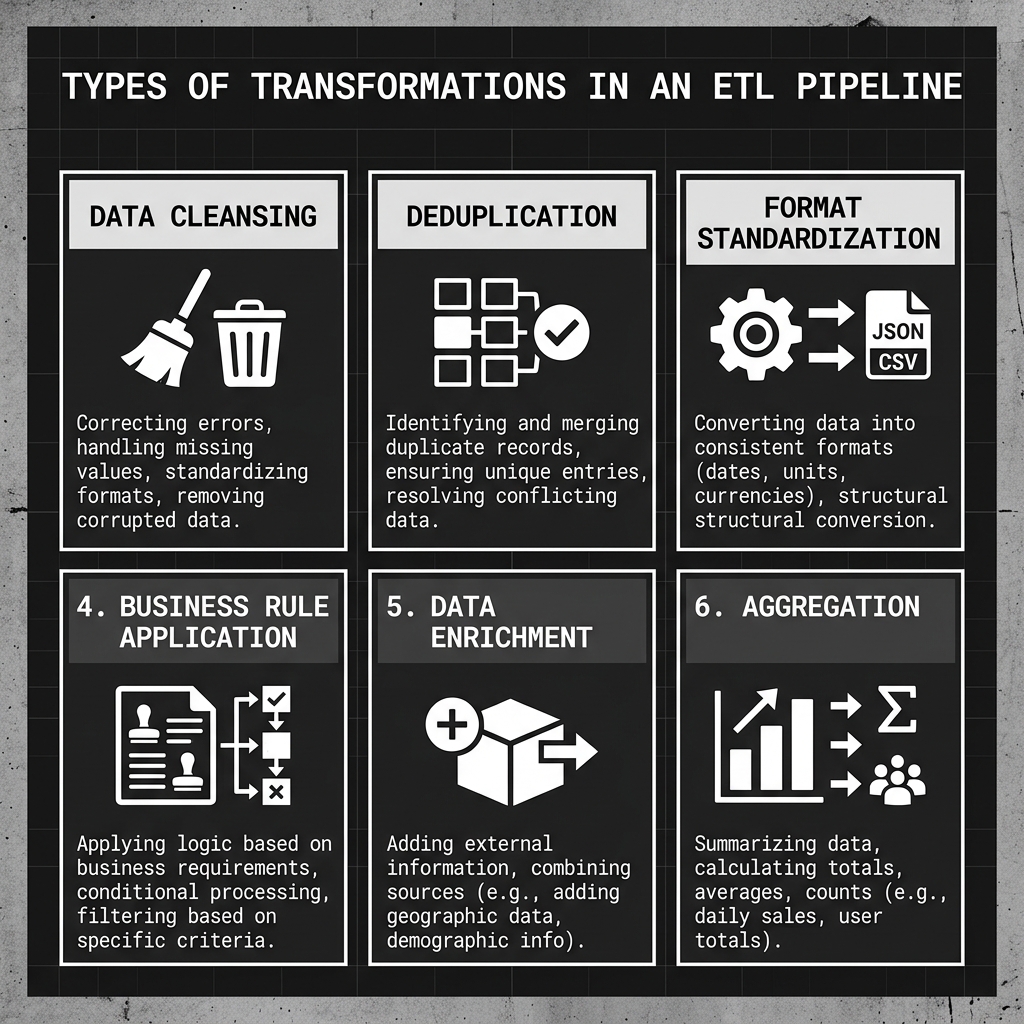
Data Cleansing corrects obvious errors in the source data. Null values in required fields are either filled with default values or cause the record to be rejected. Strings that should be numeric are either converted or flagged. Phone numbers are normalized to a consistent format. Dates from different source systems (some using MM/DD/YYYY, others using YYYY-MM-DD) are standardized into a single ISO 8601 format.
Deduplication identifies and resolves duplicate records that appear multiple times across different source systems. A customer may exist in both the CRM and the billing system with slightly different spellings of their name. Entity resolution logic matches these records and merges them into a single golden record.
Business Rule Application is where domain-specific logic is applied. “Revenue” is calculated according to the finance department’s approved definition. Customer segments are assigned based on spending tiers. Outlier orders above a certain value are flagged for manual review. This logic is the institutional knowledge of the organization, codified into the pipeline.
Diagram 1: ETL Architecture
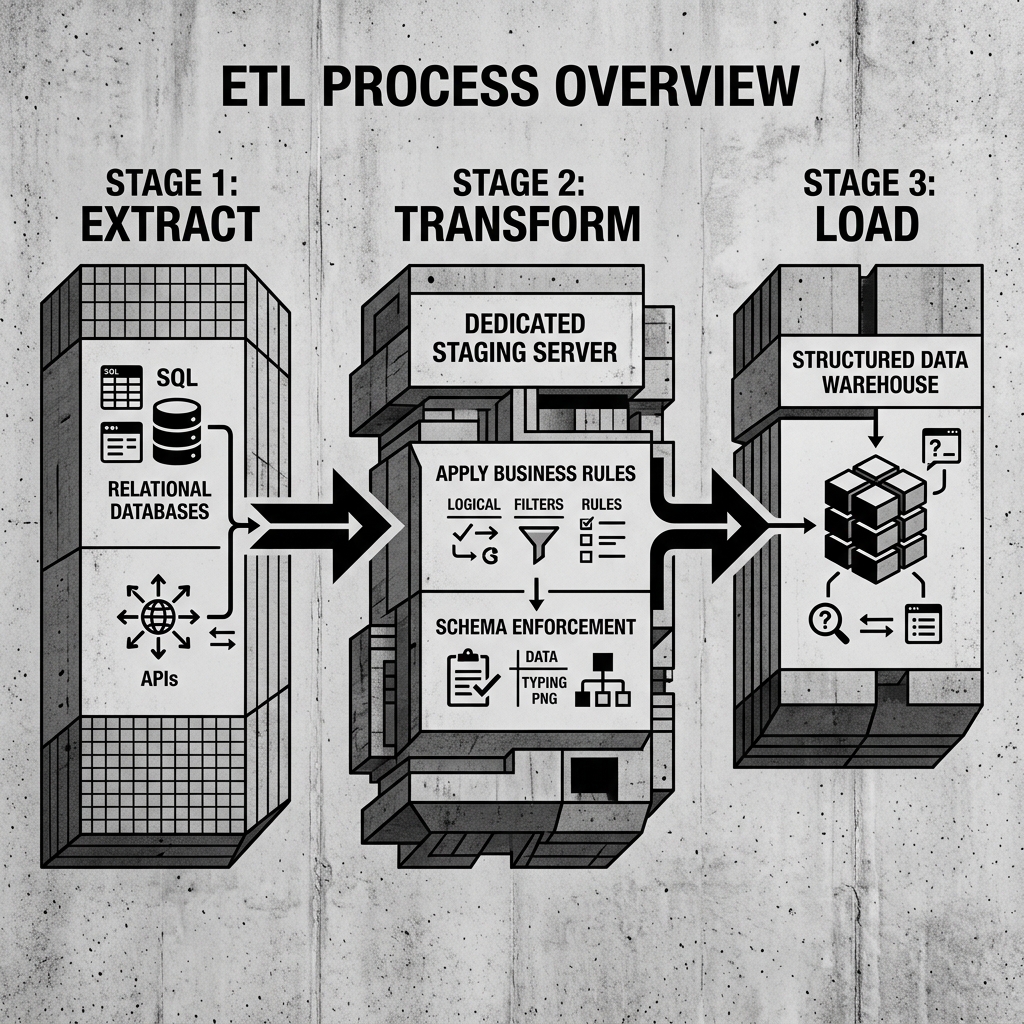
Stage 3: Load
After transformation, the clean, structured data is loaded into the target data warehouse. The loading strategy depends on the use case.
Full load replaces the entire contents of the target table with the new data. This is simple but slow and disruptive for large tables.
Incremental load (append) adds only the new records to the target table without touching existing records. This is fast but requires the source data to accurately identify net-new records.
Upsert (merge) inserts new records and updates existing ones where a matching key is found. This is the most common strategy for dimension tables in a star schema, where business entities like customers or products are updated over time rather than replaced wholesale.
Diagram 2: Types of Transformations
ETL vs. ELT: When ETL Is Still the Right Choice
Despite the industry’s broad shift toward ELT with cloud-native warehouses and data lakehouses, ETL remains the appropriate choice in specific scenarios.
Sensitive data handling: If source data contains personally identifiable information (PII) that must never touch the target storage environment in raw form, ETL’s pre-load transformation provides a natural enforcement point. Masking or encrypting sensitive fields in the transformation stage before loading prevents a compliance exposure that would occur if raw PII were landed in a data lake first.
Legacy target systems: Many organizations still run on-premises data warehouses with rigid schemas and limited storage. These systems cannot accommodate raw, unprocessed data and require clean, formatted inserts. ETL is the only viable approach for feeding these systems.
High-volume filtering: Some use cases require aggressive filtering at the extraction stage. A high-frequency IoT stream might generate a billion events per day, of which only one thousand are anomalies requiring analysis. Loading all one billion events into the lakehouse and filtering later wastes storage and compute. Filtering during the transformation stage is far more efficient.
Regulatory audit requirements: Certain regulated industries require that audit logs of every data transformation be maintained in a specific format. Dedicated ETL platforms often provide built-in, tamper-proof transformation logging that satisfies these requirements more readily than a custom dbt transformation in a lakehouse.
As cloud economics continue to make storage and compute cheaper, the use cases where ETL’s pre-transformation approach is superior will continue to narrow. But for organizations operating in the scenarios described above, ETL remains not just viable but necessary.