Eventual Consistency
Eventual Consistency
In any discussion of data reliability in distributed systems, the conversation inevitably polarizes around two competing consistency models: ACID (Atomicity, Consistency, Isolation, Durability) on one end, representing the gold standard of transactional correctness, and Eventual Consistency on the other, representing the pragmatic acknowledgment that perfect, immediate global consistency is provably impossible in distributed systems without paying an unacceptable cost in availability and latency.
Data engineers working in the modern lakehouse ecosystem need to understand Eventual Consistency not as a failure to achieve ACID guarantees, but as a deliberate, rational architectural choice that governs how multiple components in a distributed data system relate to each other over time. Eventual Consistency is not a weakness — it is the correct consistency model for a large class of real-world data engineering problems. Choosing it deliberately, understanding its implications, and designing systems that account for its properties is the mark of engineering maturity.
The Theoretical Foundation: The CAP Theorem
The conceptual framework that makes Eventual Consistency inevitable in distributed systems is the CAP Theorem, formulated by computer scientist Eric Brewer in 2000 and formally proved by Seth Gilbert and Nancy Lynch in 2002.
The CAP Theorem states that any distributed data system can guarantee at most two of the following three properties simultaneously:
Consistency (C): Every read receives the most recently written value or an error. All nodes in the distributed system see the same data at the same time. This is essentially the same consistency requirement as the “C” in ACID, but applied to the full distributed system.
Availability (A): Every request to the system receives a response (not an error), though that response may not contain the most recently written value. The system is always willing to serve a result.
Partition Tolerance (P): The system continues to operate correctly even when arbitrary network failures cause some nodes to be unable to communicate with others.
The critical insight of the CAP Theorem is that Partition Tolerance is not optional in any real-world distributed system. Networks fail. Routers drop packets. Data centers lose connectivity. Any system deployed on the open internet or across cloud availability zones must be designed to tolerate network partitions. P is a non-negotiable constraint.
This means the real trade-off for distributed system designers is always: CP (Consistency + Partition Tolerance, at the cost of availability during partitions) or AP (Availability + Partition Tolerance, at the cost of consistency during partitions).
CP Systems
A CP system prioritizes consistency. During a network partition, rather than serve potentially stale data from isolated nodes, a CP system stops accepting requests from nodes that cannot verify they have the latest data. This guarantees that every response reflects the true, globally consistent state — but some users or services will receive errors or timeouts during the partition event.
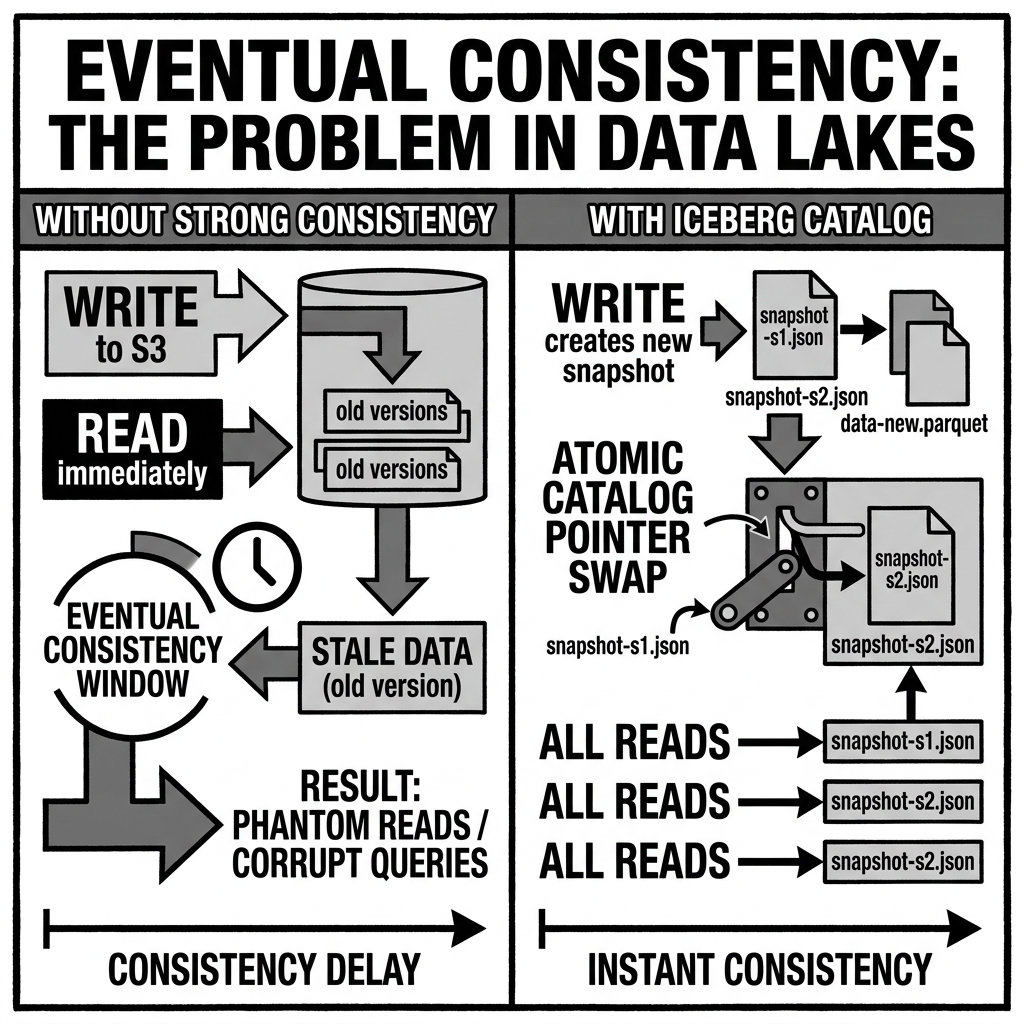
Traditional relational databases (PostgreSQL, MySQL in synchronous replication mode) are classic CP systems. Iceberg’s commit protocol, which performs a compare-and-swap against a central catalog before completing a transaction, exhibits CP behavior: a writer that cannot reach the catalog cannot commit, even if it could write data files to local or regional storage.
AP Systems
An AP system prioritizes availability. During a network partition, the isolated nodes continue serving requests using whatever data they have locally available, accepting the possibility that some responses may be stale or inconsistent with responses from other isolated nodes. Once the partition heals, the nodes reconcile their state — they converge to eventual consistency.
Amazon DynamoDB in its default configuration, Apache Cassandra, and CouchDB are classic AP systems. In the data lakehouse context, the eventual consistency we observe when using metadata translation tools like Apache XTable is AP behavior: the target format’s metadata is always available and readable, but it may lag slightly behind the source format’s most recent committed state.
The BASE Properties: The Practical Alternative to ACID
For distributed systems that must prioritize high availability and horizontal scalability over strict, immediate consistency, the BASE model provides a practical alternative to ACID.
BASE stands for:
Basically Available: The system guarantees availability, meaning it will always respond to requests. During network partitions or node failures, some parts of the system may be degraded or serve stale data, but the system as a whole does not go dark. This is the availability property of the AP design.
Soft State: The state of the system may change over time without any new input, due to asynchronous replication and reconciliation processes running in the background. This is a more honest acknowledgment than ACID’s implicit assumption that state changes only happen as a result of explicit transactions. In a BASE system, the background reconciliation processes are part of the normal operational model, not an exception condition.
Eventual Consistency: Given sufficient time without new updates, all replicas of a given data element will converge to the same value. The system does not guarantee that every node sees the same value at every instant. It guarantees only that they will all eventually agree.
The key word in Eventual Consistency is “eventually.” It provides no bound on how long the convergence will take. In a well-engineered system, convergence might take milliseconds to seconds. In a poorly engineered or heavily loaded system, it might take minutes or hours. In a pathological case with a persistent partition or a bug in the reconciliation logic, it might never converge. The guarantee is theoretical; the practical convergence window must be measured and monitored.
Eventual Consistency in the Data Lakehouse Ecosystem
Eventual Consistency appears in multiple distinct contexts in the modern data lakehouse, each with its own specific characteristics and implications.
1. Object Storage Replication
All major cloud object storage providers (Amazon S3, Google Cloud Storage, Azure Blob Storage) provide strong read-after-write consistency for newly written objects: after a successful PUT, any subsequent GET for the same key will return the newly written object. However, for cross-region replication (where data is automatically replicated from a primary region to one or more secondary regions for disaster recovery or latency optimization), consistency is eventual.
If you write a Parquet file to S3 in us-east-1 and have replication configured to eu-west-1, a reader in eu-west-1 may not immediately see the newly written file. S3 replication has a typical replication time of under one second for most objects, but it provides no hard real-time guarantee. The data will eventually be present in eu-west-1 — but a query executed at exactly the right millisecond may encounter a replication lag.
For lakehouse architectures that serve analytical queries from replicated secondary regions, this replication lag introduces subtle eventual consistency behavior. A reader in eu-west-1 may see a table in a state that is slightly behind the current state visible from us-east-1. This is typically acceptable for analytical workloads where data is hours old by the time it is being queried, but it is a meaningful concern for near-real-time operational reporting.
2. Metadata Translation Lag (XTable)
As described in the Apache XTable and Metadata Translation articles, tools that asynchronously translate metadata between Open Table Formats introduce an explicit eventual consistency window between the source format’s committed state and the target format’s reflected state.
If Hudi commits a new batch of records at 14:00:00 and XTable runs its next incremental sync at 14:02:00, any Iceberg reader accessing the translated table during that two-minute window is reading the state as of the last XTable sync, not the current Hudi state. The Iceberg view of the table is eventually consistent with the Hudi view — it will catch up when XTable runs — but it is never guaranteed to be instantaneously consistent.
The practical implications for data users are significant and must be communicated clearly:
- Downstream Iceberg-native BI tools may show data that is one to five minutes old relative to the source system.
- If a SLA requires data to be visible within 60 seconds of being committed to the source table, XTable’s default sync cadence may violate that SLA.
- Monitoring XTable sync lag as a first-class SLI (Service Level Indicator) is a production operational requirement, not an optional nice-to-have.
3. Delta UniForm Lag
Delta UniForm, while architecturally tighter than XTable (it runs on the same compute resource as the Delta write), also introduces eventual consistency between the Delta committed state and the Iceberg metadata state. The asynchronous post-commit Iceberg metadata generation means there is a window (typically seconds) after a Delta commit where the corresponding Iceberg metadata has not yet been written.
For most use cases, this is a negligible concern. For edge cases where an application reads from the Iceberg interface immediately after writing through the Delta interface, the application must account for the possibility of not seeing the very latest Delta commit in the Iceberg view.
4. Medallion Architecture Layer Latency
The Medallion Architecture (Bronze → Silver → Gold) is inherently an eventually consistent system across layers. Bronze ingests raw streaming data continuously. A Spark batch job runs every 15 minutes to transform and load Silver from Bronze. A second Spark job runs every hour to aggregate and load Gold from Silver.
At any given moment, the Gold layer reflects the state of Silver from the last hour’s batch run, which reflects the state of Bronze from the last 15-minute run, which reflects the event stream from up to 15 minutes ago. An analyst querying Gold is seeing the world through an eventually consistent lens that lags by up to 75 minutes. This is entirely by design — the batch processing windows are a deliberate engineering choice to amortize transformation costs.
The implication for users consuming Gold layer data is that it is not live data; it is recent data, with a well-defined and operationally managed staleness bound. Communicating this staleness bound clearly to business users — through dashboard headers, data freshness indicators, or SLA documentation — is a data engineering responsibility that is as important as the pipeline engineering itself.
5. Catalog Propagation Delays
In highly distributed lakehouse deployments with multiple catalog instances or cached catalog states, there can be brief windows where a newly committed table update is not yet visible in all catalog replicas or client-side caches.
Apache Polaris (the open-source Iceberg REST Catalog) uses a distributed architecture where catalog state changes may take a few milliseconds to propagate across all service replicas. During this window, two concurrent readers consulting different Polaris replicas may receive slightly different views of which tables exist or what the current table version is.
This is a well-understood characteristic of distributed database systems. Catalog services mitigate this through strong consistency mechanisms (e.g., using a strongly consistent backing store like Postgres or DynamoDB), client-side cache invalidation strategies, and operational monitoring for propagation lag. But in any geographically distributed deployment, some degree of catalog propagation delay is physically unavoidable due to the speed of light.
Designing Systems That Account for Eventual Consistency
The key principle for engineers working with eventually consistent systems is to design applications that are correct under the assumption of stale reads, rather than assuming that reads will always return the latest committed data.
Idempotency
In an eventually consistent system, retries are common — a writer that cannot confirm a commit due to a network partition may retry the same write operation multiple times. If those writes are not idempotent (i.e., executing the same write twice produces different results than executing it once), retries will corrupt the data.
Open Table Formats address this through their atomic commit protocols: even if a writer retries a commit multiple times, only one commit attempt can succeed (because the atomic commit is conditional on the current version). All other retry attempts are rejected. The writer’s physical file writes may produce orphan files (which the removeOrphanFiles job will clean up), but the logical table state is never corrupted by retry behavior.
Monotonic Reads
In an eventually consistent system, a client that reads from multiple replicas might observe “backwards” data: reading a table’s current state from Replica A (which is up-to-date), then reading from Replica B (which is lagging), and seeing a version of the table that is older than what they already saw from Replica A.
This violation of the intuitive expectation that “time moves forward” can cause subtle bugs in applications that depend on a monotonically increasing view of the data. Designing lakehouse applications with session-level consistency (where all reads in a session are served from the same catalog replica) or by pinning reads to specific snapshot IDs prevents this class of consistency anomaly.
Bounded Staleness Monitoring
For any lakehouse component that exhibits eventual consistency (XTable sync, Delta UniForm lag, Medallion layer latency), the staleness window should be measured and treated as a first-class operational SLI with defined SLOs (Service Level Objectives).
A team might define: “The Gold layer must reflect events from no more than 90 minutes ago.” If the staleness monitoring detects that Gold is 95 minutes stale, an alert fires and the on-call engineer investigates why the batch pipeline is lagging. This converts the abstract guarantee of “eventual consistency” into a concrete, operationally managed freshness SLO.
Eventual Consistency vs. ACID: Choosing Correctly
The decision between ACID transactional guarantees and eventual consistency is not a value judgment about which is “better.” It is a precise engineering trade-off that must match the specific requirements of the workload.
ACID is the correct choice when: correctness requires immediate, global consistency; business consequences of a stale read are severe (financial fraud, inventory oversell); write throughput is moderate; and the cost of coordination is acceptable.
Eventual Consistency is the correct choice when: the business can tolerate a defined staleness window; massive write throughput or geographic distribution makes global coordination prohibitively expensive; the workload is analytical rather than transactional; and the engineering team has the discipline to measure and manage the consistency window.
For the vast majority of data lakehouse analytical workloads — dashboards, machine learning training pipelines, data science exploration, compliance reporting — eventual consistency with well-managed staleness bounds is entirely appropriate and delivers dramatically better performance and scalability than strict, globally synchronous ACID transactions would allow.
Conclusion
Eventual Consistency is not a compromise or a failure mode. It is the correct, mathematically justified consistency model for a large and important class of distributed data engineering problems. The CAP Theorem makes it provably impossible to achieve perfect global consistency, perfect availability, and partition tolerance simultaneously. Engineers who understand this constraint — and who design their lakehouse architectures, pipelines, and user experiences around clearly defined and operationally managed staleness bounds — build systems that are simultaneously more scalable, more available, and more honest with their users than systems that pretend to offer ACID guarantees they cannot actually deliver at distributed scale.
Visual Architecture