File Format
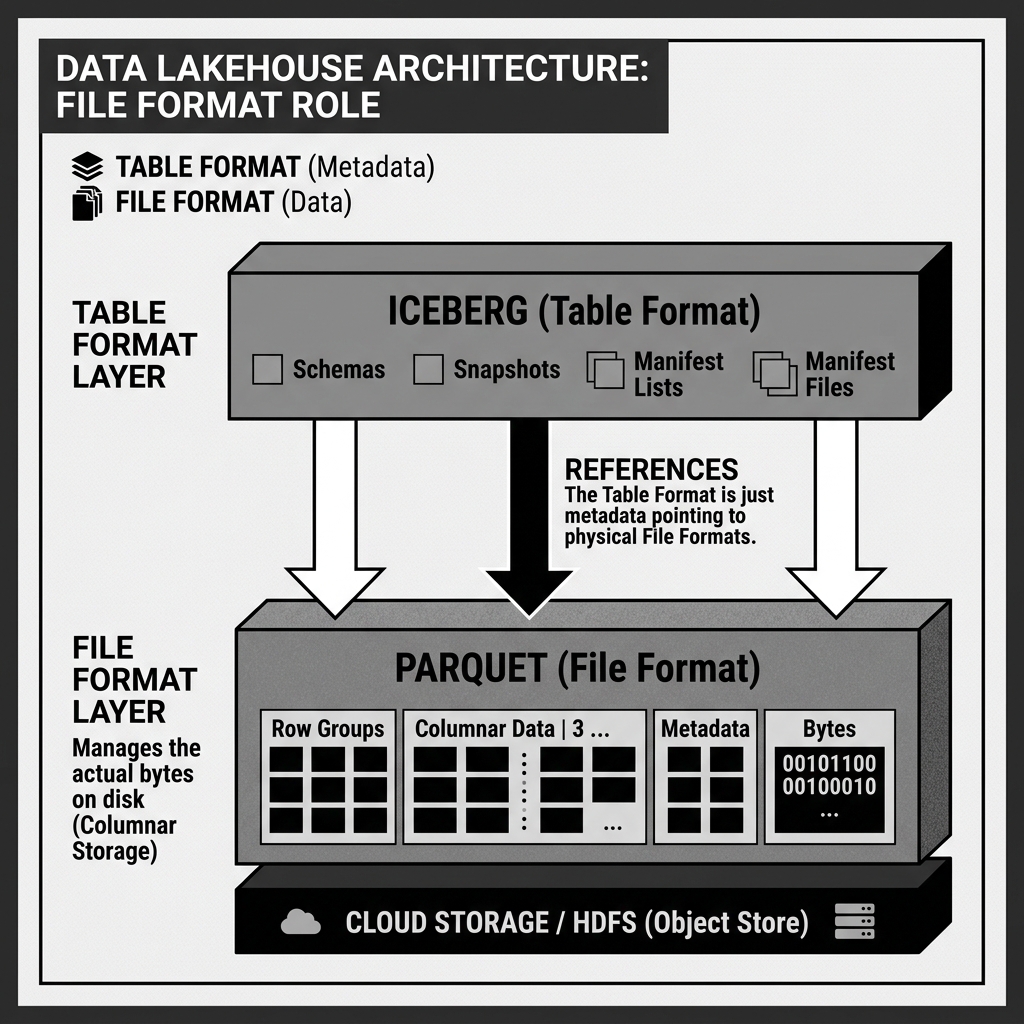
In the architecture of a modern data lakehouse, there is a strict separation between the Table Format (like Apache Iceberg or Delta Lake) and the File Format (like Apache Parquet or ORC).
The Table Format is a layer of metadata. It tracks schemas, manages transactions, and tells the query engine which files belong to the current version of the table. However, the Table Format does not actually hold any of the raw data. The raw data—the billions of rows of customer records, financial transactions, or IoT telemetry—is encoded and stored on disk by the File Format.
Choosing the right file format is one of the most critical decisions in data engineering. A poor choice can lead to skyrocketing cloud storage costs and queries that take hours instead of seconds.
Row-Based vs. Columnar
File formats generally fall into two categories based on how they write data to disk: row-based and columnar.
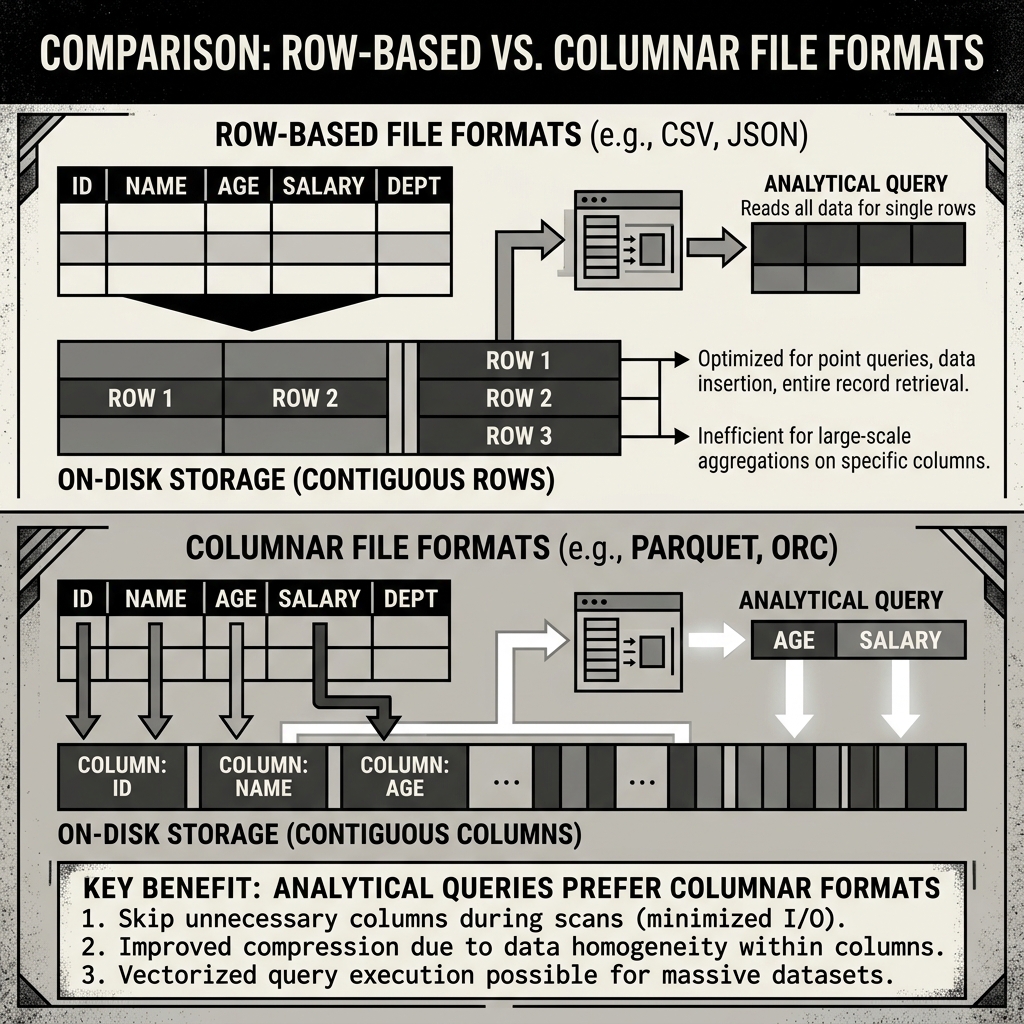
Row-Based Formats (like CSV, JSON, or Avro) write data sequentially by row. If you have a table with ID, Name, and Age, a row-based format writes all the data for Row 1 to disk, then all the data for Row 2, and so on.
This is highly efficient for transactional systems (OLTP) where an application needs to read or write a single, complete record quickly. However, it is disastrous for analytics. If an analyst runs SELECT AVG(Age) FROM users, the engine must read every single byte of the row-based file from disk, scanning past millions of irrelevant names and IDs just to extract the ages.
Columnar Formats (like Parquet or ORC) write data sequentially by column. They group all the IDs together, then all the Names, then all the Ages.
When the analyst runs SELECT AVG(Age) FROM users, the query engine simply skips to the exact byte offset where the “Age” column is stored. It reads only that specific block of data, entirely ignoring the rest of the file. This process, known as “projection pushdown,” drastically reduces disk I/O, which is the primary bottleneck in big data processing.
Diagram 1: Row-Based vs. Columnar Storage
Compression Efficiency
Beyond query performance, columnar file formats offer a massive advantage in storage efficiency due to how compression algorithms work.
Compression algorithms look for patterns and repetitions in data. In a row-based format, data is heterogeneous; a string (Name) is followed by an integer (Age), followed by a boolean (Is_Active). This lack of uniformity makes compression difficult.
In a columnar format, data is homogeneous. An entire block of disk space contains nothing but integers, or nothing but booleans. If a column tracks user status (Active or Inactive), a columnar format doesn’t need to write the word “Active” a million times. It can use Run-Length Encoding (RLE) to simply record “The value ‘Active’ repeats 1,000,000 times.”
This allows columnar file formats to achieve extreme compression ratios, significantly lowering the cost of storing petabytes of data in cloud object storage like Amazon S3.
Diagram 2: File Format in the Lakehouse
The Standard: Apache Parquet
While several columnar formats exist, Apache Parquet has emerged as the undisputed standard for the modern data lakehouse. It is heavily optimized for complex nested data structures and provides extensive support for predicate pushdown (allowing the file itself to filter out data before sending it to the query engine).
When you build an Apache Iceberg table, Iceberg is the metadata brain managing the transactions, but under the hood, it is almost certainly writing the physical bytes to disk using the Apache Parquet file format.