Format Interoperability
The promise of the Open Data Lakehouse is simple to state and brutally difficult to execute: store data once, on cheap cloud object storage, and make it universally accessible to any compute engine, regardless of vendor or technology preference. Apache Iceberg, Delta Lake, Apache Hudi, and Apache Paimon each represent an attempt to fulfill that promise. Yet each format’s very existence creates a new dimension of the problem they collectively were meant to solve: if every table format is “open” in isolation but incompatible with the others, the ecosystem devolves into isolated silos that are merely cheaper than the proprietary data warehouse silos they replaced.
Format Interoperability is the engineering discipline of solving the cross-format compatibility problem. It encompasses the technical mechanisms, standards, and tools that allow data written in one Open Table Format to be reliably, consistently, and performantly read by engines natively designed for a different format. This guide provides an exhaustive, technical analysis of why interoperability is hard, what specific failure modes it introduces, and precisely how the ecosystem is addressing those failures through converging standards and translation layers.
Why Interoperability Is Not Automatic: The Metadata Fragmentation Problem
A common misconception about the Open Table Format ecosystem is that because all formats store their data in Parquet files, they are inherently interoperable. This is true at the data layer but completely false at the metadata layer, and the metadata layer is precisely where the intelligence of the table lives.
Structurally Incompatible Metadata Systems
Consider a simple Parquet file: data/year=2026/month=05/file_001.parquet. This file is 100% readable by any Parquet reader. But knowing that this file exists, knowing that it belongs to the table, knowing its min/max column statistics, knowing it was committed in transaction 47 and should be visible to readers of snapshot 48 but not snapshot 46 — all of this knowledge lives exclusively in the metadata layer. And each format implements this metadata layer in a completely incompatible way:
Apache Iceberg tracks files through a hierarchical tree: a JSON metadata file, pointing to an Avro Manifest List, which lists multiple Avro Manifest Files, each of which tracks individual data files with their column statistics and partition values.
Delta Lake tracks files through a flat, chronological transaction log: an ordered sequence of JSON files, each recording add and remove actions for individual Parquet files, with embedded column statistics in each add entry.
Apache Hudi tracks files through a Timeline of Instant entries in the .hoodie/ directory, combined with an internal Metadata Table that tracks file groups, bloom filters, and record-level indexes.
An Iceberg-native query engine (like Trino using its native Iceberg connector) has no ability to parse a Delta _delta_log/, and no ability to navigate a Hudi Timeline. From the Iceberg engine’s perspective, a Delta table’s storage bucket contains only a collection of unidentifiable Parquet files and an unrecognizable _delta_log/ directory. The table simply does not exist.
This is the core of the metadata fragmentation problem: the same physical data, expressed through different metadata systems, is completely invisible to engines designed for a different format.
The Catalog Silo Problem
The metadata fragmentation problem is compounded by the Catalog Silo problem. Even if a query engine could somehow read multiple table formats, it still needs to know where to find the tables. Tables are registered in Catalogs — services that map logical table names (e.g., analytics.sales.orders) to physical metadata locations (e.g., s3://data-lake/tables/orders/metadata/).
Historically, each table format either used its own proprietary catalog or relied on the Hive Metastore (HMS) with format-specific conventions. A Databricks Unity Catalog knows about Delta Lake tables. A Dremio Arctic catalog knows about Iceberg tables. AWS Glue Data Catalog stores tables in a format that both Iceberg and Delta engines can partially access, with significant caveats.
The result is an enterprise data landscape where different teams, using different engines, have registered the same (or overlapping) datasets in different catalogs with different format representations. A data governance team attempting to audit what data exists, who can access it, and where it physically lives faces a cataloging nightmare spanning multiple incompatible metadata systems.
The Principal Interoperability Failure Modes
Understanding interoperability failures requires knowing precisely what breaks when it does.
Split-Brain Metadata State
A split-brain scenario occurs when two independent processes both believe they have an authoritative view of the table’s current state, but those views are contradictory. In a multi-format environment, this typically happens when an XTable synchronization lag causes the Iceberg metadata to describe a state that is inconsistent with the current Delta or Hudi state.
For example: a Delta write commits 10 new files at 14:00:00. XTable’s sync runs at 14:02:00 and generates Iceberg metadata for those 10 files. A subsequent Delta compaction runs at 14:01:30 and removes those 10 files, replacing them with 3 merged files. XTable’s next sync at 14:04:00 generates Iceberg metadata pointing to the 3 merged files. However, between 14:02:00 and 14:04:00, the Iceberg metadata points to 10 files that Delta has already logically deleted. An Iceberg reader querying during that window will attempt to read files that Delta has removed from its active state. If those physical files have not yet been garbage-collected by VACUUM, the read will succeed but may return duplicate or outdated rows. If they have been garbage-collected, the read will fail with a file-not-found error.
This is the most dangerous failure mode in multi-format environments.
Type System Incompatibilities
The three major Open Table Formats have largely similar but not identical type systems. Implicit type conversions between formats can produce silent data corruption or query failures.
Critical divergences include:
Timestamp handling: Iceberg distinguishes between timestamp (without timezone, stored as microseconds since epoch) and timestamptz (with timezone, always UTC). Delta Lake’s TIMESTAMP is stored as microseconds since epoch but does not carry explicit timezone information in the same way. When an Iceberg reader reads a Delta-origin timestamp via UniForm or XTable, the timezone interpretation must be handled explicitly to avoid off-by-hours data errors.
Integer precision: Iceberg has distinct int (32-bit) and long (64-bit) types. Delta Lake has INTEGER (32-bit) and LONG (64-bit). These map cleanly. However, Delta’s SHORT and BYTE types both map to Iceberg’s int, losing the precision annotation. This is typically benign for data integrity but can confuse schema comparison tools.
Decimal precision/scale: Both formats support arbitrary-precision decimals with explicit precision and scale, and these map cleanly. However, engines reading Decimal columns through format translation layers must validate that both the precision and scale are preserved exactly — even a one-digit difference in precision can cause a query engine to silently truncate values.
Complex nested types: STRUCT, ARRAY, and MAP types have corresponding representations in all formats, but the metadata encoding of nested field IDs differs between Iceberg and Delta. Iceberg assigns immutable integer IDs to every nested field. Delta does not. Format translation layers must construct synthetic Iceberg field IDs for Delta nested fields, and these synthetic IDs must be stable across translation runs to ensure that a renamed nested field doesn’t appear to be a dropped-and-readded field.
Engine Feature Gaps
Not all engines that claim support for a given Open Table Format support all features of that format. A production interoperability failure is often not a format incompatibility at the specification level but rather a feature gap in a specific engine’s connector.
Common engine feature gaps include:
Deletion Vector support: Not all Delta Lake readers support Deletion Vectors (the Merge-on-Read mechanism). An engine that reads a Deletion-Vector-enabled Delta table without implementing the Deletion Vector filter will read logically deleted rows as if they are active, returning incorrect results without any error.
V2 format features: Iceberg V2 introduced position deletes, equality deletes, and sequence numbers. Not all Iceberg readers have been updated to handle these V2 constructs correctly. An Iceberg V1 reader attempting to read a V2 table that uses position deletes will either fail or silently return deleted rows.
Partition evolution: Iceberg’s partition evolution allows different data files in the same table to have been written under different partition specs. Not all Iceberg readers handle this correctly, particularly when querying across the boundary of a partition spec change.
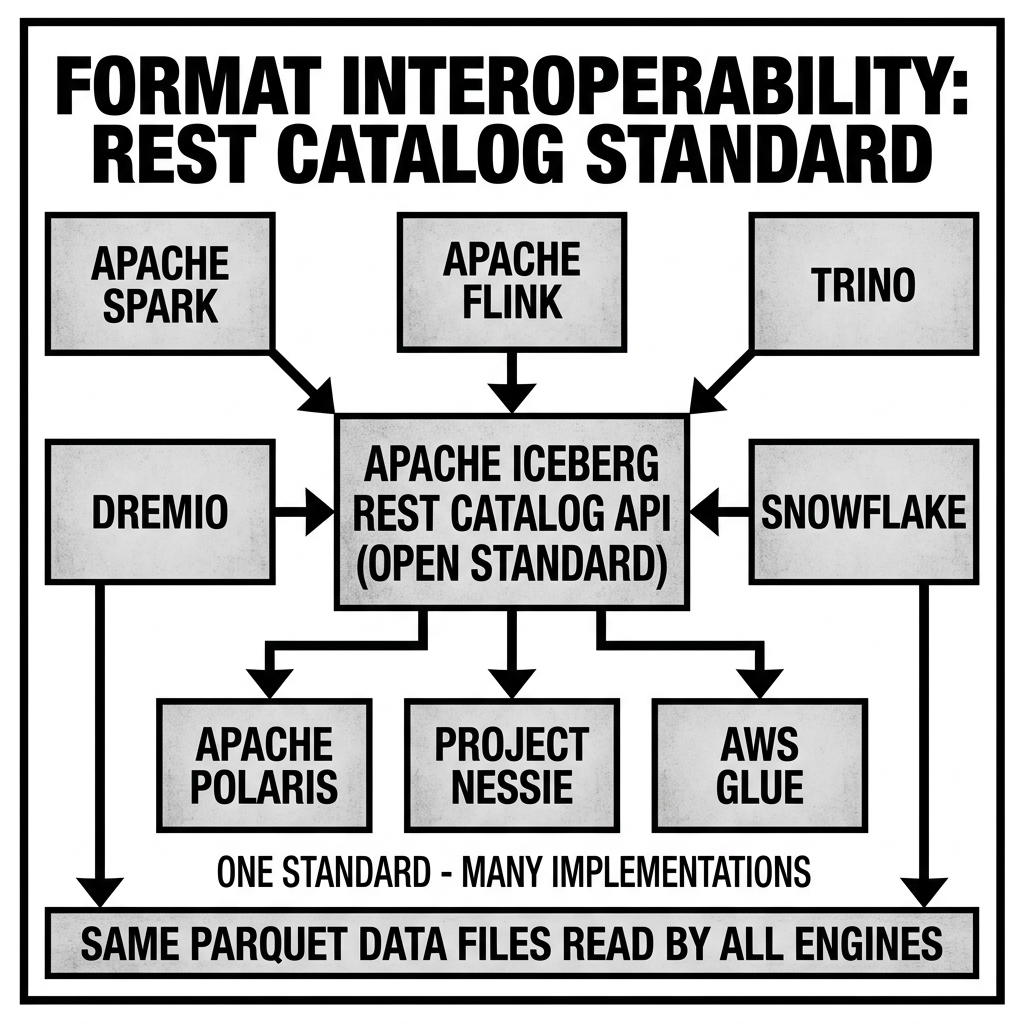
The REST Catalog Specification: The Standardization Solution
The most powerful architectural solution to the Catalog Silo problem is the Iceberg REST Catalog Specification (also known as the Iceberg REST API or IRC). Originally developed as part of the Apache Iceberg project, the REST Catalog spec has evolved into a de facto universal protocol for catalog interactions across the lakehouse ecosystem.
What the REST Catalog Standardizes
The REST Catalog defines a complete HTTP API for catalog operations:
Table Discovery: Listing namespaces and tables within a catalog via standard HTTP GET requests. Any engine that implements the REST client can discover tables in any compliant catalog without engine-specific connector code.
Metadata Loading: Fetching the current table metadata (schema, partition spec, snapshot reference) via a standard REST endpoint that returns a well-defined JSON document, regardless of the underlying metadata format.
Atomic Commit Protocol: The REST Catalog spec defines a server-side atomic commit protocol. When a writer wants to commit a new table state, it sends a POST request to the catalog service containing the proposed metadata update and a set of expected preconditions (e.g., “the current snapshot ID is X”). The catalog service performs the compare-and-swap atomically, either succeeding or returning a 409 Conflict if another writer has already committed. This server-side concurrency control is significantly more reliable than client-side OCC for distributed environments.
Credential Vending: The REST Catalog spec defines an endpoint for dynamic credential generation. Rather than requiring query engines to have standing credentials to access all data files directly, the catalog can issue short-lived, scoped credentials for specific table reads. This enables fine-grained access control at the table and even partition level.
The REST Catalog as Format Bridge
The REST Catalog’s most important interoperability implication is that it separates the catalog interaction protocol from the underlying table format implementation. A catalog service implementing the REST spec can serve Iceberg metadata for tables stored in any format — not just native Iceberg tables, but also Delta UniForm tables or XTable-synchronized Hudi tables.
From the perspective of a Trino cluster using the REST Catalog connector, every table looks like an Iceberg table. The physical format that originally created the data is completely hidden behind the catalog’s REST API. Trino sends a standard REST request, the catalog service returns standard Iceberg metadata, and Trino reads the underlying Parquet files as it would any other Iceberg table. The catalog service is the format translation layer, not the query engine.
Projects like Apache Polaris are specifically designed to implement the REST Catalog spec as a production-grade, governance-capable catalog service, providing a neutral, vendor-agnostic home for multi-format lakehouse tables.
The Interoperability Stack: A Practical Architecture
A robust multi-format lakehouse interoperability architecture typically comprises three layers:
Layer 1 — The Write Format: The authoritative format, chosen for write-path performance and compatibility with the primary write engine. Delta Lake for Databricks-primary organizations, Iceberg for Trino/Dremio-primary organizations, Hudi for Flink/streaming-primary organizations.
Layer 2 — The Format Bridge: The mechanism that makes the write format readable by engines native to other formats. Either Delta UniForm (Delta-to-Iceberg, inline), Apache XTable (any-to-any, async), or direct Iceberg writing (eliminating the problem entirely).
Layer 3 — The Catalog: A unified catalog service implementing the REST Catalog spec (e.g., Apache Polaris, Snowflake Open Catalog, or AWS Glue with Iceberg support) that surfaces all tables as Iceberg tables through a standardized API, providing uniform discovery, governance, and credential vending regardless of the underlying physical format.
With this three-layer architecture, an organization can write data with Flink + Hudi, synchronize it to Iceberg metadata with XTable, register it in a Polaris REST Catalog, and serve it to Trino, Dremio, Snowflake, and BigQuery through standard Iceberg connectors — all without any data duplication and with a single governance and access control surface.
The Convergence Trajectory
The industry trajectory is clear: Apache Iceberg is emerging as the universal read format for the lakehouse ecosystem, and the REST Catalog specification is emerging as the universal catalog interaction protocol. Delta UniForm and Apache XTable are both implementation strategies for aligning existing Delta/Hudi write ecosystems with this Iceberg-as-universal-reader reality.
The long-term equilibrium state toward which the industry is converging is: write in whatever format best matches your write engine’s capabilities, translate to Iceberg metadata (inline or async), register in a REST Catalog, and read with any engine through the standard Iceberg REST connector. The format choice for writes becomes an operational decision based on write-path performance requirements, entirely decoupled from the read format that downstream consumers experience.
Conclusion
Format Interoperability is not a solved problem, but it is a problem the industry has recognized clearly and is making rapid, concrete progress on solving. The combination of the REST Catalog specification, Delta UniForm, Apache XTable, and Apache Iceberg’s broad native engine support is assembling into a coherent interoperability stack. Organizations that understand the specific failure modes — split-brain metadata state, type system incompatibilities, engine feature gaps — and architect their pipelines to account for these risks will be positioned to capture the full economic value of the Open Data Lakehouse: write once, store cheaply, compute anywhere.
Visual Architecture