Google BigQuery
Google BigQuery is a fully managed, serverless, enterprise data warehouse that enables scalable analysis over petabytes of data. Developed by Google Cloud, BigQuery is designed to abstract away all infrastructure management, allowing users to focus entirely on analyzing data using standard SQL. While historically functioning as a proprietary, closed data warehouse, BigQuery has significantly expanded its capabilities through BigLake, embracing the open data lakehouse paradigm and allowing its powerful compute engine to query open table formats seamlessly.
Core Definition
BigQuery traces its lineage back to Dremel, a highly scalable, interactive ad-hoc query system developed internally at Google in 2006 to analyze massive datasets (like web logs and spam analysis). Google commercialized Dremel and released it as BigQuery to the public in 2011.
The defining characteristic of BigQuery is its serverless nature. Users do not provision clusters, manage virtual machines, or configure storage. Google dynamically allocates computing resources on demand. When a user executes a SQL query, BigQuery instantly provisions thousands of execution nodes in the background, processes the data in parallel, and returns the result, scaling back to zero when the query completes.
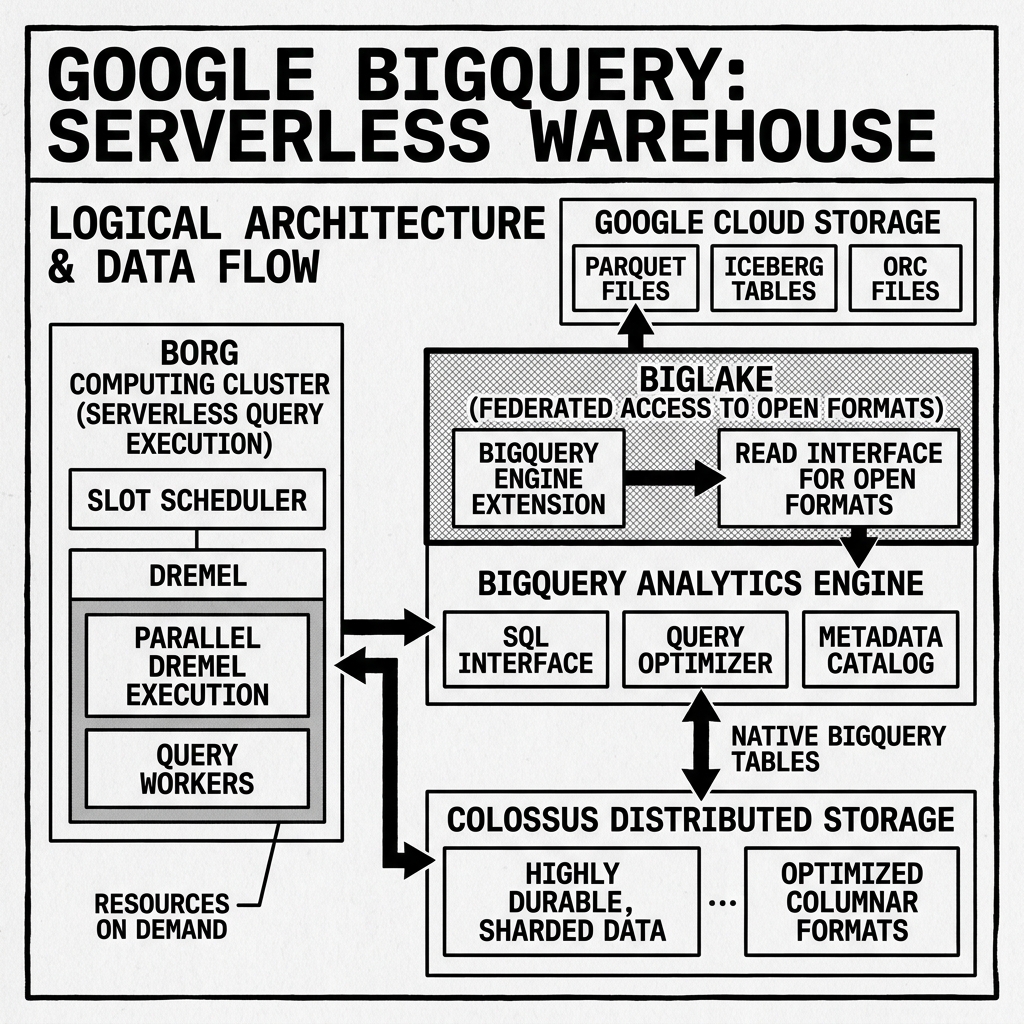
BigQuery utilizes a unique decoupled architecture. The storage layer, known as Colossus (Google’s global file system), is separated from the compute layer, which relies on Google’s Borg cluster management system. Data is stored in a proprietary, heavily optimized columnar format called Capacitor. This separation allows storage and compute to scale independently and infinitely, a pattern that has now become the standard for modern cloud data platforms.
Internal Architecture and Execution
When a query is submitted to BigQuery, it travels through several specialized layers. The query is first received by a routing layer, which passes it to the query engine.
The query engine parses the SQL, generates an execution plan, and optimizes it. The execution plan is represented as a distributed tree of execution stages. BigQuery uses a tree architecture where a root node receives the query and distributes the workload to intermediate “mixer” nodes, which further distribute the work to thousands of “leaf” nodes.
The leaf nodes are responsible for scanning the data from Colossus. They read the highly compressed Capacitor blocks, execute the initial filtering and aggregations, and return the intermediate results up the tree. The mixer nodes aggregate the results from the leaf nodes and pass them back to the root, which delivers the final result to the user.
To facilitate blazing-fast data movement between these nodes during complex joins and shuffles, BigQuery utilizes Jupiter, Google’s incredibly fast petabit-scale internal network. This allows BigQuery to execute massive distributed joins entirely in memory, without spilling to disk, resulting in unprecedented query speeds.
BigLake and the Open Data Lakehouse
For many years, achieving BigQuery’s legendary performance required organizations to ingest all their data directly into BigQuery’s internal Colossus storage and proprietary Capacitor format. This created data lock-in and made interoperability with open-source tools (like Apache Spark) difficult.
To address the rise of the open data lakehouse, Google introduced BigLake. BigLake is a storage engine that unifies data warehouses and data lakes by allowing BigQuery to query data stored in Google Cloud Storage (GCS), Amazon S3, and Azure Blob Storage using open formats.
Through BigLake, BigQuery now natively supports Apache Iceberg, Delta Lake, and Apache Hudi. Users can create external tables in BigQuery that point to Iceberg metadata residing in GCS. When BigQuery executes a query against this external table, it reads the Iceberg manifest files, performs partition pruning, and directly scans the underlying Parquet files.
Crucially, BigLake extends BigQuery’s robust security and governance models (like row-level and column-level security) to these external open formats. This allows organizations to maintain a single source of truth in open formats on cheap object storage, while simultaneously leveraging BigQuery’s world-class execution engine and governance frameworks.
Machine Learning and Advanced Analytics
BigQuery differentiates itself from many traditional query engines by bringing advanced analytics and machine learning directly into the database via BigQuery ML.
Traditionally, training a machine learning model required data scientists to extract massive datasets from the data warehouse, load them into Python environments (like Jupyter notebooks), and train the models using libraries like scikit-learn or TensorFlow. This process was slow, insecure, and often limited by the memory of the data scientist’s machine.
BigQuery ML allows users to create and execute machine learning models using standard SQL queries directly inside BigQuery. A data analyst can write a CREATE MODEL statement, specify the model type (e.g., linear regression, k-means clustering, or deep neural networks), and BigQuery will execute the training process utilizing its massive distributed compute power. This drastically democratizes access to machine learning and eliminates the need for complex data pipelines.
Summary and Tradeoffs
Google BigQuery is an undisputed leader in the cloud data warehousing space. Its zero-ops, serverless architecture, backed by Google’s massive global infrastructure, provides unparalleled scalability and speed. With the introduction of BigLake and support for Apache Iceberg, BigQuery has successfully positioned itself as a premier compute engine for the open data lakehouse.
The primary tradeoff with BigQuery is managing costs in a serverless, pay-per-query environment. BigQuery charges based on the number of bytes processed. Because it can effortlessly scan petabytes of data in seconds, a poorly written query lacking proper partition filters can result in massive, unexpected charges. While Google provides controls like maximum bytes billed limits and flat-rate pricing models, organizations must establish strict governance and monitoring to prevent cost overruns.
Furthermore, while BigLake bridges the gap to open formats, many of BigQuery’s most advanced performance optimizations (like continuous background clustering and materialized views) remain most effective when data is stored in its native internal format. Organizations must carefully balance their desire for vendor-neutral open formats with the absolute peak performance offered by BigQuery’s proprietary storage.
Visual Architecture