Google Cloud Storage (GCS)
Google Cloud Storage (GCS) is a managed, highly scalable object storage service provided by Google Cloud Platform (GCP). It is the GCP equivalent to Amazon S3. Designed to handle massive amounts of unstructured and structured data, GCS provides a unified API, strong consistency guarantees, and seamless integration with Google’s broader ecosystem of data tools, making it the foundational storage layer for any open data lakehouse built on Google Cloud.
Core Characteristics and Architecture
Like all object stores, GCS abandons the traditional hierarchical file system in favor of a flat namespace. Data is stored as objects within “buckets.” Each object consists of the raw data bytes, highly customizable metadata (key-value pairs), and a unique URL identifier.
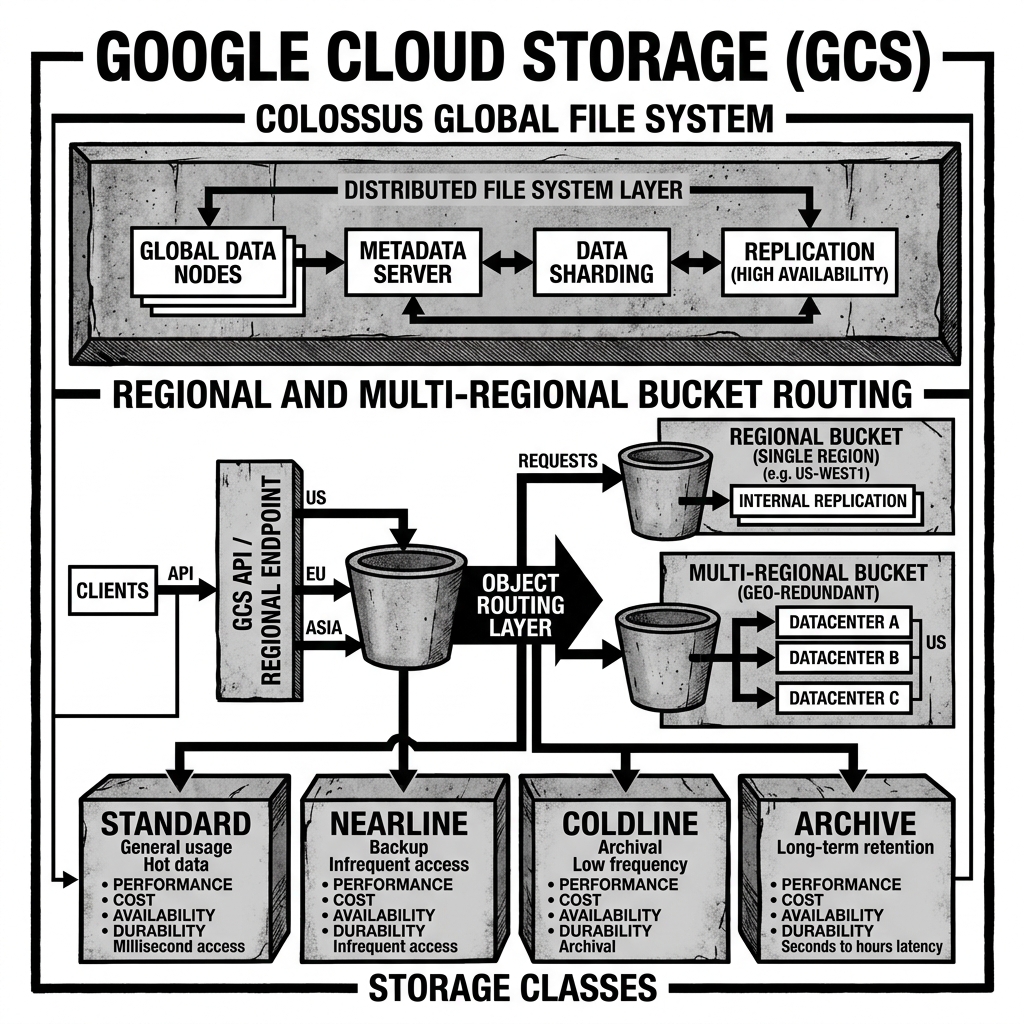
Under the hood, GCS is powered by Colossus, Google’s next-generation global file system (the successor to the original Google File System, GFS). Colossus manages the physical placement, replication, and erasure coding of the data across Google’s massive global network of data centers. This infrastructure allows GCS to effortlessly scale to exabytes of data and handle millions of operations per second without the user ever provisioning a single server or disk.
When building an open data lakehouse on GCP, data engineers write Parquet or ORC files directly to GCS buckets using formats like Apache Iceberg. This data is then instantly available to be queried by Google BigQuery (via BigLake external tables), Dataproc (Google’s managed Spark/Hadoop service), or any external engine capable of authenticating with the GCP APIs.
Strong Consistency
A major historical differentiator for GCS was its early adoption of strong global consistency.
In distributed systems, achieving strong consistency across vast geographic distances is incredibly difficult. For many years, Amazon S3 operated on an “eventual consistency” model. If a user deleted a file and immediately tried to read it, they might still receive the deleted file for a few seconds until the changes propagated across all AWS data centers.
GCS, conversely, provided strong read-after-write and read-after-delete consistency from the beginning. If an application writes an object to GCS and receives a success response, any subsequent read request for that object, from anywhere in the world, is guaranteed to return the new data.
This strong consistency is crucial for big data frameworks. Early versions of Hadoop and Spark required complex, hacky workarounds (like the S3Guard component in AWS) to prevent data corruption when writing complex, multi-stage ETL pipelines over eventually consistent object storage. GCS avoided these issues entirely, making it a highly reliable backend for data engineering workloads. (Note: Amazon S3 eventually upgraded to strong consistency in late 2020).
Storage Classes and Lifecycle Management
GCS offers a simplified but powerful set of storage classes to help organizations optimize costs based on how frequently they access their data:
- Standard Storage: Best for data that is frequently accessed (“hot” data) and/or stored for only brief periods of time. This is the default tier for active lakehouse tables (e.g., the most recent months of a partition).
- Nearline Storage: A low-cost option for data accessed less than once a month.
- Coldline Storage: A very low-cost option for data accessed less than once a quarter (e.g., disaster recovery backups).
- Archive Storage: The lowest-cost option for data accessed less than once a year. Unlike Amazon Glacier, which can take hours to retrieve data, GCS Archive storage provides data access in milliseconds, though it incurs significantly higher retrieval costs.
GCS provides Object Lifecycle Management rules that allow users to automatically transition objects down to cheaper storage classes as they age, ensuring that a petabyte-scale data lake remains financially viable over time.
Multi-Region Capabilities
GCS offers unique location types for buckets. While standard buckets are tied to a specific GCP region (e.g., us-central1), users can create Multi-Region or Dual-Region buckets.
When a bucket is configured as Multi-Region (e.g., “US”), Google automatically replicates the data across multiple geographically separated data centers within that continent. This provides maximum availability and protection against region-wide outages. If a data center in Iowa goes offline, GCS automatically serves the data from a data center in South Carolina. For global enterprises with strict disaster recovery and business continuity requirements, this automated geo-redundancy is a massive advantage.
Summary and Tradeoffs
Google Cloud Storage is a robust, highly performant object storage platform that serves as the bedrock for modern analytics on GCP. Its strong consistency, millisecond retrieval times even for archive data, and seamless integration with BigQuery make it an exceptional foundation for an open data lakehouse.
The primary tradeoff with GCS (similar to AWS S3) revolves around vendor lock-in at the infrastructure level and data egress costs. While the data format (e.g., Iceberg) may be open, migrating petabytes of data out of GCS to another cloud provider incurs massive egress fees. Furthermore, while many open-source tools support GCS, the Amazon S3 API remains the universal standard. Tools often implement S3 support first, and GCS support later, though GCS does offer an S3-compatible XML API to ease migrations and tool integration.
Visual Architecture