Hadoop Catalog
The Hadoop Catalog (also referred to as the Filesystem Catalog or HadoopCatalog in the Iceberg codebase) is the simplest possible catalog implementation for Apache Iceberg: it stores all table metadata directly on a filesystem — either HDFS, a local filesystem, or (with significant caveats) cloud object storage — using no external service, no relational database, and no Thrift API. Tables are discovered and tracked through a structured directory hierarchy, and table state changes are committed through atomic file system operations.
The Hadoop Catalog’s appeal is its absolute simplicity: any environment with a filesystem and an Iceberg-compatible compute engine can run an Iceberg catalog with zero additional infrastructure. No database to provision, no catalog service to deploy, no API to authenticate against. For local development, unit testing, and proof-of-concept demonstrations, the Hadoop Catalog is frequently the first Iceberg catalog a practitioner encounters, because it requires only a warehouse directory path to be configured.
However, the Hadoop Catalog’s simplicity is inseparable from its most significant limitation: its atomic commit mechanism depends on the filesystem’s ability to perform atomic rename operations — a capability that HDFS provides but that object storage systems (S3, GCS, Azure Blob) do not. This limitation makes the Hadoop Catalog fundamentally unsafe for concurrent writer workloads on cloud object storage, disqualifying it from most production lakehouse deployments.
Understanding the Hadoop Catalog’s design, its atomic rename mechanism, and the precise circumstances under which it fails is essential context for understanding why more sophisticated catalog implementations (JDBC, HMS, REST Catalog) exist and what problems they were designed to solve.
The Directory Structure
The Hadoop Catalog organizes Iceberg table metadata in a structured directory hierarchy rooted at the configured warehouse location:
<warehouse>/
<namespace>/
<table_name>/
metadata/
v1.metadata.json
v2.metadata.json
v3.metadata.json
version-hint.text
data/
[Parquet data files]Each component of this structure serves a specific function:
<namespace>/: Directories at the warehouse root represent namespaces (equivalent to databases or schemas). The directory name is the namespace name. Multi-level namespaces are represented as nested directories: analytics/sales/ for the namespace analytics.sales.
<table_name>/: A directory within a namespace directory, representing one Iceberg table.
metadata/: The directory containing all of the table’s Iceberg metadata files: metadata.json versions, Manifest Lists (.avro files), and Manifest Files (.avro files).
vN.metadata.json: Sequentially numbered metadata JSON files. v1.metadata.json is the initial table state; each subsequent commit produces a new metadata.json with an incremented version number. Old metadata files are retained for time travel (until explicitly expired).
version-hint.text: The single most critical file in the Hadoop Catalog — a tiny text file containing one number: the version number of the current metadata.json file. This is the catalog’s pointer to the current table state. If version-hint.text contains 3, then v3.metadata.json is the current metadata and represents the current table state.
The Atomic Commit Mechanism: The version-hint.text Update
The Hadoop Catalog’s entire ACID-correctness depends on atomically updating version-hint.text to point to a newly committed metadata version without allowing two concurrent writers to simultaneously set it to different values.
The commit algorithm:
- Read current version: The writer reads
version-hint.textto determine the current metadata version (e.g.,3). - Read current metadata: The writer reads
v3.metadata.jsonto get the current table state. - Perform writes: The writer writes new Parquet data files, new Manifest Files, a new Manifest List, and a new metadata file —
v4.metadata.json— to themetadata/directory. - Attempt atomic update of version-hint.text: The writer attempts to atomically update
version-hint.textfrom3to4. The atomicity of this update is the critical safety property.
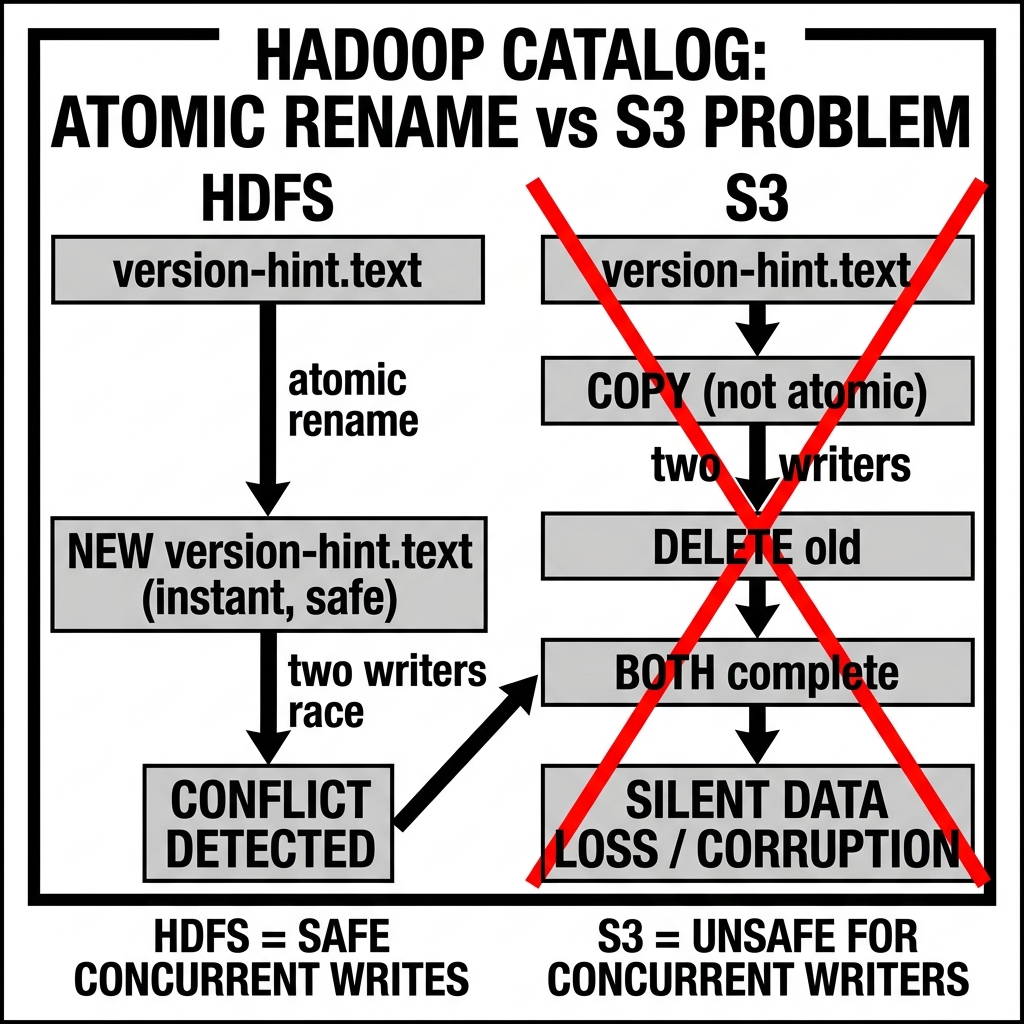
In HDFS, this atomic update is implemented as an atomic rename: the writer creates a temporary file with the new content (4), then atomically renames the temporary file to version-hint.text. HDFS provides true atomic rename semantics: either the rename succeeds (and all readers immediately see 4 in version-hint.text) or it fails without partial state. If two writers simultaneously attempt to rename their respective temporary files to version-hint.text, exactly one rename succeeds and the other fails — providing the compare-and-swap-like conflict detection the catalog needs.
After a successful rename, the writer reads version-hint.text again to verify it now contains 4 (not a value written by a concurrent winner). If it contains 4, the commit succeeded. If it contains a different version (written by a concurrent writer that won the race), this writer’s commit failed, and it must retry from step 1.
This race-detection-via-verify step is the Hadoop Catalog’s optimistic concurrency control: it proceeds without locking, commits changes, and then verifies the commit succeeded. If another writer committed in the meantime, the losing writer detects this and retries.
The Object Storage Problem: Non-Atomic Rename
The Hadoop Catalog’s commit mechanism is sound when running on HDFS (which provides atomic rename). It is fundamentally broken when running on cloud object storage systems (S3, GCS, Azure Blob Storage) that do not provide atomic rename semantics.
Why Object Storage Rename Is Not Atomic
Cloud object storage systems are key-value stores: an object is identified by its key (path), and objects are immutable. There is no native “rename” operation. What appears to be a “rename” in S3 is actually a multi-step operation:
- Copy the source object to the destination key (a new object write).
- Delete the source object.
This copy-then-delete sequence is not atomic. Between the copy and the delete, both the old key and the new key exist simultaneously. If another process checks for the object between the copy and delete, it sees both. If the process fails between the copy and delete, both objects persist indefinitely.
For the Hadoop Catalog’s commit mechanism:
- Writer A creates
version-hint.text.tmp-Awith content4. - Writer B creates
version-hint.text.tmp-Bwith content4(writingv4.metadata.jsonwith Writer B’s changes). - Writer A copies
version-hint.text.tmp-Atoversion-hint.text(S3 PUT operation). - Writer B copies
version-hint.text.tmp-Btoversion-hint.text(S3 PUT operation). - Writer A deletes
version-hint.text.tmp-A. - Writer B deletes
version-hint.text.tmp-B.
After step 4, version-hint.text contains 4 (written by B), pointing to Writer B’s v4.metadata.json. But Writer A’s v4.metadata.json also exists in the metadata/ directory, referenced by nothing and never visible to any reader — effectively an orphan file. The catalog is in a consistent state (pointing to B’s changes), but A’s changes were silently lost.
More critically, S3’s eventual consistency model (before the 2020 strong consistency update) meant that even the verify step — re-reading version-hint.text after the write — could return a stale cached value, causing Writer A to incorrectly believe its commit succeeded when it had actually been overwritten by Writer B. Since 2020, S3 provides strong read-after-write consistency for all operations, which reduces (but does not eliminate) the race window. The fundamental problem remains: the copy-then-delete “rename” is not atomic.
The Practical Consequence
In a multi-writer environment using the Hadoop Catalog on S3:
- Silent data loss: Commits from concurrent writers overwrite each other without either writer detecting the conflict.
- Orphan files: Failed “renames” leave partial file sets that are never garbage collected.
- Metadata corruption: In extreme cases, a partially written
version-hint.text(possible during a multi-byte write if S3 returns an error mid-PUT) can leave the catalog pointing to a non-existent or corrupt metadata version.
The bottom line: The Hadoop Catalog must never be used in multi-writer scenarios on object storage. This is not a caveat or a performance consideration — it is a data safety prohibition.
Single-Writer Safety on Object Storage
For single-writer scenarios on S3 (one Spark job writing to a table at a time, with no concurrent writes), the Hadoop Catalog is safe in practice because there are no concurrent writers to race with. The atomic rename failure mode requires concurrent commits; with a guaranteed single writer, there is no race condition.
Some teams use the Hadoop Catalog in production for ETL pipelines where a single Spark job writes to a table on a schedule (once per hour, once per day), and concurrent writes are architecturally impossible. In these cases, the Hadoop Catalog functions correctly. However, this single-writer requirement is architecturally fragile: if the guarantee is accidentally violated (a rerun overlaps with a new run, a second job is added without updating the catalog), data corruption can occur silently.
Configuration
spark = SparkSession.builder \
.config("spark.sql.catalog.my_hadoop_catalog", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.my_hadoop_catalog.type", "hadoop") \
.config("spark.sql.catalog.my_hadoop_catalog.warehouse", "hdfs://namenode:8020/iceberg-warehouse") \
.getOrCreate()For local filesystem (development only):
.config("spark.sql.catalog.local", "type", "hadoop") \
.config("spark.sql.catalog.local.warehouse", "/tmp/iceberg-warehouse") \Appropriate Use Cases
Local development and unit testing: The Hadoop Catalog with a local filesystem warehouse is the most common Iceberg setup for unit tests. It requires zero external dependencies, initializes instantly, and provides a fully functional Iceberg catalog for testing table creation, schema evolution, and query logic.
HDFS-based Hadoop cluster migrations: Organizations migrating from Hive-over-HDFS to Iceberg-over-HDFS can use the Hadoop Catalog as a transitional catalog that requires no new infrastructure — the metadata simply lives on the existing HDFS cluster alongside the data. Once the migration is validated, they can transition to an HMS or REST Catalog.
Single-writer batch pipelines on object storage: As described above, with the guarantee of a single writer at a time (enforced by the pipeline architecture), the Hadoop Catalog is functionally safe on S3. This is a reasonable intermediate step for teams beginning their Iceberg journey before configuring a more robust catalog.
Migration Path to Service-Based Catalogs
Tables created with the Hadoop Catalog can be migrated to other catalog implementations (HMS, JDBC, REST Catalog) without rewriting the underlying data files. The migration registers the existing table — located at its Hadoop Catalog warehouse path — with the new catalog by pointing the new catalog at the same metadata.json location. The data files, Manifest Files, and Manifest Lists remain exactly where they are; only the catalog pointer moves.
Conclusion
The Hadoop Catalog is Iceberg’s original, simplest catalog implementation — a pure filesystem-based approach that requires no external services and works perfectly for local development and single-writer HDFS deployments. Its reliance on atomic filesystem rename operations for commit safety makes it functionally correct on HDFS but fundamentally unsafe for concurrent write workloads on cloud object storage, where “rename” is not an atomic primitive. Engineers encountering the Hadoop Catalog for the first time in tutorials and development environments should understand this limitation clearly: it is a development and legacy migration catalog, not a production catalog for object-storage-based lakehouses with concurrent writers. For any production deployment with multiple writers or multi-engine access, the JDBC Catalog, Hive Metastore, or a REST Catalog implementation (Polaris, Nessie, Glue) provides the atomic compare-and-swap semantics that make concurrent writes safe.
Visual Architecture