Hidden Partitioning
Partitioning is a core optimization strategy in massive data lakehouses. By dividing data into logical segments (e.g., separating data by year or month), query engines can rapidly skip irrelevant data.
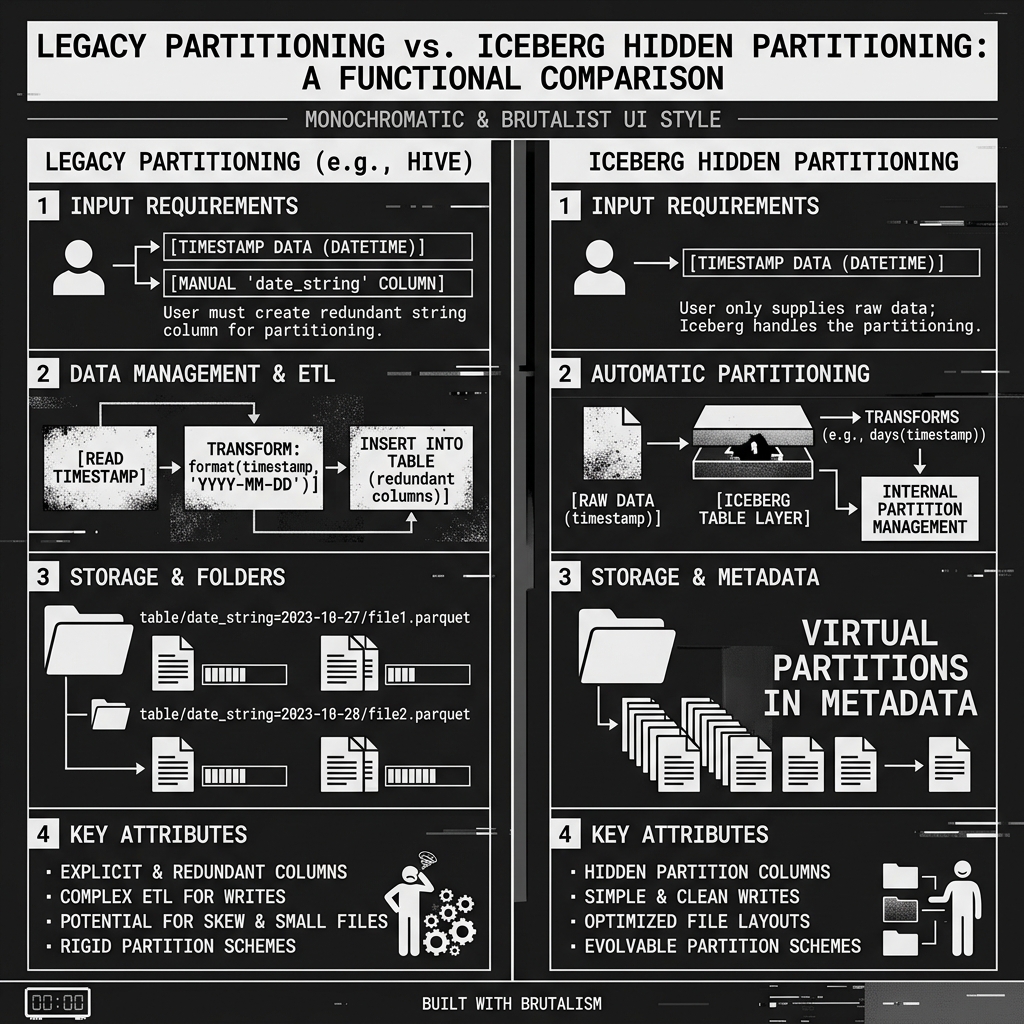
In legacy systems like Apache Hive, partitioning was exposed directly to the user and tied rigidly to the physical directory structure on disk. If a data engineer wanted to partition a table by date, they could not simply use the existing event_timestamp column. They were forced to manually create a brand new, redundant column (e.g., event_date_string).
Every time data was inserted, the user or the ETL pipeline had to explicitly extract the date from the timestamp and write it into the redundant column. If they forgot, the query engine wouldn’t know how to partition the data, leading to full table scans and astronomical compute costs.
Apache Iceberg eliminates this burden with Hidden Partitioning.
The Power of Transform Functions
In Apache Iceberg, partitioning is not driven by physical directories or redundant string columns; it is driven by metadata configurations known as the Partition Spec.
Iceberg’s Partition Spec supports Transform Functions (such as year(), month(), day(), hour(), truncate(), and bucket()).
Instead of forcing the user to create a new column, the data engineer simply configures the table’s Partition Spec to use a transform on an existing column. For example, the spec might be defined as month(event_timestamp).
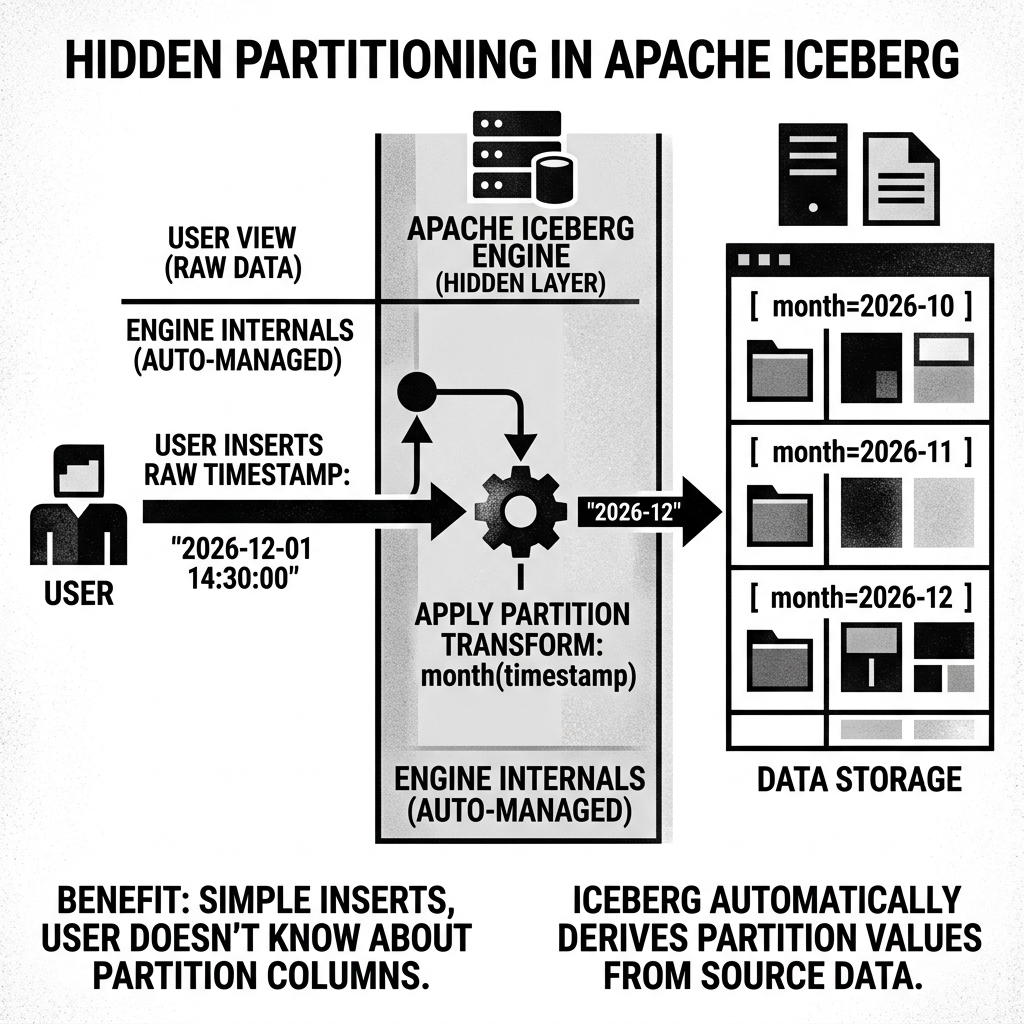
When a user executes an INSERT statement, they only provide the raw event_timestamp data. They do not need to know that the table is partitioned by month. They do not need to supply a separate month string.
Iceberg intercepts the incoming data, automatically applies the month() transform function to the timestamp, calculates the correct partition value, and seamlessly routes the Parquet data files to the correct logical partition in the metadata tree.
Diagram 1: Hidden Partitioning Concept
Simplifying the End-User Experience
Hidden Partitioning is primarily about separating the logical table structure from the physical storage layer, which provides a massively improved experience for analysts and downstream consumers.
In a legacy system, if an analyst wanted to query data for December 2026, they had to explicitly include the redundant partition column in their WHERE clause:
SELECT * FROM table WHERE event_date_string = '2026-12'.
If they just filtered on the timestamp (WHERE event_timestamp >= '2026-12-01'), the Hive engine would not recognize it as a partition filter and would execute a devastating full table scan.
With Iceberg’s Hidden Partitioning, the analyst simply queries the natural data:
SELECT * FROM table WHERE event_timestamp >= '2026-12-01' AND event_timestamp < '2027-01-01'.
Iceberg recognizes the relationship defined in the Partition Spec. It knows that to satisfy this timestamp range, it only needs to look at the month=2026-12 partition. It automatically translates the user’s natural query into the underlying partition pruning logic, ensuring optimal performance without requiring the analyst to understand the physical layout of the data lake.
Diagram 2: Legacy vs. Hidden Partitioning