Hive Metastore (HMS)
The Hive Metastore is the metadata management service at the heart of the Apache Hive data warehouse ecosystem, and by extension the foundational catalog service of the first generation of open data lakes. It was designed in the mid-2000s as Apache Hive’s solution to a concrete problem: how do you enable SQL queries over files stored on HDFS when those files have no inherent schema, no partition structure visible to the query engine, and no mechanism for multiple engines to agree on what tables exist and where their data lives?
The Hive Metastore solved this by introducing a centralized, service-oriented metadata repository: a Thrift API server backed by a relational database. Every Hadoop-ecosystem query engine — Hive, Pig, Spark, Impala, Presto, Trino, and eventually Iceberg-enabled engines — adopted the Hive Metastore as their catalog standard. For nearly two decades, HMS was the universal language of the open data lake.
Today, HMS occupies an interesting position in the lakehouse ecosystem. It remains the most widely deployed catalog in production data lake environments worldwide, and virtually every major query engine continues to support it for backward compatibility. But it was designed for a different era — before Iceberg’s multi-snapshot metadata model, before credential vending, before multi-table atomic commits, before the REST Catalog specification. Its architectural foundations, which were its greatest strengths in the Hadoop era, are now the source of its most significant limitations in the cloud-native lakehouse era.
The HMS Architecture
The Thrift API Layer
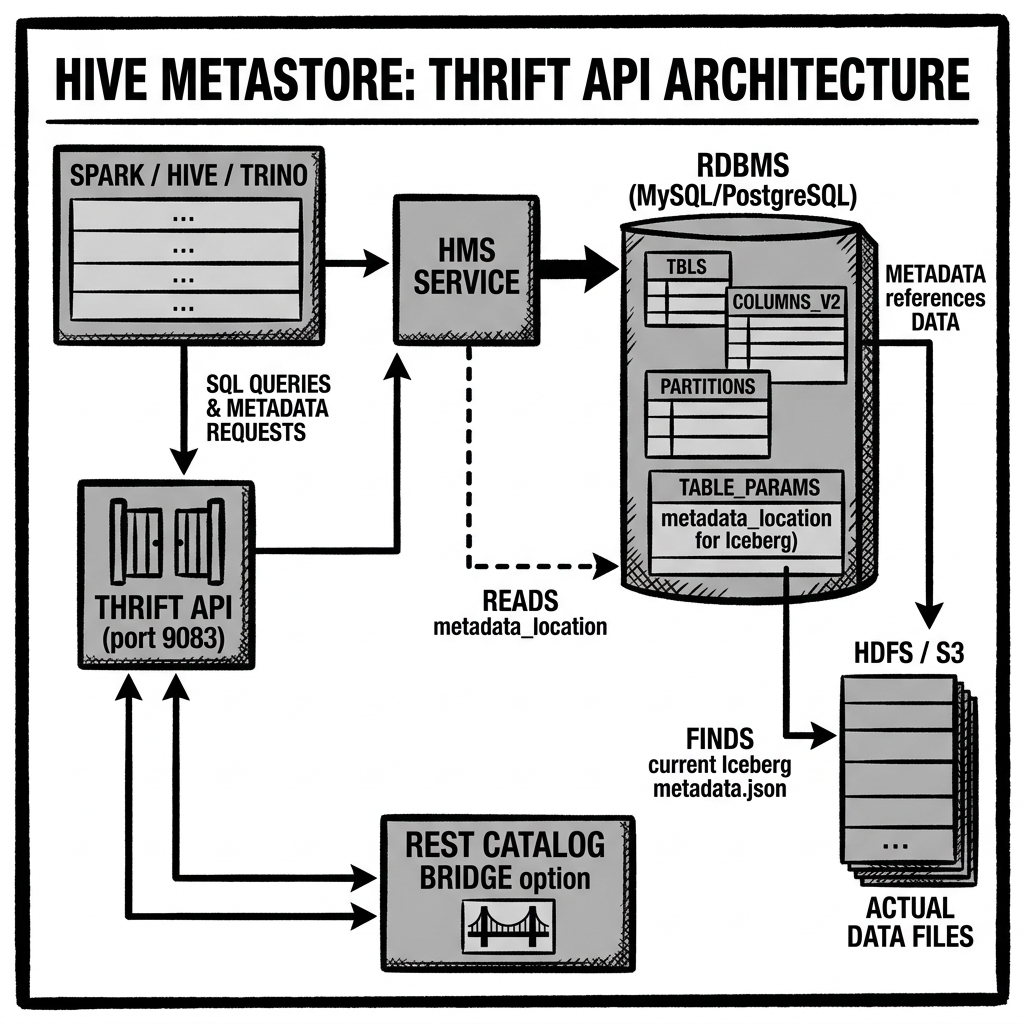
The Hive Metastore exposes all of its functionality through a Thrift RPC interface, typically listening on TCP port 9083. Apache Thrift is a cross-language RPC framework developed by Facebook, which generates client and server stubs in multiple languages from a shared interface definition file. The HMS Thrift interface defines operations for every metadata management task: creating databases, creating tables, adding partitions, looking up table definitions, modifying table properties, and so on.
When a Spark job needs to find a Hive table, it instantiates a HMS Thrift client (the HiveMetaStoreClient in the Hive JDBC library) and calls getTable(databaseName, tableName). The HMS Thrift server receives the request, queries its backing RDBMS, and returns the table metadata as a serialized Thrift Table object. The Spark driver deserializes the response and builds its internal table representation from it.
The Thrift protocol is binary, efficient, and language-agnostic in theory — Thrift generates stubs for C++, Java, Python, Go, and many other languages. In practice, the Hive Metastore’s Thrift API is heavily JVM-oriented. The canonical client implementation is in Java (in the hive-exec and hive-metastore Maven artifacts), and using HMS from non-JVM languages (Python’s PyIceberg, Go-based tools) requires either a JVM bridge process or a separately implemented Thrift client — both of which add operational complexity that the modern REST-based catalog API avoids entirely.
The RDBMS Persistence Layer
Behind the Thrift server lies a relational database that stores all the metadata HMS manages. The supported RDBMS backends are MySQL, PostgreSQL, Oracle, and Derby (the last being used only for development and embedded testing). In production deployments, MySQL and PostgreSQL are the standard choices.
The HMS RDBMS schema contains tables for:
DBS (Databases): One row per Hive database (equivalent to an Iceberg namespace), storing the database name, its HDFS/object storage location URI, and its owner.
TBLS (Tables): One row per table, storing the table name, the parent database ID (foreign key to DBS), the table type (MANAGED_TABLE, EXTERNAL_TABLE, VIRTUAL_VIEW), the storage location URI, and the last modification time.
COLUMNS_V2: One row per column per table, storing column name, data type (as a Hive type string), and column comment.
PARTITIONS and PARTITION_KEYS: One row per partition per table (for Hive-partitioned tables), storing the partition values and the specific storage location for that partition. For large, frequently partitioned tables, this table can contain billions of rows.
TABLE_PARAMS: Key-value pairs of table properties. For Iceberg tables using HMS as their catalog, the critical property is metadata_location — the current Iceberg metadata file URI. This is the pointer that HMS manages on behalf of Iceberg.
SDS (Storage Descriptors): Storage configuration for tables and partitions, including the InputFormat class, OutputFormat class, serialization library, and column information. For Iceberg tables, these values are set to Iceberg-specific implementations but are largely bypassed by Iceberg’s own metadata layer.
The Lock Mechanism
When an Iceberg writer needs to commit a new table state through HMS, it cannot use a native database compare-and-swap operation directly — the HMS Thrift API does not expose raw SQL operations. Instead, Iceberg’s HMS catalog implementation uses HMS’s own lock mechanism: it acquires a distributed lock for the table through the HMS Thrift API (lockTable), reads the current metadata_location property, verifies it matches the expected value, updates the property to the new metadata file path, and releases the lock.
This lock-based approach is functionally correct but has important performance implications:
- Lock acquisition and release add two round-trips to the HMS Thrift API (and therefore two RDBMS transactions) for every Iceberg commit.
- Under high concurrency (many writers simultaneously attempting to commit to the same table), the lock becomes a serialization bottleneck. Writers that fail to acquire the lock must wait or retry.
- If the locking process is interrupted (e.g., the writer process crashes between lock acquisition and release), the lock may be left in a “locked” state, requiring manual intervention or a timeout-based auto-release mechanism.
HMS as an Iceberg Catalog
Despite these architectural constraints, HMS functions as a fully capable Iceberg catalog for the vast majority of production use cases. The integration is straightforward:
When an Iceberg table is created using HMS as its catalog, Iceberg:
- Writes the initial
metadata.jsonfile to the table’s object storage location. - Calls HMS via Thrift to create a new table record in
TBLS, with themetadata_locationtable property set to the URI of the initial metadata file. - The table is now registered in HMS and visible to any engine that queries HMS.
When an engine loads the table:
- The engine calls HMS via Thrift:
getTable(database, table). - HMS returns the table record from
TBLS, including themetadata_locationproperty. - The engine reads the
metadata_locationURI from object storage to get the current Iceberg snapshot. - All subsequent access to table data goes directly to object storage, bypassing HMS entirely.
When a writer commits a new table state:
- The writer acquires the HMS table lock.
- The writer updates the
metadata_locationproperty in HMS viaalterTableto point to the new metadata file. - The writer releases the lock.
This is a fully functional Iceberg catalog workflow. The table’s Iceberg history, snapshots, schemas, and partition specs all live in the Iceberg metadata files on object storage. HMS is purely the pointer registry.
HMS Limitations in the Modern Lakehouse
No Credential Vending
HMS has no concept of dynamically generating scoped storage credentials. Compute engines that use HMS must have standing, broad credentials to access the underlying object storage — typically through IAM roles granted to the EC2 instances or Kubernetes service accounts running the compute engine. This makes table-level access control at the storage layer impossible to enforce through HMS alone; you must rely on IAM policies at the bucket or prefix level, which are far coarser than table-level governance.
Single-Table Operations Only
HMS’s data model and locking mechanism are designed for single-table operations. There is no HMS API for atomically updating the metadata of two tables simultaneously. Workflows that require cross-table atomicity (a fact table and its aggregate summary updated atomically) must either accept eventual consistency between the two tables or use application-level compensation logic.
RDBMS Scalability Constraints
The HMS RDBMS becomes the performance bottleneck for large deployments. The PARTITIONS table, in particular, can grow to billions of rows for aggressively partitioned tables. Queries against this table for partition discovery (listing all partitions for a table, or finding partitions matching a predicate) can be slow when the table contains many millions of partitions, even with proper indexing.
Schema migrations to the HMS RDBMS (when upgrading Hive or HMS versions) can be risky and time-consuming for large metastore databases, requiring careful version management and tested rollback procedures.
No Native Branching or Versioning
HMS provides no native mechanism for creating table branches, tags, or versioned views of catalog state. Every table has a single current state. There is no “point in time” view of what tables existed or what their schemas were at a given moment in history (beyond what is implied by Iceberg’s own snapshot history for individual tables). Workflows that need catalog-level version control (CI/CD pipelines for data transformations, isolated testing environments) cannot achieve this through HMS.
Thrift API Impedance
The Thrift API is functional but operationally heavyweight for cloud-native deployments. Running an HMS server requires a JVM-based service process, an RDBMS backend, network access from all compute engines to port 9083, and careful management of the metastore schema version across upgrades. Exposing the Thrift API through firewall rules and VPC security groups adds operational complexity that a simple HTTPS REST endpoint avoids.
HMS in the Modern Ecosystem: Migration Paths
The reality of the current ecosystem is that HMS cannot simply be abandoned — too much existing production infrastructure depends on it. Instead, the migration trajectory for HMS-based deployments is gradual:
HMS + REST Catalog Bridge: Modern HMS deployments (Hive 4.x) support an Iceberg REST Catalog server mode that exposes the REST Catalog API over HTTP, backed by the HMS RDBMS. This allows REST Catalog-compliant engines to connect to an existing HMS deployment without requiring a full catalog migration.
Parallel Catalog Migration: Organizations running HMS can incrementally migrate tables to a REST Catalog (Polaris, Nessie, Glue) by registering new tables in the new catalog and migrating historical tables in batches, while keeping existing HMS-based workflows operational during the transition.
Hive Metastore on Kubernetes: The operational complexity of HMS has decreased significantly with containerization. Running HMS as a Kubernetes Deployment backed by a managed RDS database (AWS RDS for PostgreSQL or MySQL) provides high availability without significant operational overhead, making HMS viable for cloud-native deployments even as REST Catalog adoption grows.
The Enduring Legacy of HMS
Despite its limitations, the Hive Metastore’s architectural legacy is profound. Its basic concepts — a central metadata service mapping logical table identifiers to physical storage locations, with a Thrift API for engine-catalog communication — are present in every subsequent catalog design. The REST Catalog specification is, in many ways, the architectural heir of HMS: it provides the same core metadata routing service, but through a modern HTTP API instead of Thrift, with storage-native credential vending instead of standing IAM grants, and with atomic commit protocols instead of lock-based serialization.
Understanding HMS is not merely archaeological knowledge — it is the context that makes the design decisions of Polaris, Nessie, and the REST Catalog specification legible. Every modern catalog feature exists specifically because HMS demonstrated, through years of production experience, what a central catalog needed to do and where its original design fell short.
Conclusion
The Hive Metastore remains the most widely deployed lakehouse catalog in production environments worldwide, a testament to its reliability and universal compatibility with the Hadoop-era query engine ecosystem. Its Thrift API and RDBMS persistence model deliver functional, battle-tested Iceberg catalog capabilities for the majority of production use cases. Its limitations — no credential vending, single-table-only atomicity, RDBMS scalability ceilings, and the Thrift protocol’s operational overhead — define the specific capabilities that modern REST Catalog implementations (Polaris, Nessie, Glue REST endpoint) were built to address. Engineers operating HMS-based deployments in 2026 should understand both HMS’s enduring strengths and its architectural ceiling, and plan their migration to REST Catalog-compatible services accordingly, leveraging HMS’s REST bridge capabilities to smooth the transition.
Visual Architecture