Iceberg Catalog
The Iceberg Catalog is the central nervous system of any Apache Iceberg deployment. It is the service responsible for maintaining a mapping between logical table identifiers — the human-readable names like analytics.sales.orders — and the physical location of each table’s current metadata file on object storage. Without the catalog, Apache Iceberg tables cannot be found, committed to, or reliably read by any compute engine.
The catalog is also where all of Iceberg’s most important correctness properties are enforced. The atomic commit protocol, which prevents two concurrent writers from simultaneously corrupting a table’s metadata state, depends entirely on the catalog’s compare-and-swap operation being strongly consistent. The table discovery mechanism, which allows Trino, Spark, Flink, and dozens of other query engines to access the same tables, depends on the catalog implementing a standard API that all engines can speak.
Understanding the Iceberg Catalog — its architectural role, its implementation variants, the trade-offs between them, and the emerging REST Catalog standard that is converging the ecosystem toward a unified protocol — is essential context for any engineer designing, deploying, or operating a data lakehouse at scale.
The Catalog’s Single Responsibility: The Metadata Pointer
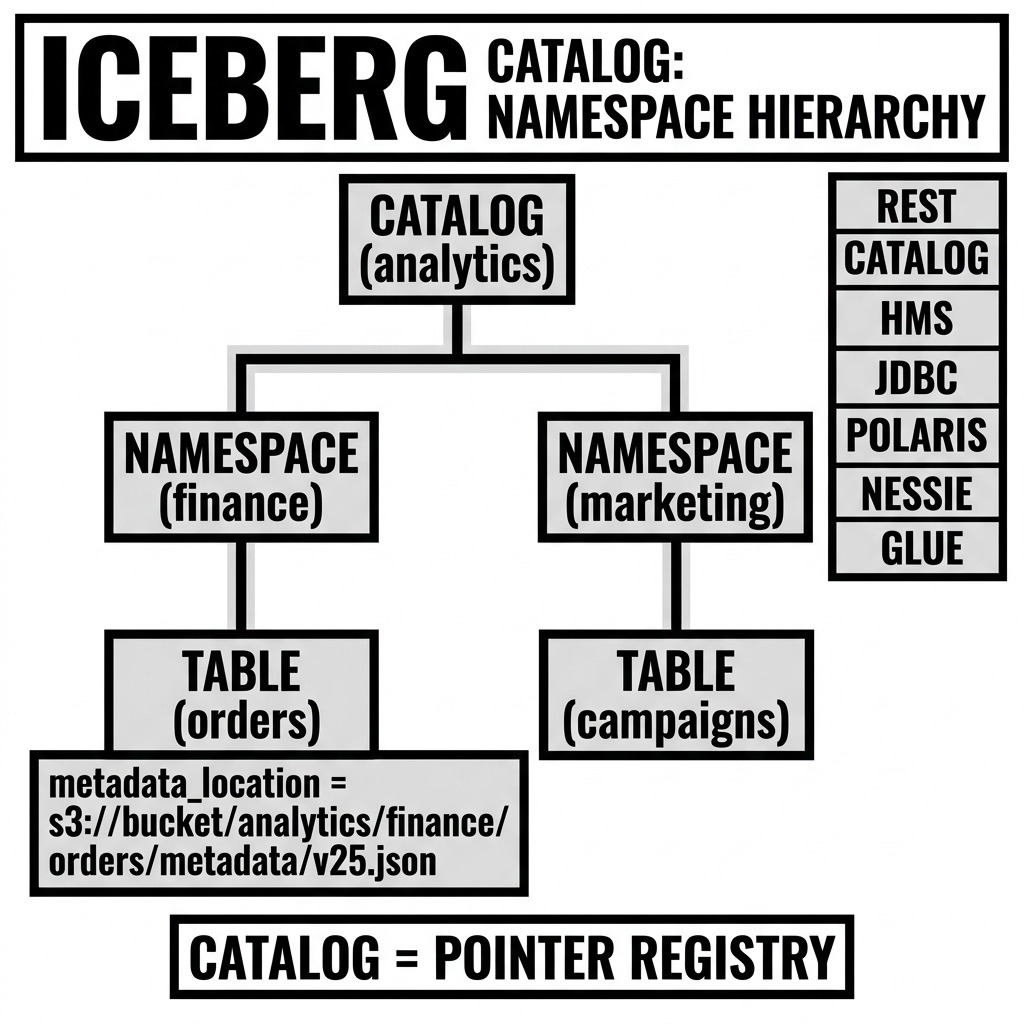
To understand what the Iceberg Catalog does, it helps to understand what it does not do. The catalog does not store table data. It does not store column statistics. It does not store the schema, partition spec, or snapshot history. All of that information lives in the Iceberg metadata files (the metadata.json chain, the Manifest Lists, the Manifest Files) stored on object storage.
The catalog stores exactly one thing per table: a pointer to the current metadata.json file.
This pointer is typically the full object storage URI:
s3://my-bucket/warehouse/analytics/sales/orders/metadata/00025-a4b3c2d1-1234-5678-abcd-ef9012345678.metadata.jsonWhen a query engine needs to read the orders table, it:
- Asks the catalog: “What is the current metadata file for
analytics.sales.orders?” - The catalog returns the URI of the latest
metadata.json. - The engine reads the
metadata.jsonto get the current Snapshot ID. - The engine reads the Manifest List for that Snapshot.
- The engine reads the relevant Manifest Files to get the data file list.
- The engine reads the data files.
The catalog is only consulted in step 1. All subsequent reads go directly to object storage.
The Commit Operation
When a writer completes a transaction, it:
- Writes new data files to object storage.
- Writes new Manifest Files, a new Manifest List, and a new
metadata.json(pointing to the new Manifest List as the current Snapshot). - Asks the catalog to update the metadata pointer from the old
metadata.jsonpath to the newmetadata.jsonpath — but only if the current pointer still points to the old path. This is the compare-and-swap.
The compare-and-swap is the atomic commit. It is the sole point of concurrency control in an Iceberg deployment. If two writers simultaneously complete step 2 and race to step 3, only one can win the compare-and-swap. The loser must detect the conflict, read the new metadata (produced by the winner), determine if there is a logical write conflict, and either retry (if no conflict) or fail with a concurrency exception.
This means the catalog’s implementation of the compare-and-swap must be strongly consistent and linearizable — as discussed in the Strong Consistency article. Any catalog that allows two writers to both succeed in updating the metadata pointer simultaneously will corrupt the table’s metadata. The winning implementation of the catalog is the foundational correctness guarantee of the entire Iceberg table format.
Catalog Implementations: A Comparative Analysis
The Iceberg ecosystem supports multiple catalog implementations, each with distinct architectural characteristics, operational trade-offs, and capability profiles.
Hive Metastore (HMS): The Veteran
The Apache Hive Metastore is the most widely deployed metadata catalog in the Hadoop ecosystem. It was the original catalog supported by Iceberg, reflecting the reality that Iceberg was first designed to serve as a better table format for existing Hive-based data lakes.
HMS stores table metadata in a relational database (MySQL, PostgreSQL, Derby). The Iceberg-specific metadata pointer is stored as a table property in HMS. When an Iceberg writer wants to commit, it acquires a distributed lock (via Zookeeper or an HMS-native locking mechanism) for the table, performs the metadata pointer update, and releases the lock.
Advantages: Mature, battle-tested, widely compatible (virtually every Hadoop-era tool and most modern query engines support HMS). Single service that handles both legacy Hive tables and modern Iceberg tables in the same catalog.
Disadvantages: The relational database backing HMS is a single point of failure and a potential throughput bottleneck for high-frequency write workloads. The lock-based concurrency model is less scalable than lock-free compare-and-swap approaches. HMS lacks native support for advanced Iceberg features like multi-table transactions and credential vending.
AWS Glue Data Catalog: The Serverless AWS Option
AWS Glue Data Catalog is Amazon’s managed, serverless metadata catalog service, deeply integrated with the AWS analytics ecosystem. It provides native Iceberg support since 2022, storing the Iceberg metadata pointer as a table property.
Glue’s underlying storage is fully managed — there is no database to provision, operate, or scale. Glue scales automatically and provides high availability across multiple AWS Availability Zones. Its integration with AWS IAM provides native, fine-grained access control at the table and database level.
Advantages: Zero infrastructure to manage. Native integration with Amazon Athena, AWS EMR, AWS Glue ETL, Amazon Redshift Spectrum. Fine-grained IAM access control. Highly available.
Disadvantages: Deep AWS vendor lock-in — a Glue-backed Iceberg table is difficult to access from non-AWS engines without custom configuration. Glue’s API rate limits (for metadata operations) can be a bottleneck for pipelines with very high write frequency. Glue does not implement the emerging REST Catalog standard, requiring engine-specific Glue connectors.
AWS DynamoDB-Backed Catalog
Several Iceberg deployments use Amazon DynamoDB as the backing store for a custom catalog implementation. DynamoDB’s ConditionalExpression feature (conditional writes) provides strongly consistent, linearizable compare-and-swap semantics natively, making it an excellent backing store for the Iceberg commit protocol.
This approach is popular in AWS environments where organizations want full control over the catalog implementation (no HMS overhead, no Glue lock-in) while leveraging DynamoDB’s strong consistency and horizontal scalability.
Project Nessie: The Git-Inspired Catalog
Project Nessie, developed by Dremio and released as an open-source Apache-licensed project, takes a fundamentally different approach to the catalog problem. Instead of simply tracking a current metadata pointer per table, Nessie models the entire catalog as a versioned repository with Git-like semantics.
Every table update in Nessie creates a new immutable Commit in the Nessie commit history. The commit records not just the new metadata pointer for the updated table, but also the state of every other table in the catalog at that moment. This means every Nessie commit captures a globally consistent catalog snapshot — a point-in-time view of the entire data lakehouse.
This architecture enables capabilities that traditional catalogs cannot support:
Multi-table atomic commits: A single Nessie commit can atomically update the metadata pointers for multiple tables simultaneously. This enables the MERGE operation to atomically commit updates to both the primary table and a secondary audit log table, guaranteeing that both updates are either both visible or both invisible — never one without the other.
Branching: Engineers can create a named Nessie branch (analogous to a Git branch) and perform destructive or experimental operations — loading new data, running schema migrations, testing new partition strategies — on the branch without affecting the main branch. The main branch remains completely unchanged. When the experimental work is validated, it is merged back to main.
Rollback: Rolling back to a previous catalog state is as simple as resetting the branch pointer to an earlier commit hash. Every historical catalog state is retained in the Nessie commit history.
Nessie as an Iceberg Catalog: Nessie implements the Iceberg Catalog API, meaning any query engine that supports Iceberg catalog plugins can connect to Nessie with minimal configuration. The Nessie catalog returns the current metadata pointer for any table on any branch.
Disadvantages: Nessie adds operational complexity — it is a separate service to deploy and manage, with its own backing database (RocksDB, MongoDB, or a JDBC database). The Git-like semantics are powerful but require data team discipline to use correctly (poorly managed branches can create confusion about which branch contains authoritative data).
The REST Catalog Specification: The Emerging Standard
The Iceberg REST Catalog Specification (also called the Iceberg REST API or IRC) is the most important architectural development in the Iceberg catalog ecosystem. It defines a vendor-neutral, HTTP-based API for all catalog operations, allowing any conformant catalog service to be accessed by any conformant query engine using the same client code.
The REST Catalog API defines endpoints for:
Namespace management: List namespaces, create namespaces, get namespace properties, delete namespaces. This provides the hierarchical database/schema structure that organizes tables into logical groups.
Table management: List tables, create tables, load table metadata (the core operation that returns the metadata file URI), drop tables, rename tables.
Commit (atomic update): The commit endpoint accepts a proposed metadata update and expected preconditions, performs the compare-and-swap, and returns success or a 409 Conflict. This is the central ACID-critical operation.
View management: The emerging support for managing Iceberg views (stored SQL queries) through the same catalog API.
Credential vending: An endpoint for dynamically generating short-lived, scoped storage credentials. Instead of query engines having standing access to all objects in the data lake’s storage bucket, the catalog service issues per-read credentials scoped to specific table files. This enables fine-grained, table-level access control without requiring broad IAM roles on the query engine’s service account.
Advanced features: Multi-table transactions (committing to multiple tables atomically), lazy snapshot loading (returning metadata without eagerly loading all snapshot history), and server-side metrics collection.
Apache Polaris: The Open REST Catalog Implementation
Apache Polaris (donated by Snowflake to the Apache Software Foundation in 2024) is the premier open-source implementation of the Iceberg REST Catalog Specification. Polaris provides a production-grade, governance-ready catalog service that:
- Implements the complete Iceberg REST API specification.
- Supports multi-engine access from Spark, Trino, Flink, Snowflake, Dremio, and any other Iceberg REST Catalog-compatible engine.
- Provides fine-grained RBAC (Role-Based Access Control) at the catalog, namespace, and table level.
- Supports credential vending for both AWS S3 and Azure ADLS.
- Includes multi-catalog federation capabilities for querying across multiple independent Polaris instances.
Polaris represents the convergence point for the Iceberg catalog ecosystem: a vendor-neutral, open-source, governance-rich catalog that any engine can access through the standard REST API.
Snowflake Open Catalog
Snowflake’s managed Polaris-based catalog offering allows organizations to manage Iceberg tables through a Snowflake-hosted REST Catalog service, accessible by non-Snowflake engines (Spark, Trino, Flink) through the standard Iceberg REST API. This enables Snowflake customers to use their Snowflake environment as the catalog governance layer while allowing other query engines to read the same Iceberg tables.
Choosing a Catalog: Decision Framework
| Organization Context | Recommended Catalog |
|---|---|
| AWS-native, small team, minimal ops overhead | AWS Glue |
| Existing Hadoop/Spark ecosystem, legacy compatibility | Hive Metastore |
| Multi-engine (Spark + Trino + Flink + Snowflake), vendor-neutral | Polaris (REST Catalog) |
| Complex data engineering workflows, CI/CD for data | Nessie |
| Databricks-native, Delta + Iceberg | Unity Catalog (with UniForm support) |
| High-frequency streaming commits, AWS-native | DynamoDB-backed custom catalog |
The REST Catalog as the Industry Convergence Point
The trajectory of the Iceberg catalog ecosystem is clear: the REST Catalog specification is becoming the universal standard that bridges all implementations. Nessie implements the REST API. Polaris is built on the REST API. AWS Glue is adding REST API compatibility. Hive Metastore is being extended with REST API translation layers.
The eventual steady state is a catalog ecosystem where any engine implementing the Iceberg REST Catalog client can work with any catalog implementing the Iceberg REST Catalog service — without engine-specific catalog plugins, without vendor-specific SDKs, and without compromising governance, consistency, or access control. This is the architectural endgame: a truly interoperable, engine-neutral, governance-rich lakehouse catalog layer that the entire analytical ecosystem can build upon.
Conclusion
The Iceberg Catalog is deceptively simple in its primary function — it maps table names to metadata pointers — and deeply consequential in its architectural implications. The choice of catalog implementation determines the consistency model of every write transaction, the governance capabilities available for access control, the operational overhead of the metadata service, and the degree of engine interoperability the organization can achieve. The emergence of the REST Catalog specification as the industry standard protocol, and Apache Polaris as its reference implementation, is the most significant architectural development in the Iceberg ecosystem for enterprise deployments. Engineers who choose catalog implementations with the REST API as their north star will find their lakehouses positioned for the maximum interoperability, governance, and engine flexibility that the modern multi-cloud, multi-engine analytical landscape demands.
Visual Architecture