JDBC Catalog
The JDBC Catalog is a catalog implementation for Apache Iceberg that uses any JDBC-compatible relational database as its persistent metadata backend. It is the simplest fully self-hostable Iceberg catalog: any relational database that an organization already operates — PostgreSQL, MySQL, MariaDB, H2, SQLite — can serve as the catalog store with minimal configuration and zero additional infrastructure. No dedicated catalog service, no JVM daemon process beyond the compute engines themselves, and no proprietary cloud service is required.
The JDBC Catalog occupies a specific and important niche in the Iceberg catalog ecosystem: it is the lowest-overhead path from “I have a database and I want to run Iceberg tables” to a working, ACID-correct, production-capable catalog. For organizations in the earlier stages of lakehouse adoption, for teams building local development or CI/CD testing environments, for academic and research institutions with limited infrastructure budgets, and for medium-scale deployments that do not yet need the advanced features of REST Catalog implementations (credential vending, fine-grained RBAC, multi-table atomic commits), the JDBC Catalog provides exactly the right level of functionality with minimal operational complexity.
The JDBC Catalog’s Database Schema
When the JDBC Catalog initializes against a new database (or a database that has not previously hosted a JDBC Catalog), it automatically creates three tables to store its catalog state:
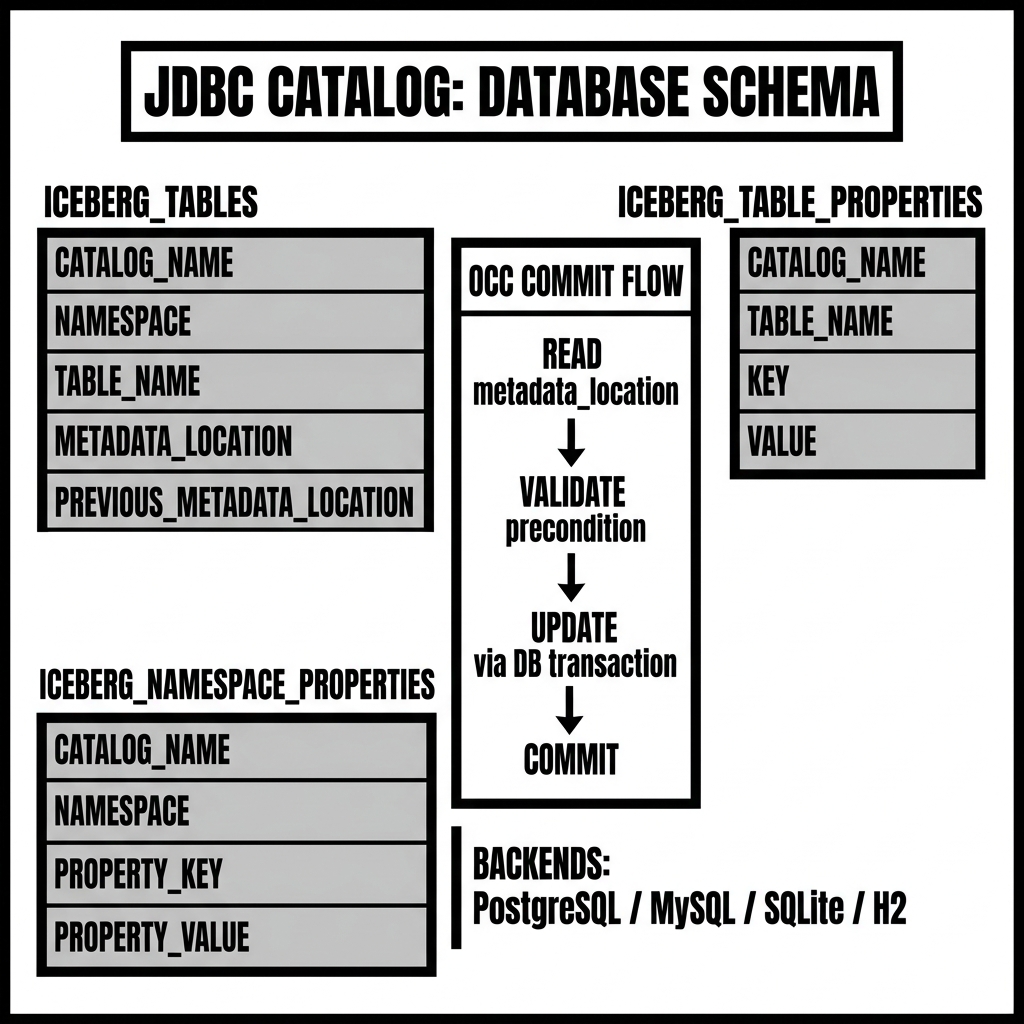
iceberg_tables
The central table of the JDBC Catalog. Each row corresponds to one registered Iceberg table and contains:
catalog_name(VARCHAR): The logical name of the Iceberg catalog. This allows a single database schema to host multiple logically separate catalogs (e.g., aproductioncatalog and astagingcatalog) by storing their tables in the sameiceberg_tablesdatabase table.table_namespace(VARCHAR): The namespace (Iceberg term for “database” or “schema”) containing the table. Multi-level namespaces are stored as a dot-separated string (e.g.,analytics.sales).table_name(VARCHAR): The table’s name within its namespace.metadata_location(VARCHAR): The current metadata file URI — the path to themetadata.jsonfile on S3, GCS, ADLS, or local filesystem that represents the table’s current state. This is the single most important field in the catalog: it is the pointer that all reads and writes use to find the current Iceberg table state.previous_metadata_location(VARCHAR): The metadata file URI from the previous commit. Used for optimistic concurrency control validation during commits.
The combination of (catalog_name, table_namespace, table_name) is the unique identifier for each table — the catalog primary key.
iceberg_namespace_properties
Stores key-value properties for Iceberg namespaces. Each row represents one property for one namespace:
catalog_name,namespace: Identify the namespace.property_key,property_value: A single key-value property pair.
Common namespace properties include the default storage location for tables created within the namespace (location), the default file format (format), and custom organizational metadata.
iceberg_table_properties
Stores catalog-level table properties (distinct from the Iceberg-native table properties embedded in the metadata.json file). Rarely used for advanced configurations.
The Atomic Commit Mechanism
The JDBC Catalog’s most critical function — ensuring that concurrent writers cannot simultaneously corrupt a table’s metadata state — is implemented through the relational database’s native transaction capabilities.
The Commit Algorithm
When an Iceberg engine completes a write operation and wants to commit a new table state:
-
Write metadata to storage: The engine writes new Parquet data files, new Manifest Files, a new Manifest List, and a new
metadata.jsonto object storage. All of these operations happen before touching the catalog. -
Begin a database transaction: The engine opens a database transaction against the JDBC Catalog’s backing database.
-
Read the current metadata location: Within the transaction, the engine reads the current
metadata_locationfor the target table fromiceberg_tables. -
Validate the precondition: The engine compares the current
metadata_locationwith themetadata_locationit started from (the value it read when it began the write operation). If they match, no other writer has committed to this table since this writer began — safe to proceed. If they differ, another writer has committed in the meantime — this writer’s changes may conflict, and it must abort and retry. -
Update the metadata pointer: If the precondition is valid, the engine updates
metadata_locationto the newmetadata.jsonURI and setsprevious_metadata_locationto the old value. -
Commit the database transaction: The RDBMS commits the transaction atomically. If any other concurrent transaction tried to update the same row simultaneously, one will fail with a serialization conflict, and the losing transaction must retry.
This optimistic concurrency control (OCC) pattern — where writers proceed without acquiring locks upfront, but validate preconditions before committing — is the same pattern used by the Iceberg REST Catalog’s compare-and-swap commit endpoint. The JDBC Catalog implements it using the RDBMS’s native SERIALIZABLE isolation level or row-level locking (depending on the database and configuration).
Database-Specific Considerations
PostgreSQL: PostgreSQL’s SERIALIZABLE isolation level provides the strongest concurrency guarantee — it detects write-write conflicts between concurrent transactions and fails one with a 40001 SQLSTATE (could not serialize access) error, which Iceberg’s JDBC Catalog translates into a retryable commit conflict. PostgreSQL’s row-level locking via SELECT FOR UPDATE is an alternative, providing explicit locking that prevents concurrent updates to the same row.
MySQL / MariaDB: MySQL’s REPEATABLE READ isolation level (the default) plus SELECT FOR UPDATE provides equivalent behavior. MySQL’s InnoDB engine supports full row-level locking and ACID transactions, making it a reliable JDBC Catalog backend.
SQLite: SQLite’s write concurrency model is fundamentally different from PostgreSQL and MySQL: SQLite uses a file-level write lock that allows only one writer at a time across the entire database file. This means that in a SQLite-backed JDBC Catalog, all concurrent commit attempts are serialized automatically by the file lock — there is no risk of concurrent corruption, but there is also no parallel write throughput. SQLite is appropriate only for single-writer scenarios (local development, sequential CI/CD pipelines) and should never be used in production environments with multiple concurrent writers.
H2: The H2 in-memory database is commonly used in unit tests for the JDBC Catalog. H2 provides full ACID semantics and SERIALIZABLE isolation, making it functionally identical to PostgreSQL for testing purposes. H2’s persistence mode (writing to a file) can be used for lightweight persistent single-process deployments, though it shares SQLite’s limitations for multi-process concurrent access.
Configuration
Configuring the JDBC Catalog in Apache Spark:
spark = SparkSession.builder \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.my_catalog", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.my_catalog.catalog-impl", "org.apache.iceberg.jdbc.JdbcCatalog") \
.config("spark.sql.catalog.my_catalog.uri", "jdbc:postgresql://db-host:5432/iceberg_catalog") \
.config("spark.sql.catalog.my_catalog.jdbc.user", "iceberg_user") \
.config("spark.sql.catalog.my_catalog.jdbc.password", "iceberg_password") \
.config("spark.sql.catalog.my_catalog.warehouse", "s3://my-bucket/iceberg-warehouse/") \
.getOrCreate()The key configuration parameters:
uri: The JDBC connection string for the backing database. Supportsjdbc:postgresql://,jdbc:mysql://,jdbc:sqlite:,jdbc:h2:, and any other JDBC-compatible database.jdbc.user/jdbc.password: Database authentication credentials.warehouse: The base storage location for Iceberg table data and metadata files. Tables are stored under<warehouse>/<namespace>/<table>/.catalog-impl: Must beorg.apache.iceberg.jdbc.JdbcCatalogto select the JDBC Catalog implementation.
For PyIceberg:
from pyiceberg.catalog.sql import SqlCatalog
catalog = SqlCatalog(
"my_catalog",
**{
"uri": "postgresql+psycopg2://iceberg_user:password@db-host:5432/iceberg_catalog",
"warehouse": "s3://my-bucket/iceberg-warehouse/",
}
)PyIceberg uses SQLAlchemy as its JDBC/DBAPI abstraction layer, providing compatibility with the same database backends as the Java-based JdbcCatalog.
The JDBC Driver Requirement
A critically important operational detail for JDBC Catalog deployments: the appropriate JDBC driver library must be present in the compute engine’s classpath. For Spark, this means including the driver JAR in the Spark executor’s dependency configuration. For example, for PostgreSQL:
spark.jars.packages=org.postgresql:postgresql:42.6.0Failure to include the driver results in a cryptic ClassNotFoundException or No suitable driver error at catalog initialization time. This is one of the most common operational issues encountered when first configuring the JDBC Catalog.
When to Use the JDBC Catalog
The JDBC Catalog is the right choice in specific deployment contexts:
Local development and testing: For running Iceberg locally (on a developer’s laptop, in a Docker Compose environment, in a CI/CD pipeline), SQLite (for single-writer testing) or H2 (for in-memory test isolation) provide a zero-infrastructure catalog that requires no external service.
Small-scale production with existing RDBMS: Organizations that already operate a PostgreSQL or MySQL server (for their application databases) can use that existing server as the Iceberg catalog backend with minimal additional operational complexity. For data volumes and concurrency levels that don’t stress the RDBMS, this is the most operationally economical path to a production Iceberg catalog.
Self-hosted environments without cloud services: Air-gapped environments, on-premises deployments, or environments where cloud-managed catalog services (Glue, Polaris-as-a-Service) are unavailable can use the JDBC Catalog with an existing on-premises database.
Migration path to REST Catalog: Organizations beginning their Iceberg journey can start with the JDBC Catalog (minimal setup friction) and migrate to a REST Catalog implementation (Polaris, Nessie) as their scale and governance requirements grow. Iceberg’s catalog interface abstraction makes this migration transparent to the compute engines — changing the catalog configuration is all that is required.
Limitations
No credential vending: The JDBC Catalog provides no mechanism for generating scoped storage credentials. Compute engines must have standing IAM permissions to access the warehouse storage location.
No branching or time travel at catalog level: Unlike Nessie/Arctic, the JDBC Catalog has no concept of catalog branches, tags, or catalog-level rollback. Individual Iceberg tables support their own snapshot-level time travel, but the catalog state itself has no version history.
No fine-grained RBAC: The JDBC Catalog provides no access control at the catalog or table level. Access control must be enforced through database permissions (controlling which database users can access the iceberg_tables schema) and object storage IAM policies — both of which are coarser-grained and less operationally convenient than REST Catalog RBAC.
Concurrency ceiling: For high-frequency write workloads with many concurrent writers, the RDBMS becomes the serialization bottleneck. The commit protocol’s database transaction overhead accumulates under high concurrency, and the RDBMS’s locking overhead can create queueing delays. REST Catalog implementations designed for high write throughput (using distributed compare-and-swap semantics on DynamoDB or native PostgreSQL SERIALIZABLE) generally outperform the JDBC Catalog under heavy concurrent write load.
Conclusion
The JDBC Catalog is Apache Iceberg’s most accessible catalog implementation — the lowest-friction path from a relational database to a fully functional, ACID-correct Iceberg catalog. Its automatic schema initialization, straightforward JDBC configuration, and compatibility with every major relational database make it the first catalog most Iceberg practitioners encounter in development environments and small-scale production deployments. Understanding its internal schema design, its OCC-based atomic commit mechanism, and its concurrency limitations through the lens of RDBMS transaction semantics provides the intuition for choosing when the JDBC Catalog is the right tool and when growing scale or governance requirements demand migration to a purpose-built REST Catalog implementation.
Visual Architecture