LZ4 Compression
Core Definition
LZ4 is a lossless data compression algorithm focused on incredibly fast compression and decompression speeds. Developed by Yann Collet (the same creator of Zstandard), LZ4 sits at the extreme end of the compression spectrum: it sacrifices compression ratio (the resulting files are larger) in order to achieve speeds that push the physical limits of RAM bandwidth.
In big data and distributed systems, LZ4 is utilized when the primary goal is not saving disk space, but rather reducing network I/O or disk I/O without incurring any noticeable CPU penalty.
Diagram 1: Conceptual Architecture
Implementation and Operations
LZ4 is capable of decompression speeds exceeding multiple gigabytes per second per CPU core. This speed makes it virtually transparent to the operating system; it is often faster to read an LZ4-compressed file from a hard drive and decompress it in RAM than it is to read the uncompressed raw file from the hard drive, simply because the compressed file requires less physical disk I/O.
In the data engineering ecosystem, LZ4 is heavily used in transient, highly volatile systems:
- Apache Kafka: Kafka brokers use LZ4 to compress message batches. Because Kafka handles millions of messages per second, it cannot afford heavy CPU overhead. LZ4 shrinks the network payload instantly.
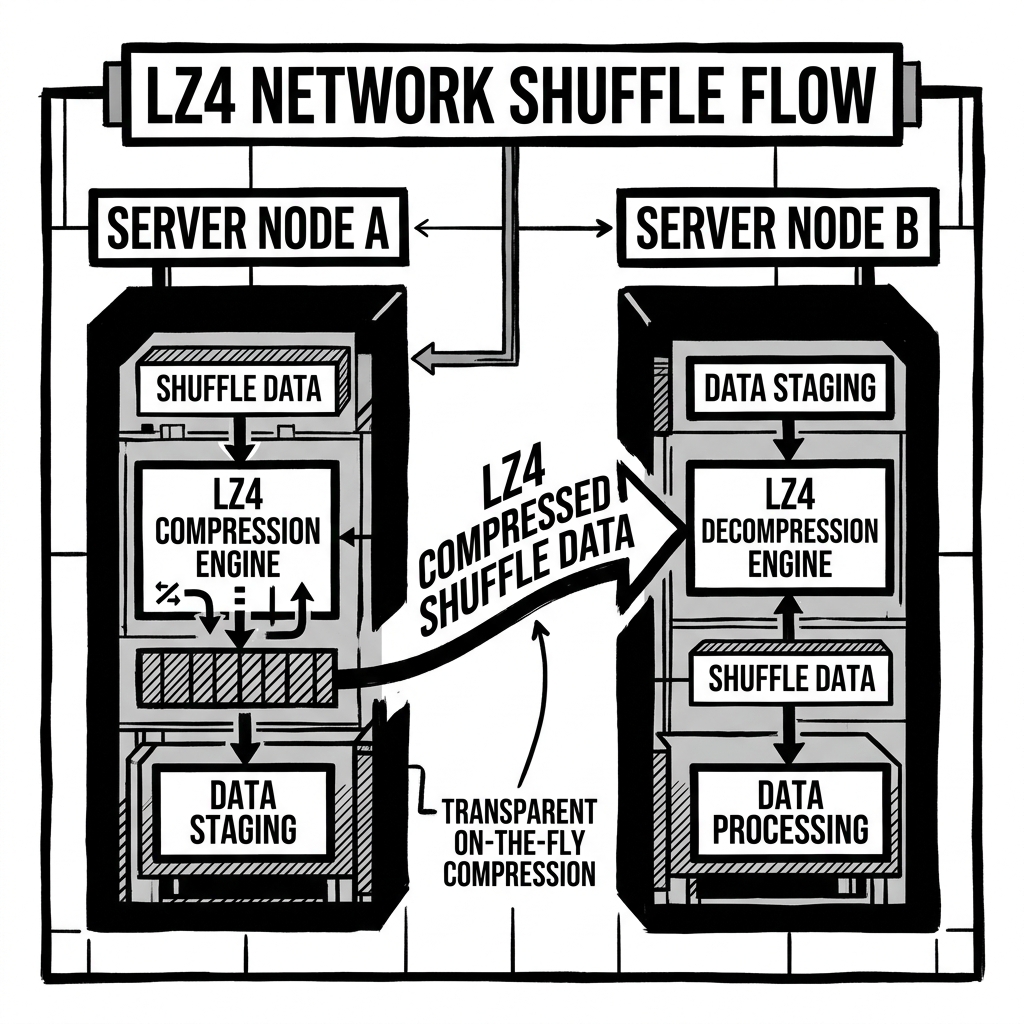
- Spark Shuffle Data: During a massive distributed
GROUP BYorJOIN, Apache Spark must “shuffle” terabytes of intermediate data between worker nodes over the network. Spark frequently uses LZ4 to compress this intermediate data on the fly. The compression is so fast it doesn’t slow down the computation, but it significantly reduces the amount of data traversing the network switches.
Diagram 2: Operational Flow
Summary and Tradeoffs
LZ4 is the ultimate tool for operational speed. The clear tradeoff is storage footprint. An LZ4 compressed file will be significantly larger than the same file compressed with Zstd or GZIP. Therefore, LZ4 is rarely used for long-term, persistent storage in the data lakehouse (where Zstd or Snappy are preferred for Parquet files). Instead, it is the invisible workhorse powering the high-speed network transfers and temporary disk spills that occur deep within the execution engines themselves.
Extended Deep Dive: The Data Engineering Ecosystem
To truly understand this concept, it must be placed within the broader context of the modern data engineering ecosystem. The evolution from traditional, monolithic on-premises data warehouses to decoupled, cloud-native open data lakehouses represents one of the most significant paradigm shifts in software architecture over the last two decades.
The Problem with Legacy Data Warehouses
Historically, organizations relied on proprietary appliances from vendors like Teradata, Oracle, or IBM. These systems were characterized by a tight coupling of compute and storage. The data physically resided on the hard drives of the specific servers that executed the SQL queries. While incredibly fast for structured, relational data, this architecture suffered from fatal scalability flaws. If an organization needed more storage for historical logs, they were forced to purchase expensive, proprietary servers that included compute power they did not actually need. Furthermore, these systems struggled to ingest unstructured data (like raw JSON, images, or massive IoT streams), creating impenetrable data silos.
The Rise and Fall of the Data Lake (Hadoop)
To solve the volume and variety problem, the industry pivoted to the Data Lake, pioneered by Apache Hadoop. Organizations began dumping all raw data—structured, semi-structured, and unstructured—into the Hadoop Distributed File System (HDFS). Because HDFS ran on cheap commodity hardware, storage became essentially free. However, the data lake lacked the basic governance, transactional guarantees, and performance optimization of the data warehouse. Without ACID (Atomicity, Consistency, Isolation, Durability) transactions, concurrent reads and writes frequently corrupted data. Without schema enforcement, the data lake quickly devolved into an unmanageable, unqueryable “data swamp.”
The Open Data Lakehouse Paradigm
The open data lakehouse merges the best of both worlds. It utilizes the infinitely scalable, low-cost storage of the cloud (like Amazon S3 or Google Cloud Storage) but overlays the management and performance features of a traditional data warehouse.
This is achieved through a multi-layered architecture:
- The Storage Layer: Cloud object storage provides the infinite hard drive.
- The File Format Layer: Open columnar formats like Apache Parquet and ORC provide extreme compression and analytical read efficiency.
- The Table Format Layer: Technologies like Apache Iceberg, Delta Lake, and Apache Hudi sit on top of the physical files. They provide the metadata layer that enables ACID transactions, schema evolution, and time travel, bringing warehouse-level reliability to the raw object storage.
- The Compute Layer: Decoupled, highly elastic engines like Trino, Dremio, Apache Spark, and Snowflake sit at the top. They can be scaled up or down independently of the storage, providing massive parallel processing power only when queries are actively running.
Performance Optimization Strategies
In this decoupled architecture, network bandwidth between the compute engine and the object storage is the primary bottleneck. Data engineers employ a variety of advanced strategies to minimize this I/O:
- Partitioning: Organizing data into distinct directories based on a frequently queried column (e.g., separating data by
year/month/day). When an analyst queries a specific date, the engine simply ignores all directories that do not match, massively reducing data reads. - Z-Ordering and Space-Filling Curves: Advanced sorting techniques that cluster multi-dimensional data physically close together on the disk. This dramatically improves the effectiveness of file-skipping statistics (Min/Max filtering) in formats like Iceberg, allowing engines to read highly targeted, microscopic subsets of massive tables.
- Compaction: Over time, streaming ingestions create millions of tiny, inefficient files. Data engineers run scheduled compaction jobs (often utilizing bin-packing algorithms) to merge these tiny files into optimally sized, large columnar blocks (typically 128MB to 512MB), restoring query performance and reducing S3 API overhead.
Security and Governance
As data is democratized across the enterprise, governance becomes paramount. The open lakehouse relies on centralized metadata catalogs (like AWS Glue, Apache Polaris, or Unity Catalog) to manage access. Fine-Grained Access Control (FGAC) allows administrators to mask specific columns (like Social Security Numbers) or restrict specific rows based on the user’s role, ensuring that a single, unified dataset can be securely queried by marketing, finance, and engineering teams simultaneously without violating compliance regulations like GDPR or CCPA.
Conclusion
The architecture described above is not static. The industry is rapidly moving toward real-time streaming ingestion, automated “agentic” data modeling, and universal cross-engine compatibility via projects like Apache XTable. Understanding the foundational layers—how data is serialized, compressed, stored, and transported—is the absolute prerequisite for architecting systems that can handle the exabyte-scale analytics demands of the future.
Extended Deep Dive: The Data Engineering Ecosystem
To truly understand this concept, it must be placed within the broader context of the modern data engineering ecosystem. The evolution from traditional, monolithic on-premises data warehouses to decoupled, cloud-native open data lakehouses represents one of the most significant paradigm shifts in software architecture over the last two decades.
The Problem with Legacy Data Warehouses
Historically, organizations relied on proprietary appliances from vendors like Teradata, Oracle, or IBM. These systems were characterized by a tight coupling of compute and storage. The data physically resided on the hard drives of the specific servers that executed the SQL queries. While incredibly fast for structured, relational data, this architecture suffered from fatal scalability flaws. If an organization needed more storage for historical logs, they were forced to purchase expensive, proprietary servers that included compute power they did not actually need. Furthermore, these systems struggled to ingest unstructured data (like raw JSON, images, or massive IoT streams), creating impenetrable data silos.
The Rise and Fall of the Data Lake (Hadoop)
To solve the volume and variety problem, the industry pivoted to the Data Lake, pioneered by Apache Hadoop. Organizations began dumping all raw data—structured, semi-structured, and unstructured—into the Hadoop Distributed File System (HDFS). Because HDFS ran on cheap commodity hardware, storage became essentially free. However, the data lake lacked the basic governance, transactional guarantees, and performance optimization of the data warehouse. Without ACID (Atomicity, Consistency, Isolation, Durability) transactions, concurrent reads and writes frequently corrupted data. Without schema enforcement, the data lake quickly devolved into an unmanageable, unqueryable “data swamp.”
The Open Data Lakehouse Paradigm
The open data lakehouse merges the best of both worlds. It utilizes the infinitely scalable, low-cost storage of the cloud (like Amazon S3 or Google Cloud Storage) but overlays the management and performance features of a traditional data warehouse.
This is achieved through a multi-layered architecture:
- The Storage Layer: Cloud object storage provides the infinite hard drive.
- The File Format Layer: Open columnar formats like Apache Parquet and ORC provide extreme compression and analytical read efficiency.
- The Table Format Layer: Technologies like Apache Iceberg, Delta Lake, and Apache Hudi sit on top of the physical files. They provide the metadata layer that enables ACID transactions, schema evolution, and time travel, bringing warehouse-level reliability to the raw object storage.
- The Compute Layer: Decoupled, highly elastic engines like Trino, Dremio, Apache Spark, and Snowflake sit at the top. They can be scaled up or down independently of the storage, providing massive parallel processing power only when queries are actively running.
Performance Optimization Strategies
In this decoupled architecture, network bandwidth between the compute engine and the object storage is the primary bottleneck. Data engineers employ a variety of advanced strategies to minimize this I/O:
- Partitioning: Organizing data into distinct directories based on a frequently queried column (e.g., separating data by
year/month/day). When an analyst queries a specific date, the engine simply ignores all directories that do not match, massively reducing data reads. - Z-Ordering and Space-Filling Curves: Advanced sorting techniques that cluster multi-dimensional data physically close together on the disk. This dramatically improves the effectiveness of file-skipping statistics (Min/Max filtering) in formats like Iceberg, allowing engines to read highly targeted, microscopic subsets of massive tables.
- Compaction: Over time, streaming ingestions create millions of tiny, inefficient files. Data engineers run scheduled compaction jobs (often utilizing bin-packing algorithms) to merge these tiny files into optimally sized, large columnar blocks (typically 128MB to 512MB), restoring query performance and reducing S3 API overhead.
Security and Governance
As data is democratized across the enterprise, governance becomes paramount. The open lakehouse relies on centralized metadata catalogs (like AWS Glue, Apache Polaris, or Unity Catalog) to manage access. Fine-Grained Access Control (FGAC) allows administrators to mask specific columns (like Social Security Numbers) or restrict specific rows based on the user’s role, ensuring that a single, unified dataset can be securely queried by marketing, finance, and engineering teams simultaneously without violating compliance regulations like GDPR or CCPA.
Conclusion
The architecture described above is not static. The industry is rapidly moving toward real-time streaming ingestion, automated “agentic” data modeling, and universal cross-engine compatibility via projects like Apache XTable. Understanding the foundational layers—how data is serialized, compressed, stored, and transported—is the absolute prerequisite for architecting systems that can handle the exabyte-scale analytics demands of the future.
Extended Deep Dive: The Data Engineering Ecosystem
To truly understand this concept, it must be placed within the broader context of the modern data engineering ecosystem. The evolution from traditional, monolithic on-premises data warehouses to decoupled, cloud-native open data lakehouses represents one of the most significant paradigm shifts in software architecture over the last two decades.
The Problem with Legacy Data Warehouses
Historically, organizations relied on proprietary appliances from vendors like Teradata, Oracle, or IBM. These systems were characterized by a tight coupling of compute and storage. The data physically resided on the hard drives of the specific servers that executed the SQL queries. While incredibly fast for structured, relational data, this architecture suffered from fatal scalability flaws. If an organization needed more storage for historical logs, they were forced to purchase expensive, proprietary servers that included compute power they did not actually need. Furthermore, these systems struggled to ingest unstructured data (like raw JSON, images, or massive IoT streams), creating impenetrable data silos.
The Rise and Fall of the Data Lake (Hadoop)
To solve the volume and variety problem, the industry pivoted to the Data Lake, pioneered by Apache Hadoop. Organizations began dumping all raw data—structured, semi-structured, and unstructured—into the Hadoop Distributed File System (HDFS). Because HDFS ran on cheap commodity hardware, storage became essentially free. However, the data lake lacked the basic governance, transactional guarantees, and performance optimization of the data warehouse. Without ACID (Atomicity, Consistency, Isolation, Durability) transactions, concurrent reads and writes frequently corrupted data. Without schema enforcement, the data lake quickly devolved into an unmanageable, unqueryable “data swamp.”
The Open Data Lakehouse Paradigm
The open data lakehouse merges the best of both worlds. It utilizes the infinitely scalable, low-cost storage of the cloud (like Amazon S3 or Google Cloud Storage) but overlays the management and performance features of a traditional data warehouse.
This is achieved through a multi-layered architecture:
- The Storage Layer: Cloud object storage provides the infinite hard drive.
- The File Format Layer: Open columnar formats like Apache Parquet and ORC provide extreme compression and analytical read efficiency.
- The Table Format Layer: Technologies like Apache Iceberg, Delta Lake, and Apache Hudi sit on top of the physical files. They provide the metadata layer that enables ACID transactions, schema evolution, and time travel, bringing warehouse-level reliability to the raw object storage.
- The Compute Layer: Decoupled, highly elastic engines like Trino, Dremio, Apache Spark, and Snowflake sit at the top. They can be scaled up or down independently of the storage, providing massive parallel processing power only when queries are actively running.
Performance Optimization Strategies
In this decoupled architecture, network bandwidth between the compute engine and the object storage is the primary bottleneck. Data engineers employ a variety of advanced strategies to minimize this I/O:
- Partitioning: Organizing data into distinct directories based on a frequently queried column (e.g., separating data by
year/month/day). When an analyst queries a specific date, the engine simply ignores all directories that do not match, massively reducing data reads. - Z-Ordering and Space-Filling Curves: Advanced sorting techniques that cluster multi-dimensional data physically close together on the disk. This dramatically improves the effectiveness of file-skipping statistics (Min/Max filtering) in formats like Iceberg, allowing engines to read highly targeted, microscopic subsets of massive tables.
- Compaction: Over time, streaming ingestions create millions of tiny, inefficient files. Data engineers run scheduled compaction jobs (often utilizing bin-packing algorithms) to merge these tiny files into optimally sized, large columnar blocks (typically 128MB to 512MB), restoring query performance and reducing S3 API overhead.
Security and Governance
As data is democratized across the enterprise, governance becomes paramount. The open lakehouse relies on centralized metadata catalogs (like AWS Glue, Apache Polaris, or Unity Catalog) to manage access. Fine-Grained Access Control (FGAC) allows administrators to mask specific columns (like Social Security Numbers) or restrict specific rows based on the user’s role, ensuring that a single, unified dataset can be securely queried by marketing, finance, and engineering teams simultaneously without violating compliance regulations like GDPR or CCPA.
Conclusion
The architecture described above is not static. The industry is rapidly moving toward real-time streaming ingestion, automated “agentic” data modeling, and universal cross-engine compatibility via projects like Apache XTable. Understanding the foundational layers—how data is serialized, compressed, stored, and transported—is the absolute prerequisite for architecting systems that can handle the exabyte-scale analytics demands of the future.
Extended Deep Dive: The Data Engineering Ecosystem
To truly understand this concept, it must be placed within the broader context of the modern data engineering ecosystem. The evolution from traditional, monolithic on-premises data warehouses to decoupled, cloud-native open data lakehouses represents one of the most significant paradigm shifts in software architecture over the last two decades.
The Problem with Legacy Data Warehouses
Historically, organizations relied on proprietary appliances from vendors like Teradata, Oracle, or IBM. These systems were characterized by a tight coupling of compute and storage. The data physically resided on the hard drives of the specific servers that executed the SQL queries. While incredibly fast for structured, relational data, this architecture suffered from fatal scalability flaws. If an organization needed more storage for historical logs, they were forced to purchase expensive, proprietary servers that included compute power they did not actually need. Furthermore, these systems struggled to ingest unstructured data (like raw JSON, images, or massive IoT streams), creating impenetrable data silos.
The Rise and Fall of the Data Lake (Hadoop)
To solve the volume and variety problem, the industry pivoted to the Data Lake, pioneered by Apache Hadoop. Organizations began dumping all raw data—structured, semi-structured, and unstructured—into the Hadoop Distributed File System (HDFS). Because HDFS ran on cheap commodity hardware, storage became essentially free. However, the data lake lacked the basic governance, transactional guarantees, and performance optimization of the data warehouse. Without ACID (Atomicity, Consistency, Isolation, Durability) transactions, concurrent reads and writes frequently corrupted data. Without schema enforcement, the data lake quickly devolved into an unmanageable, unqueryable “data swamp.”
The Open Data Lakehouse Paradigm
The open data lakehouse merges the best of both worlds. It utilizes the infinitely scalable, low-cost storage of the cloud (like Amazon S3 or Google Cloud Storage) but overlays the management and performance features of a traditional data warehouse.
This is achieved through a multi-layered architecture:
- The Storage Layer: Cloud object storage provides the infinite hard drive.
- The File Format Layer: Open columnar formats like Apache Parquet and ORC provide extreme compression and analytical read efficiency.
- The Table Format Layer: Technologies like Apache Iceberg, Delta Lake, and Apache Hudi sit on top of the physical files. They provide the metadata layer that enables ACID transactions, schema evolution, and time travel, bringing warehouse-level reliability to the raw object storage.
- The Compute Layer: Decoupled, highly elastic engines like Trino, Dremio, Apache Spark, and Snowflake sit at the top. They can be scaled up or down independently of the storage, providing massive parallel processing power only when queries are actively running.
Performance Optimization Strategies
In this decoupled architecture, network bandwidth between the compute engine and the object storage is the primary bottleneck. Data engineers employ a variety of advanced strategies to minimize this I/O:
- Partitioning: Organizing data into distinct directories based on a frequently queried column (e.g., separating data by
year/month/day). When an analyst queries a specific date, the engine simply ignores all directories that do not match, massively reducing data reads. - Z-Ordering and Space-Filling Curves: Advanced sorting techniques that cluster multi-dimensional data physically close together on the disk. This dramatically improves the effectiveness of file-skipping statistics (Min/Max filtering) in formats like Iceberg, allowing engines to read highly targeted, microscopic subsets of massive tables.
- Compaction: Over time, streaming ingestions create millions of tiny, inefficient files. Data engineers run scheduled compaction jobs (often utilizing bin-packing algorithms) to merge these tiny files into optimally sized, large columnar blocks (typically 128MB to 512MB), restoring query performance and reducing S3 API overhead.
Security and Governance
As data is democratized across the enterprise, governance becomes paramount. The open lakehouse relies on centralized metadata catalogs (like AWS Glue, Apache Polaris, or Unity Catalog) to manage access. Fine-Grained Access Control (FGAC) allows administrators to mask specific columns (like Social Security Numbers) or restrict specific rows based on the user’s role, ensuring that a single, unified dataset can be securely queried by marketing, finance, and engineering teams simultaneously without violating compliance regulations like GDPR or CCPA.
Conclusion
The architecture described above is not static. The industry is rapidly moving toward real-time streaming ingestion, automated “agentic” data modeling, and universal cross-engine compatibility via projects like Apache XTable. Understanding the foundational layers—how data is serialized, compressed, stored, and transported—is the absolute prerequisite for architecting systems that can handle the exabyte-scale analytics demands of the future.
Visual Architecture