Manifest File
In the Apache Iceberg metadata hierarchy, the Manifest File is the critical layer sitting directly above the raw data. If the Manifest List acts as a high-level index of partitions, the Manifest File acts as the granular, highly detailed index of the physical files themselves.
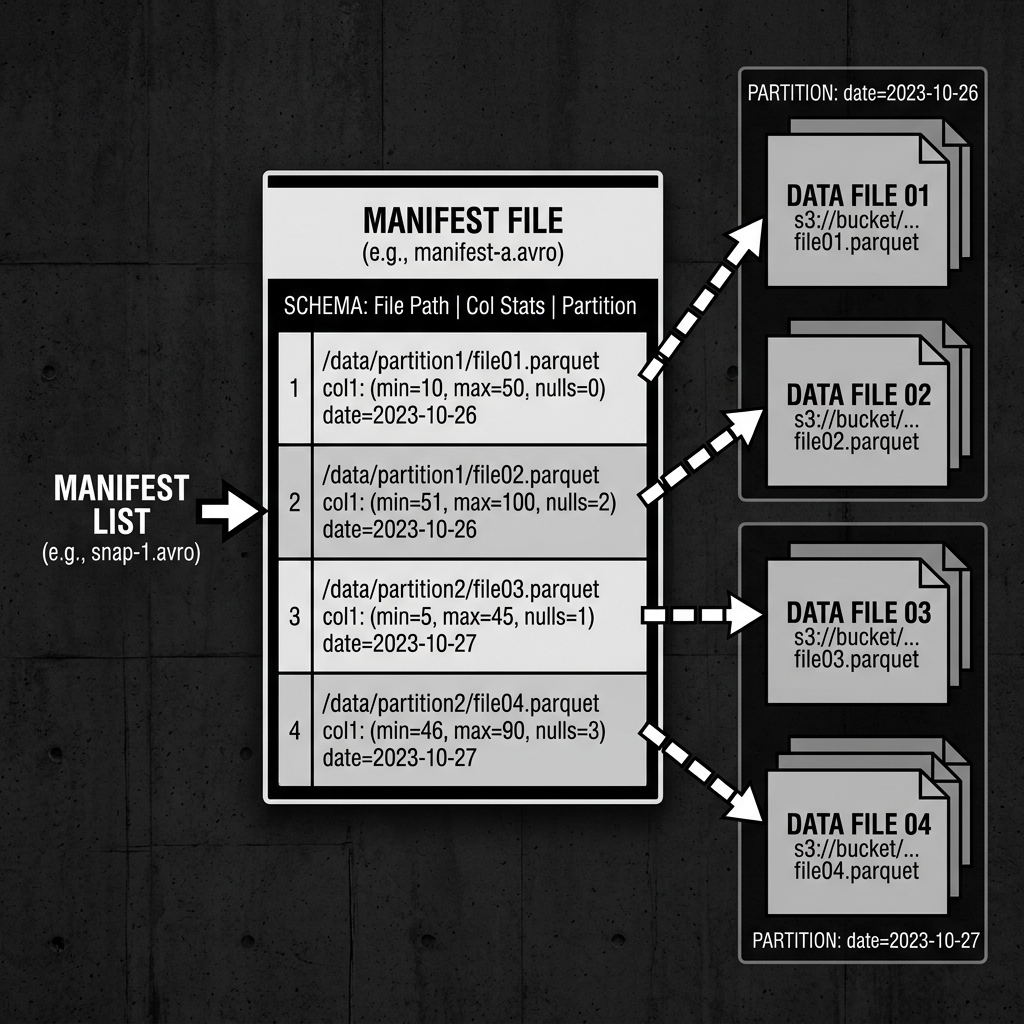
A Manifest File is an immutable Avro file. Its primary responsibility is to keep an exact inventory of a subset of the data files (usually Parquet or ORC) that make up a table. However, it does much more than simply list file paths. It stores a wealth of statistical metadata about the contents of those data files, which query engines leverage to achieve massive performance gains.
What is Inside a Manifest File?
A Manifest File contains an array of rows, where each row corresponds to one physical data file in object storage. For every data file, the Manifest File records:
- File Path: The absolute URI (e.g.,
s3://bucket/data/file1.parquet). - File Format: The format of the file (Parquet, ORC, Avro).
- Partition Data: The specific partition values the file belongs to (e.g.,
date=2026-05-18). - Record Count: The total number of rows inside the data file.
- Column-Level Statistics: For every column in the table, the manifest records the minimum value, the maximum value, and the total count of null values present in that specific data file.
Diagram 1: Manifest File Architecture
Column-Level Data Skipping
The inclusion of column-level statistics is what gives Iceberg its signature query speed.
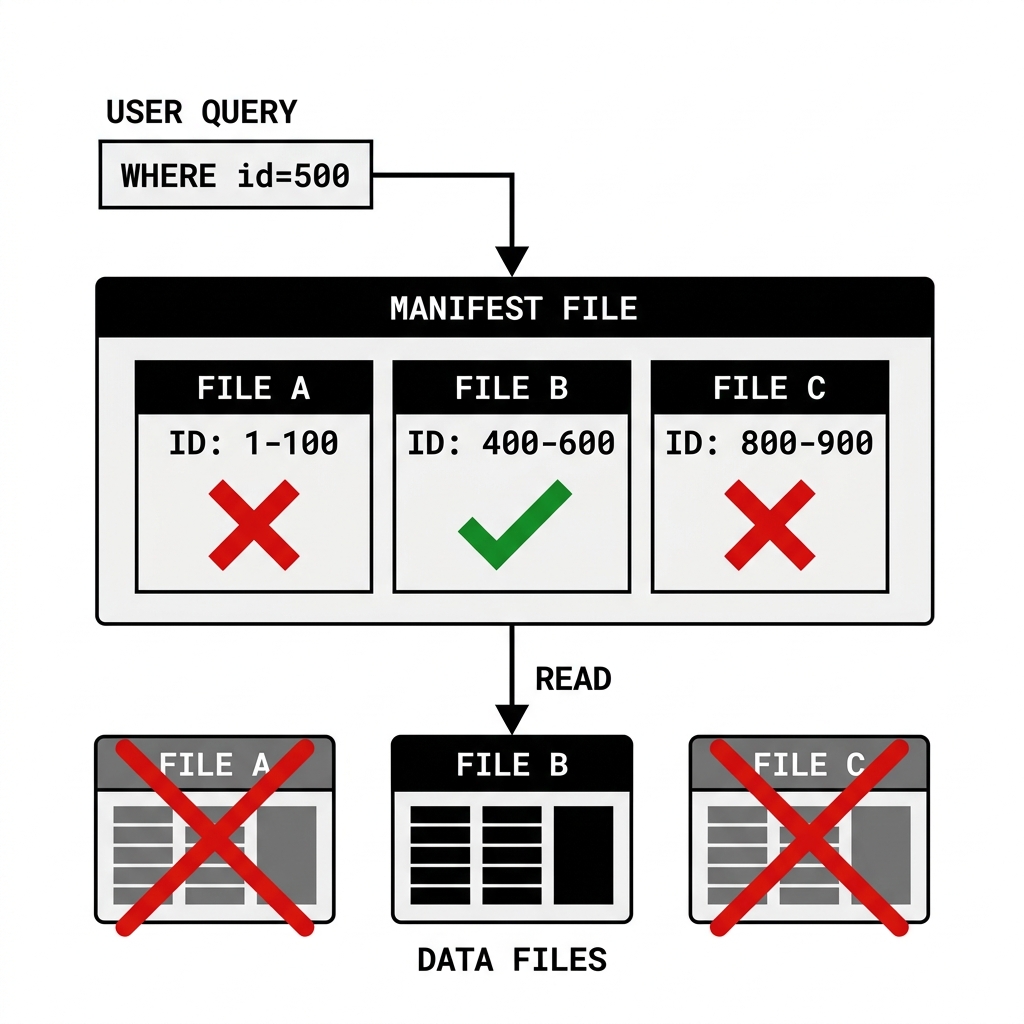
Consider a query that searches for a specific customer:
SELECT * FROM users WHERE user_id = 500;During query planning, the engine evaluates the Manifest List and determines which Manifest Files might contain relevant data. The engine then downloads those Manifest Files and evaluates their contents in memory.
The engine looks at the row for fileA.parquet. The column stats indicate that the minimum user_id in this file is 1 and the maximum is 100. Because 500 is outside this range, the engine knows with absolute certainty that fileA.parquet does not contain the requested record. It completely skips the file.
The engine looks at fileB.parquet. The stats show a minimum of 400 and a maximum of 600. Because 500 falls within this range, the file might contain the record. The engine flags this file to be downloaded and scanned.
By evaluating these min/max statistics across thousands of files in milliseconds, the query engine can prune away the vast majority of the physical data files before initiating any heavy I/O operations against the object storage layer.
Diagram 2: Manifest File Data Skipping
Immutability and Write Amplification
Manifest Files are immutable. Once written, they are never modified.
If a job deletes a single row of data from fileB.parquet, the engine cannot simply open the existing Manifest File and cross it out. Instead, the engine creates a completely new Manifest File. This new Manifest File records the exact same list of data files, but marks fileB.parquet with a status of DELETED (or replaces it with a new data file if it was rewritten).
This immutability guarantees transactional safety. If a query is currently reading the old Manifest File, it continues to read it undisturbed, seeing the state of the table exactly as it was when the query started.
To prevent the number of Manifest Files from growing infinitely (which would slow down query planning), Iceberg uses a background process called Manifest Compaction. Periodically, Iceberg will read several small Manifest Files and combine their contents into a single, larger Manifest File, optimizing the metadata tree for future queries.